 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory-Adapter: A Training-free Iterative Framework for Long Story Visualization
Oct 08, 2024



Story visualization, the task of generating coherent images based on a narrative, has seen significant advancements with the emergence of text-to-image models, particularly diffusion models. However, maintaining semantic consistency, generating high-quality fine-grained interactions, and ensuring computational feasibility remain challenging, especially in long story visualization (i.e., up to 100 frames). In this work, we propose a training-free and computationally efficient framework, termed Story-Adapter, to enhance the generative capability of long stories. Specifically, we propose an iterative paradigm to refine each generated image, leveraging both the text prompt and all generated images from the previous iteration. Central to our framework is a training-free global reference cross-attention module, which aggregates all generated images from the previous iteration to preserve semantic consistency across the entire story, while minimizing computational costs with global embeddings. This iterative process progressively optimizes image generation by repeatedly incorporating text constraints, resulting in more precise and fine-grained interactions. Extensive experiments validate the superiority of Story-Adapter in improving both semantic consistency and generative capability for fine-grained interactions, particularly in long story scenarios. The project page and associated code can be accessed via https://jwmao1.github.io/storyadapter .
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 15, 2023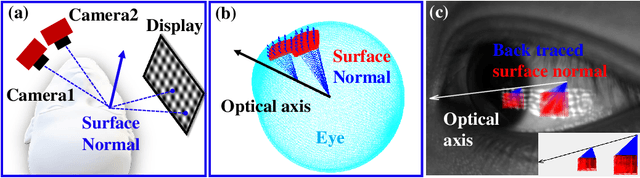

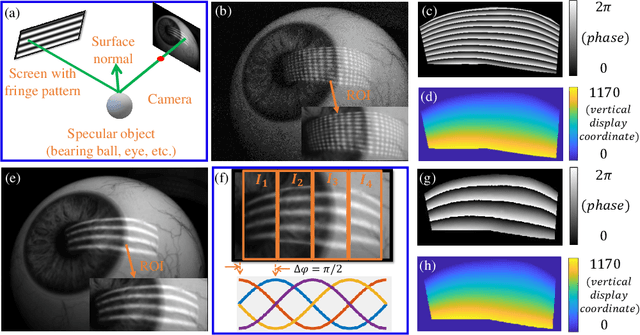
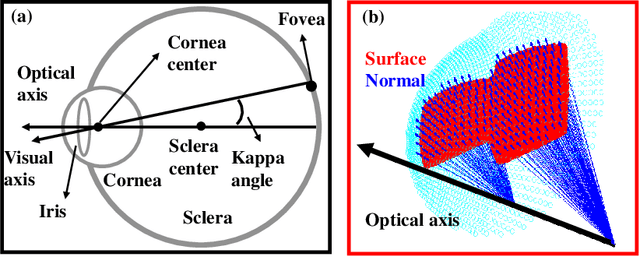
Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.
SkinScan: Low-Cost 3D-Scanning for Dermatologic Diagnosis and Documentation
Jan 31, 2021
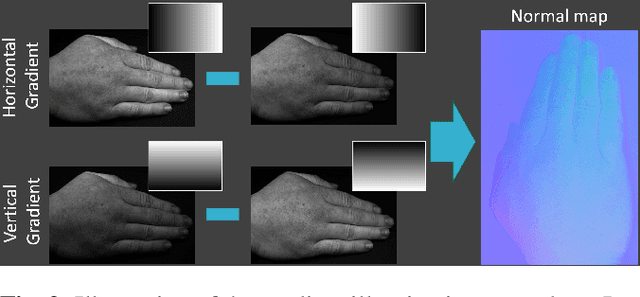
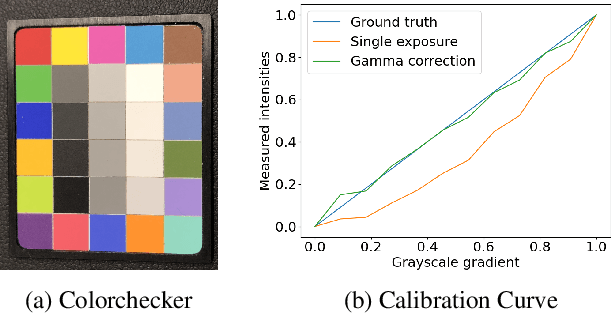

The utilization of computational photography becomes increasingly essential in the medical field. Today, imaging techniques for dermatology range from two-dimensional (2D) color imagery with a mobile device to professional clinical imaging systems measuring additional detailed three-dimensional (3D) data. The latter are commonly expensive and not accessible to a broad audience. In this work, we propose a novel system and software framework that relies only on low-cost (and even mobile) commodity devices present in every household to measure detailed 3D information of the human skin with a 3D-gradient-illumination-based method. We believe that our system has great potential for early-stage diagnosis and monitoring of skin diseases, especially in vastly populated or underdeveloped areas.
Interact as You Intend: Intention-Driven Human-Object Interaction Detection
Aug 29, 2018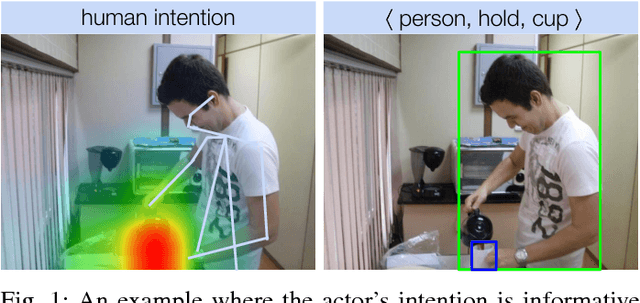
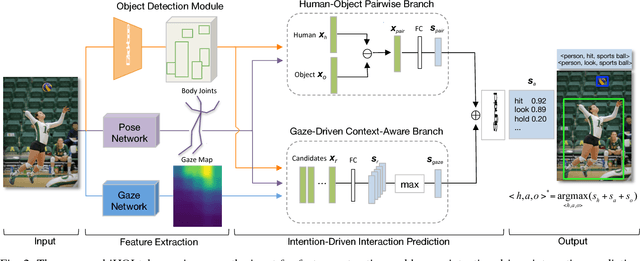
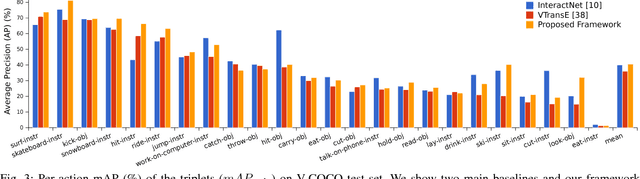

The recent advances in instance-level detection tasks lay strong foundation for genuine comprehension of the visual scenes. However, the ability to fully comprehend a social scene is still in its preliminary stage. In this work, we focus on detecting human-object interactions (HOIs) in social scene images, which is demanding in terms of research and increasingly useful for practical applications. To undertake social tasks interacting with objects, humans direct their attention and move their body based on their intention. Based on this observation, we provide a unique computational perspective to explore human intention in HOI detection. Specifically, the proposed human intention- driven HOI detection (iHOI) framework models human pose with the relative distances from body joints to the object instances. It also utilizes human gaze to guide the attended contextual regions in a weakly-supervised setting. In addition, we propose a hard negative sampling strategy to address the problem of mis-grouping. We perform extensive experiments on two benchmark datasets, namely V-COCO and HICO-DET, and show that iHOI outperforms the existing approaches. The efficacy of each proposed component has also been validated.