 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Extra Modality Helps Segmentor Find Camouflaged Objects Well
Feb 20, 2025Camouflaged Object Segmentation (COS) remains a challenging problem due to the subtle visual differences between camouflaged objects and backgrounds. Owing to the exceedingly limited visual cues available from visible spectrum, previous RGB single-modality approaches often struggle to achieve satisfactory results, prompting the exploration of multimodal data to enhance detection accuracy. In this work, we present UniCOS, a novel framework that effectively leverages diverse data modalities to improve segmentation performance. UniCOS comprises two key components: a multimodal segmentor, UniSEG, and a cross-modal knowledge learning module, UniLearner. UniSEG employs a state space fusion mechanism to integrate cross-modal features within a unified state space, enhancing contextual understanding and improving robustness to integration of heterogeneous data. Additionally, it includes a fusion-feedback mechanism that facilitate feature extraction. UniLearner exploits multimodal data unrelated to the COS task to improve the segmentation ability of the COS models by generating pseudo-modal content and cross-modal semantic associations. Extensive experiments demonstrate that UniSEG outperforms existing Multimodal COS (MCOS) segmentors, regardless of whether real or pseudo-multimodal COS data is available. Moreover, in scenarios where multimodal COS data is unavailable but multimodal non-COS data is accessible, UniLearner effectively exploits these data to enhance segmentation performance. Our code will be made publicly available on \href{https://github.com/cnyvfang/UniCOS}{GitHub}.
HQG-Net: Unpaired Medical Image Enhancement with High-Quality Guidance
Jul 15, 2023
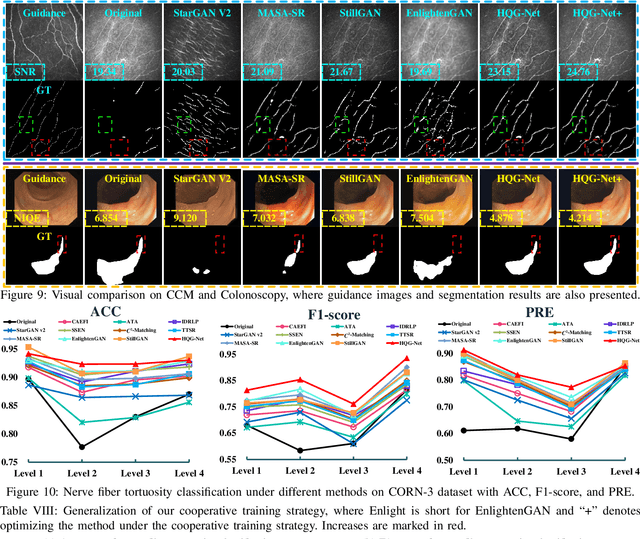

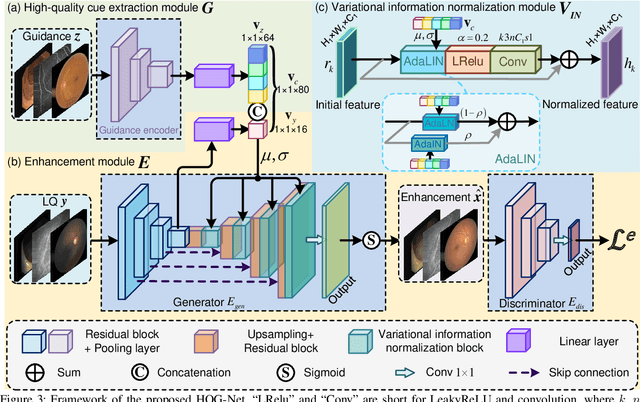
Unpaired Medical Image Enhancement (UMIE) aims to transform a low-quality (LQ) medical image into a high-quality (HQ) one without relying on paired images for training. While most existing approaches are based on Pix2Pix/CycleGAN and are effective to some extent, they fail to explicitly use HQ information to guide the enhancement process, which can lead to undesired artifacts and structural distortions. In this paper, we propose a novel UMIE approach that avoids the above limitation of existing methods by directly encoding HQ cues into the LQ enhancement process in a variational fashion and thus model the UMIE task under the joint distribution between the LQ and HQ domains. Specifically, we extract features from an HQ image and explicitly insert the features, which are expected to encode HQ cues, into the enhancement network to guide the LQ enhancement with the variational normalization module. We train the enhancement network adversarially with a discriminator to ensure the generated HQ image falls into the HQ domain. We further propose a content-aware loss to guide the enhancement process with wavelet-based pixel-level and multi-encoder-based feature-level constraints. Additionally, as a key motivation for performing image enhancement is to make the enhanced images serve better for downstream tasks, we propose a bi-level learning scheme to optimize the UMIE task and downstream tasks cooperatively, helping generate HQ images both visually appealing and favorable for downstream tasks. Experiments on three medical datasets, including two newly collected datasets, verify that the proposed method outperforms existing techniques in terms of both enhancement quality and downstream task performance. We will make the code and the newly collected datasets publicly available for community study.
Weakly-Supervised Concealed Object Segmentation with SAM-based Pseudo Labeling and Multi-scale Feature Grouping
May 18, 2023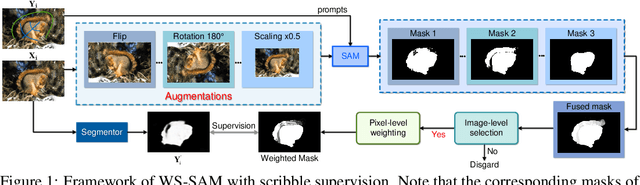


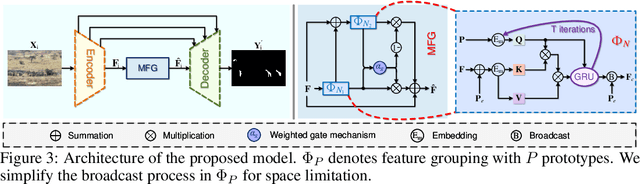
Weakly-Supervised Concealed Object Segmentation (WSCOS) aims to segment objects well blended with surrounding environments using sparsely-annotated data for model training. It remains a challenging task since (1) it is hard to distinguish concealed objects from the background due to the intrinsic similarity and (2) the sparsely-annotated training data only provide weak supervision for model learning. In this paper, we propose a new WSCOS method to address these two challenges. To tackle the intrinsic similarity challenge, we design a multi-scale feature grouping module that first groups features at different granularities and then aggregates these grouping results. By grouping similar features together, it encourages segmentation coherence, helping obtain complete segmentation results for both single and multiple-object images. For the weak supervision challenge, we utilize the recently-proposed vision foundation model, Segment Anything Model (SAM), and use the provided sparse annotations as prompts to generate segmentation masks, which are used to train the model. To alleviate the impact of low-quality segmentation masks, we further propose a series of strategies, including multi-augmentation result ensemble, entropy-based pixel-level weighting, and entropy-based image-level selection. These strategies help provide more reliable supervision to train the segmentation model. We verify the effectiveness of our method on various WSCOS tasks, and experiments demonstrate that our method achieves state-of-the-art performance on these tasks.