Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Advantage Weighting for Offline RL
Paper and Code
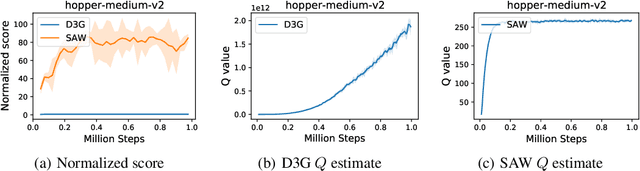
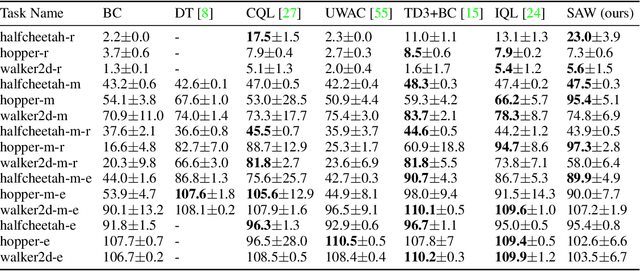

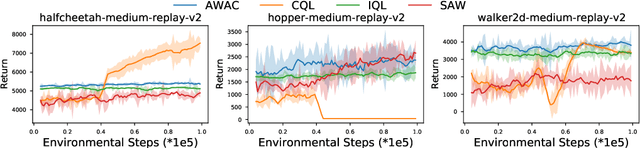
We present state advantage weighting for offline reinforcement learning (RL). In contrast to action advantage $A(s,a)$ that we commonly adopt in QSA learning, we leverage state advantage $A(s,s^\prime)$ and QSS learning for offline RL, hence decoupling the action from values. We expect the agent can get to the high-reward state and the action is determined by how the agent can get to that corresponding state. Experiments on D4RL datasets show that our proposed method can achieve remarkable performance against the common baselines. Furthermore, our method shows good generalization capability when transferring from offline to online.
View paper on
 OpenReview
OpenReview