 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2Motion: Text-driven 2D Sketch to 3D Animation via Diffusion-guided Skeleton Optimization
May 27, 2026Animation of 2D hand-drawn sketches provides an effective medium for visual communication. However, these sketches pose challenges, particularly in handling occlusions and accurately mapping motion. While 3D animation naturally addresses these challenges, estimating 3D motion remains a very complex task. Recent approaches to converting 2D sketches to 3D animations have mainly focused on specific types of motion, such as bipedal movements and facial expressions. We propose Sketch2Motion, a diffusion-guided framework for skeleton-based motion synthesis that combines classical character animation pipelines with deep generative priors. Our method represents motion using skeletal transformations, which are propagated to mesh deformations via linear blend skinning. To guide the resulting animation toward realistic and semantically meaningful motion, we integrate a text-to-video diffusion model via motion-aware score-distillation sampling (MoSDS), enabling optimization without paired motion data. Additionally, we apply physics-inspired smoothness, topological, and contact constraints to stabilize optimization and preserve motion plausibility. Further, we integrate a spring-mass simulator to introduce secondary motion effects. The proposed framework is generalized, fully differentiable, modular, and compatible with biped, quadruped, and non-living articulated characters. Experiments demonstrate that our approach produces temporally coherent, text-aligned animations that outperform baseline motion transfer methods that lack generative priors or explicit physical constraints. We will make our code and dataset publicly available.
Structurally Consistent MRI Colorization using Cross-modal Fusion Learning
Dec 12, 2024Medical image colorization can greatly enhance the interpretability of the underlying imaging modality and provide insights into human anatomy. The objective of medical image colorization is to transfer a diverse spectrum of colors distributed across human anatomy from Cryosection data to source MRI data while retaining the structures of the MRI. To achieve this, we propose a novel architecture for structurally consistent color transfer to the source MRI data. Our architecture fuses segmentation semantics of Cryosection images for stable contextual colorization of various organs in MRI images. For colorization, we neither require precise registration between MRI and Cryosection images, nor segmentation of MRI images. Additionally, our architecture incorporates a feature compression-and-activation mechanism to capture organ-level global information and suppress noise, enabling the distinction of organ-specific data in MRI scans for more accurate and realistic organ-specific colorization. Our experiments demonstrate that our architecture surpasses the existing methods and yields better quantitative and qualitative results.
Enhancing Sketch Animation: Text-to-Video Diffusion Models with Temporal Consistency and Rigidity Constraints
Nov 28, 2024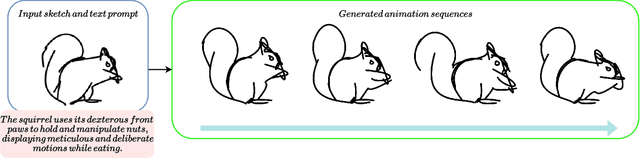
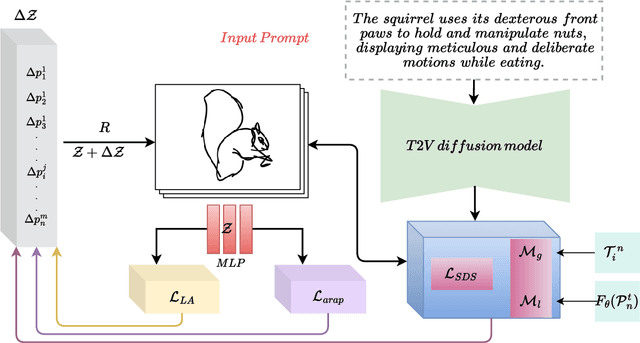
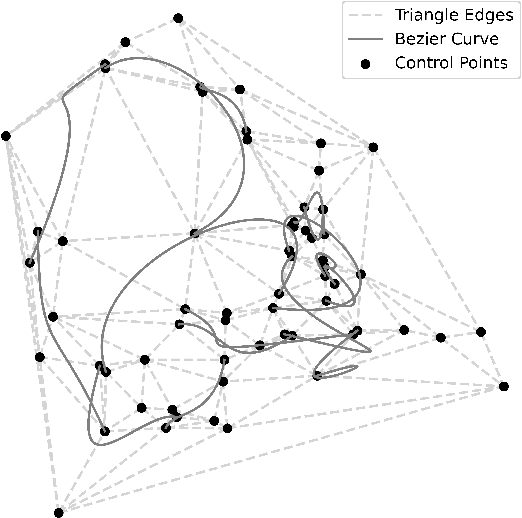
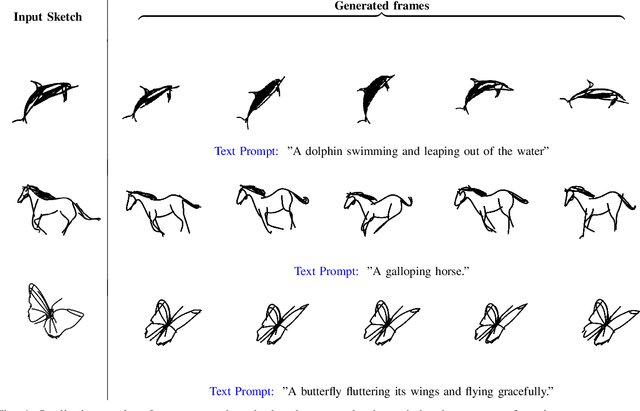
Animating hand-drawn sketches using traditional tools is challenging and complex. Sketches provide a visual basis for explanations, and animating these sketches offers an experience of real-time scenarios. We propose an approach for animating a given input sketch based on a descriptive text prompt. Our method utilizes a parametric representation of the sketch's strokes. Unlike previous methods, which struggle to estimate smooth and accurate motion and often fail to preserve the sketch's topology, we leverage a pre-trained text-to-video diffusion model with SDS loss to guide the motion of the sketch's strokes. We introduce length-area (LA) regularization to ensure temporal consistency by accurately estimating the smooth displacement of control points across the frame sequence. Additionally, to preserve shape and avoid topology changes, we apply a shape-preserving As-Rigid-As-Possible (ARAP) loss to maintain sketch rigidity. Our method surpasses state-of-the-art performance in both quantitative and qualitative evaluations.
MVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification
Sep 10, 2024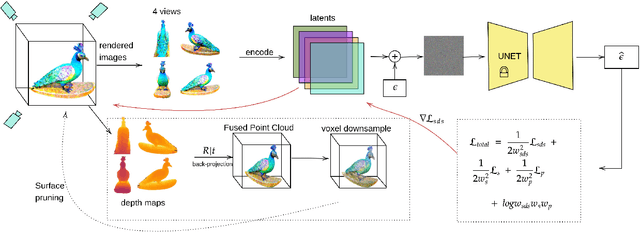
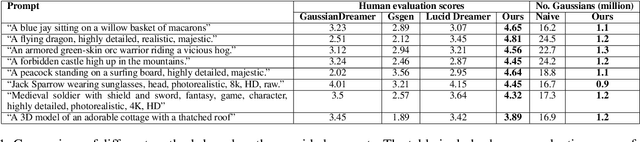
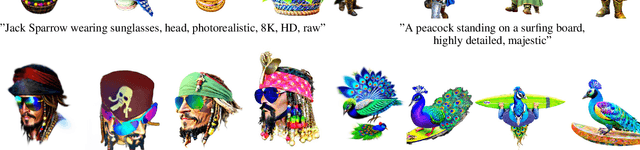

The field of text-to-3D content generation has made significant progress in generating realistic 3D objects, with existing methodologies like Score Distillation Sampling (SDS) offering promising guidance. However, these methods often encounter the "Janus" problem-multi-face ambiguities due to imprecise guidance. Additionally, while recent advancements in 3D gaussian splitting have shown its efficacy in representing 3D volumes, optimization of this representation remains largely unexplored. This paper introduces a unified framework for text-to-3D content generation that addresses these critical gaps. Our approach utilizes multi-view guidance to iteratively form the structure of the 3D model, progressively enhancing detail and accuracy. We also introduce a novel densification algorithm that aligns gaussians close to the surface, optimizing the structural integrity and fidelity of the generated models. Extensive experiments validate our approach, demonstrating that it produces high-quality visual outputs with minimal time cost. Notably, our method achieves high-quality results within half an hour of training, offering a substantial efficiency gain over most existing methods, which require hours of training time to achieve comparable results.
Curvy: A Parametric Cross-section based Surface Reconstruction
Sep 01, 2024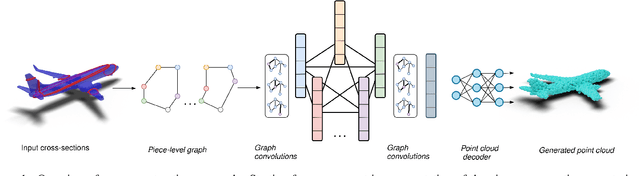
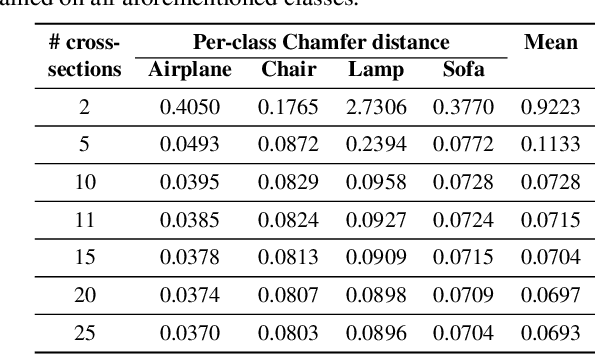
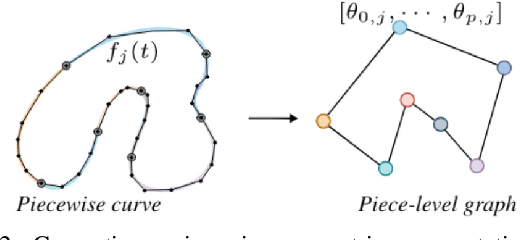
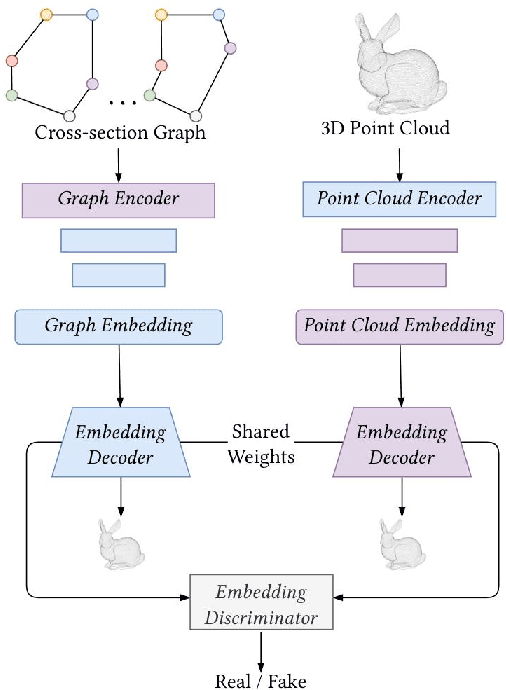
In this work, we present a novel approach for reconstructing shape point clouds using planar sparse cross-sections with the help of generative modeling. We present unique challenges pertaining to the representation and reconstruction in this problem setting. Most methods in the classical literature lack the ability to generalize based on object class and employ complex mathematical machinery to reconstruct reliable surfaces. We present a simple learnable approach to generate a large number of points from a small number of input cross-sections over a large dataset. We use a compact parametric polyline representation using adaptive splitting to represent the cross-sections and perform learning using a Graph Neural Network to reconstruct the underlying shape in an adaptive manner reducing the dependence on the number of cross-sections provided.
Normal-guided Detail-Preserving Neural Implicit Functions for High-Fidelity 3D Surface Reconstruction
