 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification
Paper and Code
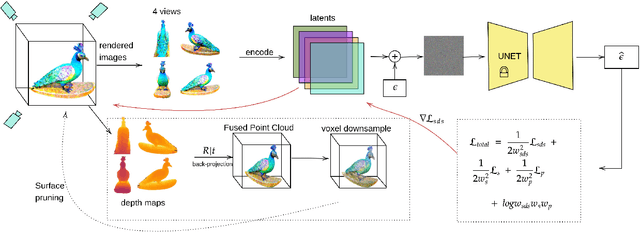
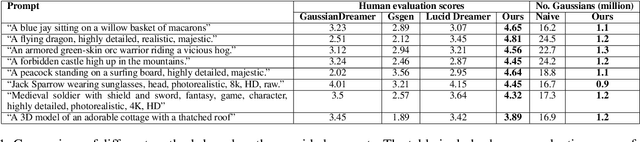
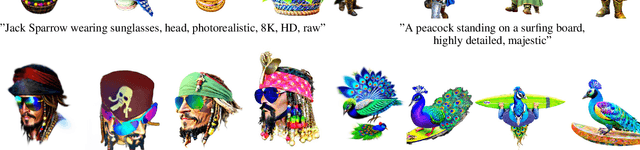

The field of text-to-3D content generation has made significant progress in generating realistic 3D objects, with existing methodologies like Score Distillation Sampling (SDS) offering promising guidance. However, these methods often encounter the "Janus" problem-multi-face ambiguities due to imprecise guidance. Additionally, while recent advancements in 3D gaussian splitting have shown its efficacy in representing 3D volumes, optimization of this representation remains largely unexplored. This paper introduces a unified framework for text-to-3D content generation that addresses these critical gaps. Our approach utilizes multi-view guidance to iteratively form the structure of the 3D model, progressively enhancing detail and accuracy. We also introduce a novel densification algorithm that aligns gaussians close to the surface, optimizing the structural integrity and fidelity of the generated models. Extensive experiments validate our approach, demonstrating that it produces high-quality visual outputs with minimal time cost. Notably, our method achieves high-quality results within half an hour of training, offering a substantial efficiency gain over most existing methods, which require hours of training time to achieve comparable results.