 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification
Sep 10, 2024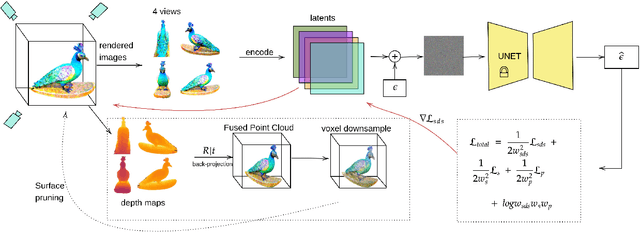
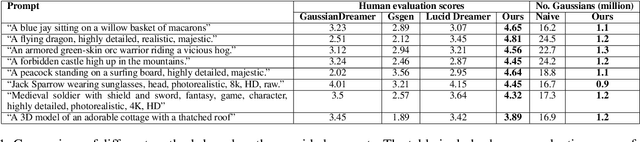
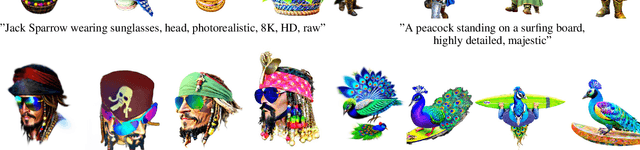

The field of text-to-3D content generation has made significant progress in generating realistic 3D objects, with existing methodologies like Score Distillation Sampling (SDS) offering promising guidance. However, these methods often encounter the "Janus" problem-multi-face ambiguities due to imprecise guidance. Additionally, while recent advancements in 3D gaussian splitting have shown its efficacy in representing 3D volumes, optimization of this representation remains largely unexplored. This paper introduces a unified framework for text-to-3D content generation that addresses these critical gaps. Our approach utilizes multi-view guidance to iteratively form the structure of the 3D model, progressively enhancing detail and accuracy. We also introduce a novel densification algorithm that aligns gaussians close to the surface, optimizing the structural integrity and fidelity of the generated models. Extensive experiments validate our approach, demonstrating that it produces high-quality visual outputs with minimal time cost. Notably, our method achieves high-quality results within half an hour of training, offering a substantial efficiency gain over most existing methods, which require hours of training time to achieve comparable results.
Curvy: A Parametric Cross-section based Surface Reconstruction
Sep 01, 2024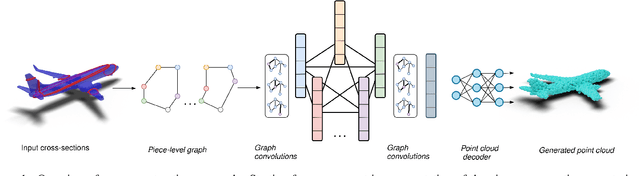
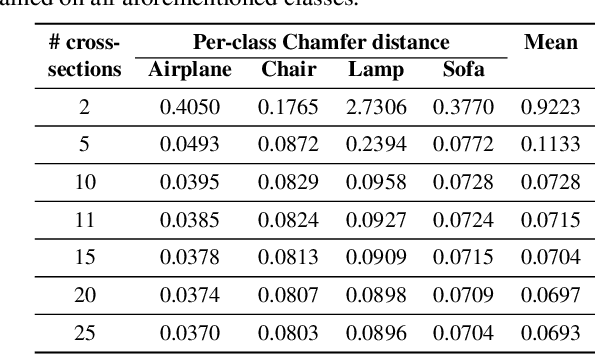
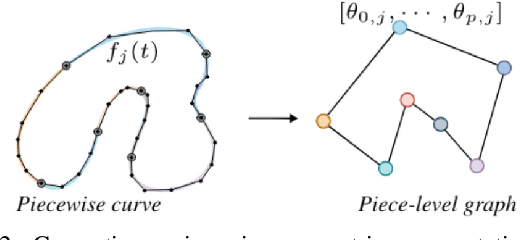
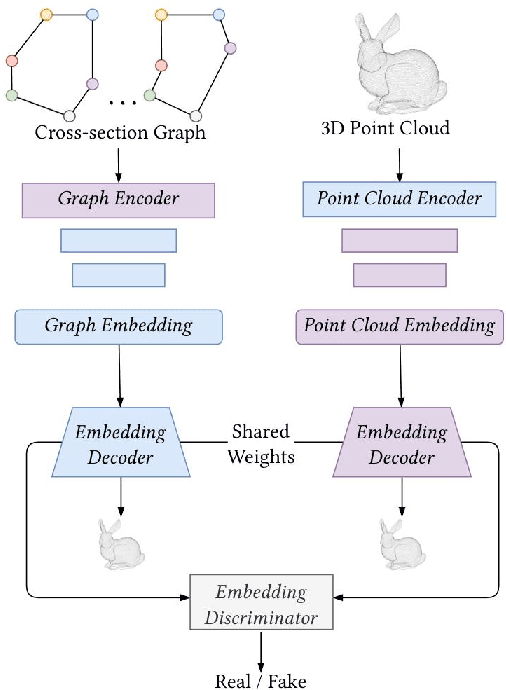
In this work, we present a novel approach for reconstructing shape point clouds using planar sparse cross-sections with the help of generative modeling. We present unique challenges pertaining to the representation and reconstruction in this problem setting. Most methods in the classical literature lack the ability to generalize based on object class and employ complex mathematical machinery to reconstruct reliable surfaces. We present a simple learnable approach to generate a large number of points from a small number of input cross-sections over a large dataset. We use a compact parametric polyline representation using adaptive splitting to represent the cross-sections and perform learning using a Graph Neural Network to reconstruct the underlying shape in an adaptive manner reducing the dependence on the number of cross-sections provided.
RL Dreams: Policy Gradient Optimization for Score Distillation based 3D Generation
Dec 08, 20233D generation has rapidly accelerated in the past decade owing to the progress in the field of generative modeling. Score Distillation Sampling (SDS) based rendering has improved 3D asset generation to a great extent. Further, the recent work of Denoising Diffusion Policy Optimization (DDPO) demonstrates that the diffusion process is compatible with policy gradient methods and has been demonstrated to improve the 2D diffusion models using an aesthetic scoring function. We first show that this aesthetic scorer acts as a strong guide for a variety of SDS-based methods and demonstrates its effectiveness in text-to-3D synthesis. Further, we leverage the DDPO approach to improve the quality of the 3D rendering obtained from 2D diffusion models. Our approach, DDPO3D, employs the policy gradient method in tandem with aesthetic scoring. To the best of our knowledge, this is the first method that extends policy gradient methods to 3D score-based rendering and shows improvement across SDS-based methods such as DreamGaussian, which are currently driving research in text-to-3D synthesis. Our approach is compatible with score distillation-based methods, which would facilitate the integration of diverse reward functions into the generative process. Our project page can be accessed via https://ddpo3d.github.io.