Jun 07, 2024Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse RGB views of the objects of interest are available. We hypothesize that current methods for learning neural implicit representations from RGB or RGBD images produce 3D surfaces with missing parts and details because they only rely on 0-order differential properties, i.e. the 3D surface points and their projections, as supervisory signals. Such properties, however, do not capture the local 3D geometry around the points and also ignore the interactions between points. This paper demonstrates that training neural representations with first-order differential properties, i.e. surface normals, leads to highly accurate 3D surface reconstruction even in situations where only as few as two RGB (front and back) images are available. Given multiview RGB images of an object of interest, we first compute the approximate surface normals in the image space using the gradient of the depth maps produced using an off-the-shelf monocular depth estimator such as Depth Anything model. An implicit surface regressor is then trained using a loss function that enforces the first-order differential properties of the regressed surface to match those estimated from Depth Anything. Our extensive experiments on a wide range of real and synthetic datasets show that the proposed method achieves an unprecedented level of reconstruction accuracy even when using as few as two RGB views. The detailed ablation study also demonstrates that normal-based supervision plays a key role in this significant improvement in performance, enabling the 3D reconstruction of intricate geometric details and thin structures that were previously challenging to capture.
RL Dreams: Policy Gradient Optimization for Score Distillation based 3D Generation
Dec 08, 2023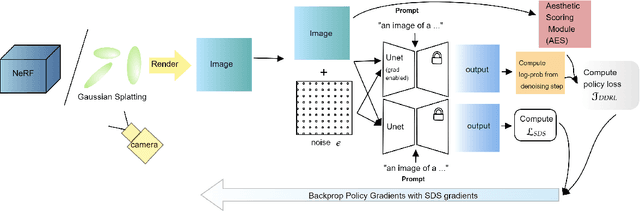

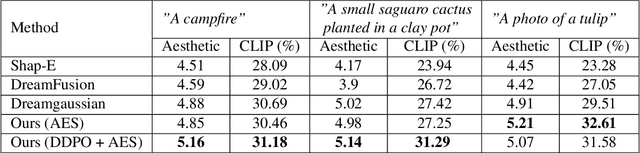

3D generation has rapidly accelerated in the past decade owing to the progress in the field of generative modeling. Score Distillation Sampling (SDS) based rendering has improved 3D asset generation to a great extent. Further, the recent work of Denoising Diffusion Policy Optimization (DDPO) demonstrates that the diffusion process is compatible with policy gradient methods and has been demonstrated to improve the 2D diffusion models using an aesthetic scoring function. We first show that this aesthetic scorer acts as a strong guide for a variety of SDS-based methods and demonstrates its effectiveness in text-to-3D synthesis. Further, we leverage the DDPO approach to improve the quality of the 3D rendering obtained from 2D diffusion models. Our approach, DDPO3D, employs the policy gradient method in tandem with aesthetic scoring. To the best of our knowledge, this is the first method that extends policy gradient methods to 3D score-based rendering and shows improvement across SDS-based methods such as DreamGaussian, which are currently driving research in text-to-3D synthesis. Our approach is compatible with score distillation-based methods, which would facilitate the integration of diverse reward functions into the generative process. Our project page can be accessed via https://ddpo3d.github.io.