 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Predict Trustworthiness with Steep Slope Loss
Sep 30, 2021
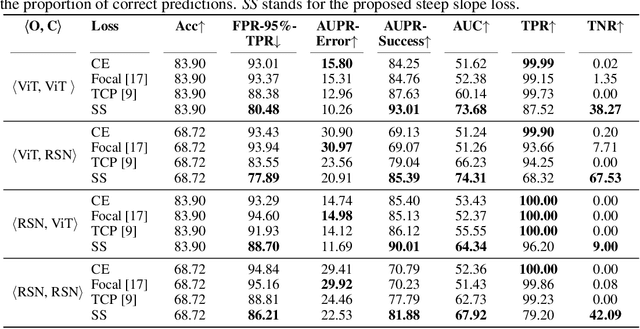
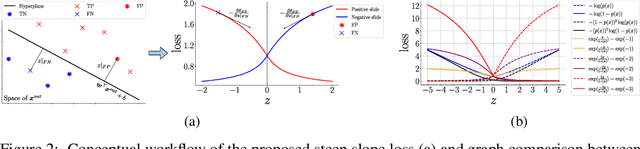
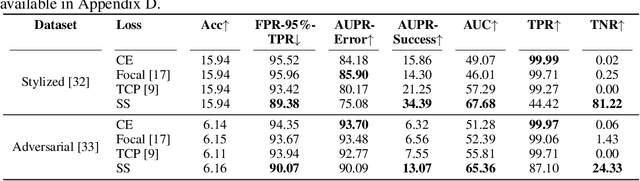
Understanding the trustworthiness of a prediction yielded by a classifier is critical for the safe and effective use of AI models. Prior efforts have been proven to be reliable on small-scale datasets. In this work, we study the problem of predicting trustworthiness on real-world large-scale datasets, where the task is more challenging due to high-dimensional features, diverse visual concepts, and large-scale samples. In such a setting, we observe that the trustworthiness predictors trained with prior-art loss functions, i.e., the cross entropy loss, focal loss, and true class probability confidence loss, are prone to view both correct predictions and incorrect predictions to be trustworthy. The reasons are two-fold. Firstly, correct predictions are generally dominant over incorrect predictions. Secondly, due to the data complexity, it is challenging to differentiate the incorrect predictions from the correct ones on real-world large-scale datasets. To improve the generalizability of trustworthiness predictors, we propose a novel steep slope loss to separate the features w.r.t. correct predictions from the ones w.r.t. incorrect predictions by two slide-like curves that oppose each other. The proposed loss is evaluated with two representative deep learning models, i.e., Vision Transformer and ResNet, as trustworthiness predictors. We conduct comprehensive experiments and analyses on ImageNet, which show that the proposed loss effectively improves the generalizability of trustworthiness predictors. The code and pre-trained trustworthiness predictors for reproducibility are available at https://github.com/luoyan407/predict_trustworthiness.
$n$-Reference Transfer Learning for Saliency Prediction
Jul 09, 2020
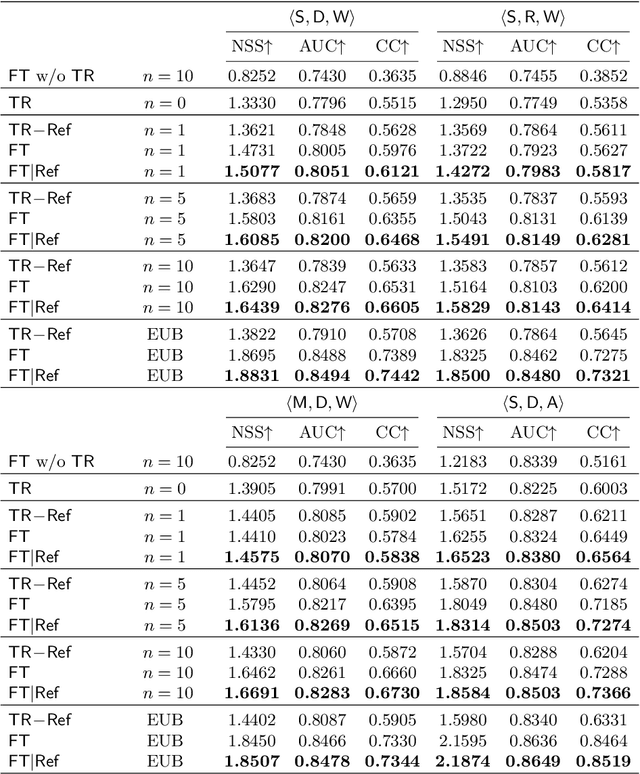


