 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqMark: Invisible Image Watermarking via Frequency Based Optimization in Latent Space
Oct 28, 2024Invisible watermarking is essential for safeguarding digital content, enabling copyright protection and content authentication. However, existing watermarking methods fall short in robustness against regeneration attacks. In this paper, we propose a novel method called FreqMark that involves unconstrained optimization of the image latent frequency space obtained after VAE encoding. Specifically, FreqMark embeds the watermark by optimizing the latent frequency space of the images and then extracts the watermark through a pre-trained image encoder. This optimization allows a flexible trade-off between image quality with watermark robustness and effectively resists regeneration attacks. Experimental results demonstrate that FreqMark offers significant advantages in image quality and robustness, permits flexible selection of the encoding bit number, and achieves a bit accuracy exceeding 90% when encoding a 48-bit hidden message under various attack scenarios.
ADFF: Attention Based Deep Feature Fusion Approach for Music Emotion Recognition
Apr 12, 2022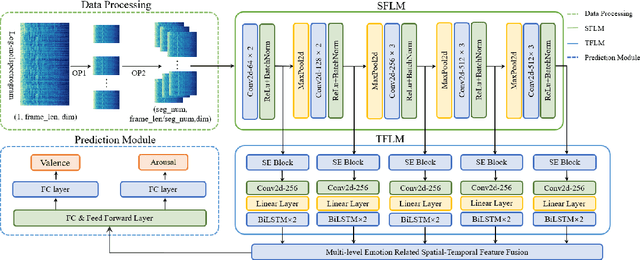
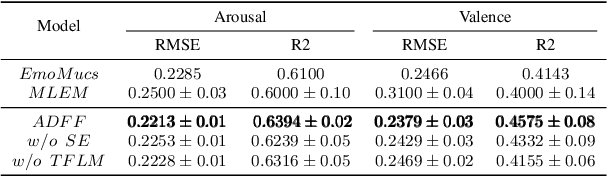
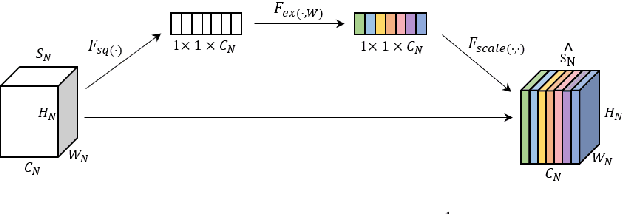

Music emotion recognition (MER), a sub-task of music information retrieval (MIR), has developed rapidly in recent years. However, the learning of affect-salient features remains a challenge. In this paper, we propose an end-to-end attention-based deep feature fusion (ADFF) approach for MER. Only taking log Mel-spectrogram as input, this method uses adapted VGGNet as spatial feature learning module (SFLM) to obtain spatial features across different levels. Then, these features are fed into squeeze-and-excitation (SE) attention-based temporal feature learning module (TFLM) to get multi-level emotion-related spatial-temporal features (ESTFs), which can discriminate emotions well in the final emotion space. In addition, a novel data processing is devised to cut the single-channel input into multi-channel to improve calculative efficiency while ensuring the quality of MER. Experiments show that our proposed method achieves 10.43% and 4.82% relative improvement of valence and arousal respectively on the R2 score compared to the state-of-the-art model, meanwhile, performs better on datasets with distinct scales and in multi-task learning.