 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Storytelling
Paper and Code
Jul 25, 2018
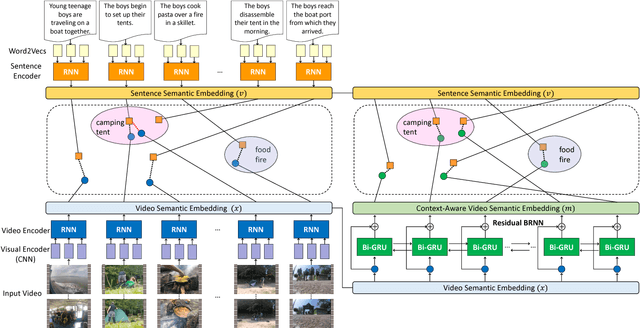
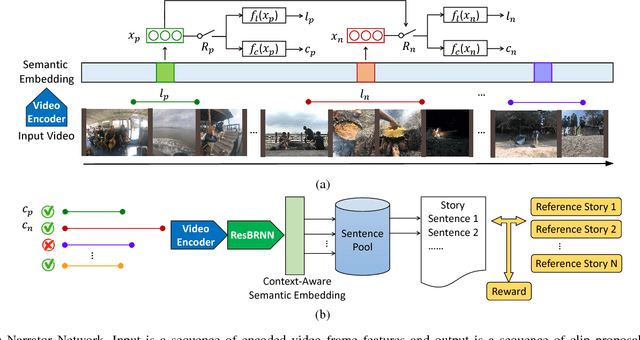

Bridging vision and natural language is a longstanding goal in computer vision and multimedia research. While earlier works focus on generating a single-sentence description for visual content, recent works have studied paragraph generation. In this work, we introduce the problem of video storytelling, which aims at generating coherent and succinct stories for long videos. Video storytelling introduces new challenges, mainly due to the diversity of the story and the length and complexity of the video. We propose novel methods to address the challenges. First, we propose a context-aware framework for multimodal embedding learning, where we design a Residual Bidirectional Recurrent Neural Network to leverage contextual information from past and future. Second, we propose a Narrator model to discover the underlying storyline. The Narrator is formulated as a reinforcement learning agent which is trained by directly optimizing the textual metric of the generated story. We evaluate our method on the Video Story dataset, a new dataset that we have collected to enable the study. We compare our method with multiple state-of-the-art baselines, and show that our method achieves better performance, in terms of quantitative measures and user study.