Benefiting from deep learning research and large-scale datasets, saliency prediction has achieved significant success in the past decade. However, it still remains challenging to predict saliency maps on images in new domains that lack sufficient data for data-hungry models. To solve this problem, we propose a few-shot transfer learning paradigm for saliency prediction, which enables efficient transfer of knowledge learned from the existing large-scale saliency datasets to a target domain with limited labeled examples. Specifically, very few target domain examples are used as the reference to train a model with a source domain dataset such that the training process can converge to a local minimum in favor of the target domain. Then, the learned model is further fine-tuned with the reference. The proposed framework is gradient-based and model-agnostic. We conduct comprehensive experiments and ablation study on various source domain and target domain pairs. The results show that the proposed framework achieves a significant performance improvement. The code is publicly available at \url{https://github.com/luoyan407/n-reference}.
Direction Concentration Learning: Enhancing Congruency in Machine Learning
Jan 02, 2020
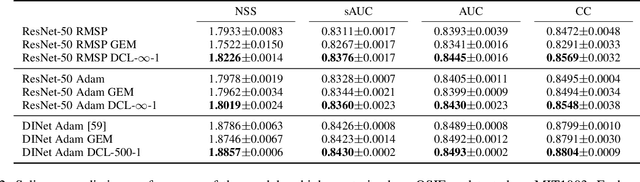
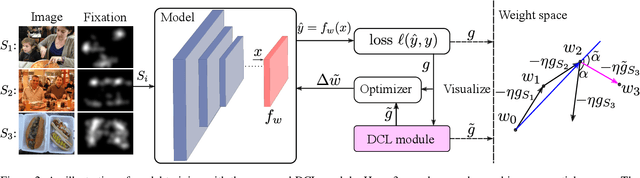
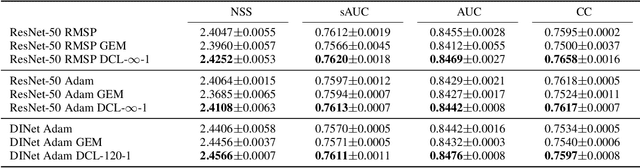
One of the well-known challenges in computer vision tasks is the visual diversity of images, which could result in an agreement or disagreement between the learned knowledge and the visual content exhibited by the current observation. In this work, we first define such an agreement in a concepts learning process as congruency. Formally, given a particular task and sufficiently large dataset, the congruency issue occurs in the learning process whereby the task-specific semantics in the training data are highly varying. We propose a Direction Concentration Learning (DCL) method to improve congruency in the learning process, where enhancing congruency influences the convergence path to be less circuitous. The experimental results show that the proposed DCL method generalizes to state-of-the-art models and optimizers, as well as improves the performances of saliency prediction task, continual learning task, and classification task. Moreover, it helps mitigate the catastrophic forgetting problem in the continual learning task. The code is publicly available at https://github.com/luoyan407/congruency.
* This is a preprint and the formal version has been published in TPAMI
Visual Social Relationship Recognition
Dec 13, 2018



Social relationships form the basis of social structure of humans. Developing computational models to understand social relationships from visual data is essential for building intelligent machines that can better interact with humans in a social environment. In this work, we study the problem of visual social relationship recognition in images. We propose a Dual-Glance model for social relationship recognition, where the first glance fixates at the person of interest and the second glance deploys attention mechanism to exploit contextual cues. To enable this study, we curated a large scale People in Social Context (PISC) dataset, which comprises of 23,311 images and 79,244 person pairs with annotated social relationships. Since visually identifying social relationship bears certain degree of uncertainty, we further propose an Adaptive Focal Loss to leverage the ambiguous annotations for more effective learning. We conduct extensive experiments to quantitatively and qualitatively demonstrate the efficacy of our proposed method, which yields state-of-the-art performance on social relationship recognition.
Unsupervised Learning of View-invariant Action Representations
Sep 06, 2018



The recent success in human action recognition with deep learning methods mostly adopt the supervised learning paradigm, which requires significant amount of manually labeled data to achieve good performance. However, label collection is an expensive and time-consuming process. In this work, we propose an unsupervised learning framework, which exploits unlabeled data to learn video representations. Different from previous works in video representation learning, our unsupervised learning task is to predict 3D motion in multiple target views using video representation from a source view. By learning to extrapolate cross-view motions, the representation can capture view-invariant motion dynamics which is discriminative for the action. In addition, we propose a view-adversarial training method to enhance learning of view-invariant features. We demonstrate the effectiveness of the learned representations for action recognition on multiple datasets.
Interact as You Intend: Intention-Driven Human-Object Interaction Detection
Aug 29, 2018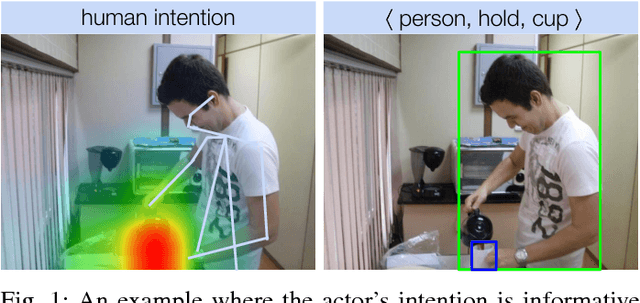
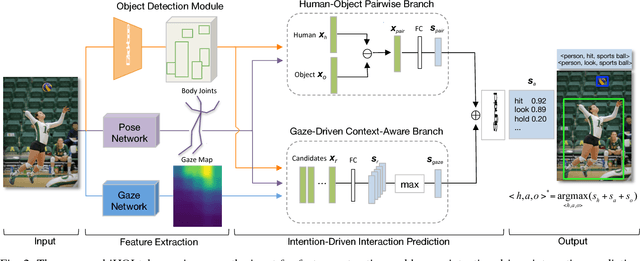
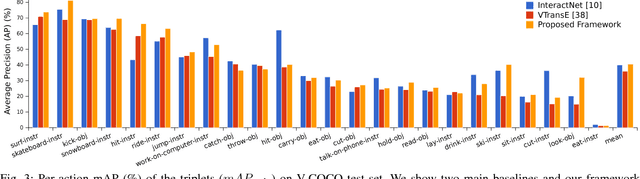

