 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding What Affects Generalization Gap in Visual Reinforcement Learning: Theory and Empirical Evidence
Paper and Code
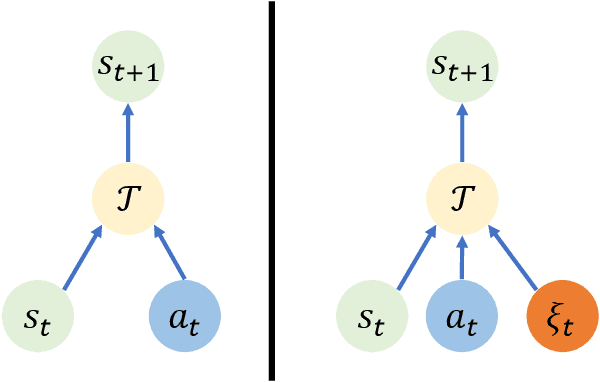


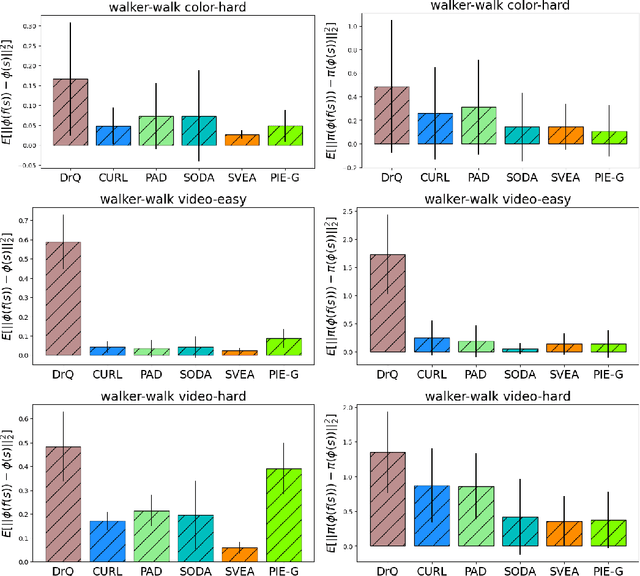
Recently, there are many efforts attempting to learn useful policies for continuous control in visual reinforcement learning (RL). In this scenario, it is important to learn a generalizable policy, as the testing environment may differ from the training environment, e.g., there exist distractors during deployment. Many practical algorithms are proposed to handle this problem. However, to the best of our knowledge, none of them provide a theoretical understanding of what affects the generalization gap and why their proposed methods work. In this paper, we bridge this issue by theoretically answering the key factors that contribute to the generalization gap when the testing environment has distractors. Our theories indicate that minimizing the representation distance between training and testing environments, which aligns with human intuition, is the most critical for the benefit of reducing the generalization gap. Our theoretical results are supported by the empirical evidence in the DMControl Generalization Benchmark (DMC-GB).