The recent advances in instance-level detection tasks lay strong foundation for genuine comprehension of the visual scenes. However, the ability to fully comprehend a social scene is still in its preliminary stage. In this work, we focus on detecting human-object interactions (HOIs) in social scene images, which is demanding in terms of research and increasingly useful for practical applications. To undertake social tasks interacting with objects, humans direct their attention and move their body based on their intention. Based on this observation, we provide a unique computational perspective to explore human intention in HOI detection. Specifically, the proposed human intention- driven HOI detection (iHOI) framework models human pose with the relative distances from body joints to the object instances. It also utilizes human gaze to guide the attended contextual regions in a weakly-supervised setting. In addition, we propose a hard negative sampling strategy to address the problem of mis-grouping. We perform extensive experiments on two benchmark datasets, namely V-COCO and HICO-DET, and show that iHOI outperforms the existing approaches. The efficacy of each proposed component has also been validated.
Video Storytelling
Jul 25, 2018
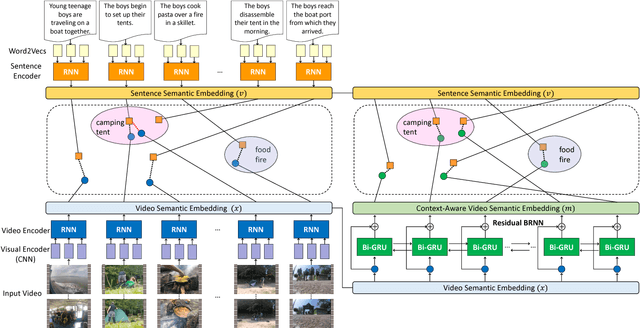
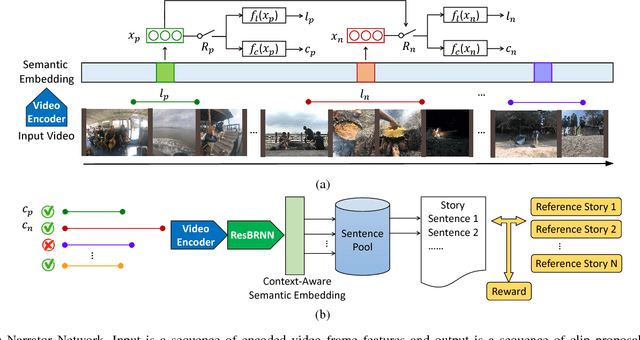

Bridging vision and natural language is a longstanding goal in computer vision and multimedia research. While earlier works focus on generating a single-sentence description for visual content, recent works have studied paragraph generation. In this work, we introduce the problem of video storytelling, which aims at generating coherent and succinct stories for long videos. Video storytelling introduces new challenges, mainly due to the diversity of the story and the length and complexity of the video. We propose novel methods to address the challenges. First, we propose a context-aware framework for multimodal embedding learning, where we design a Residual Bidirectional Recurrent Neural Network to leverage contextual information from past and future. Second, we propose a Narrator model to discover the underlying storyline. The Narrator is formulated as a reinforcement learning agent which is trained by directly optimizing the textual metric of the generated story. We evaluate our method on the Video Story dataset, a new dataset that we have collected to enable the study. We compare our method with multiple state-of-the-art baselines, and show that our method achieves better performance, in terms of quantitative measures and user study.
Dual-Glance Model for Deciphering Social Relationships
Aug 02, 2017

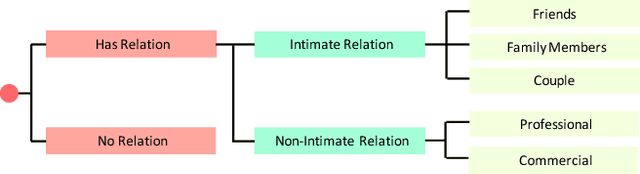

Since the beginning of early civilizations, social relationships derived from each individual fundamentally form the basis of social structure in our daily life. In the computer vision literature, much progress has been made in scene understanding, such as object detection and scene parsing. Recent research focuses on the relationship between objects based on its functionality and geometrical relations. In this work, we aim to study the problem of social relationship recognition, in still images. We have proposed a dual-glance model for social relationship recognition, where the first glance fixates at the individual pair of interest and the second glance deploys attention mechanism to explore contextual cues. We have also collected a new large scale People in Social Context (PISC) dataset, which comprises of 22,670 images and 76,568 annotated samples from 9 types of social relationship. We provide benchmark results on the PISC dataset, and qualitatively demonstrate the efficacy of the proposed model.