 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-Fault: Benchmarking Time Series Forecasters Against Structural Faults
Jun 16, 2026Time series forecasting (TSF) underpins consequential decisions in energy, transportation, finance, and healthcare, yet TSF models are almost universally ranked by a single number (e.g., average error) on clean held-out data, under the implicit assumption that it predicts deployed reliability. However, real faults are not i.i.d noise but structured events with temporal shape, broken cross-variable dependencies, regime change coupled with missingness, and causal propagation across a sensing pipeline. Treating TSF robustness as a data-quality problem, we present TS-Fault, a benchmark that evaluates forecasting models under explicit, parameterized fault scenarios with controllable semantic difficulty. TS-Fault organizes recurring failures into four modes along two orthogonal axes (observation- vs mechanism-level; univariate vs multivariate) and injects each fault into the most prediction-critical window via a unified importance score. This design enables robustness to be tested against the structures models actually rely on, rather than reduced to generic noise sensitivity. We evaluate 21 models across 6 datasets, 4 modes, and 5 difficulty levels under a paired clean/corrupt protocol. The results reveal three findings that contradict common leaderboard intuition: (i) clean-data accuracy anti-correlates with robustness; (ii) clean rankings are preserved under observation-level faults but reshuffled under mechanism-level faults; and (iii) all catastrophic failures occur under mechanism-level faults, with foundation models achieving the highest clean-data accuracy yet exhibiting the greatest fragility. The code is publicly available at https://github.com/Ray-zyy/TS-Fault.
Fact or Fake? Assessing the Role of Deepfake Detectors in Multimodal Misinformation Detection
Feb 02, 2026In multimodal misinformation, deception usually arises not just from pixel-level manipulations in an image, but from the semantic and contextual claim jointly expressed by the image-text pair. Yet most deepfake detectors, engineered to detect pixel-level forgeries, do not account for claim-level meaning, despite their growing integration in automated fact-checking (AFC) pipelines. This raises a central scientific and practical question: Do pixel-level detectors contribute useful signal for verifying image-text claims, or do they instead introduce misleading authenticity priors that undermine evidence-based reasoning? We provide the first systematic analysis of deepfake detectors in the context of multimodal misinformation detection. Using two complementary benchmarks, MMFakeBench and DGM4, we evaluate: (1) state-of-the-art image-only deepfake detectors, (2) an evidence-driven fact-checking system that performs tool-guided retrieval via Monte Carlo Tree Search (MCTS) and engages in deliberative inference through Multi-Agent Debate (MAD), and (3) a hybrid fact-checking system that injects detector outputs as auxiliary evidence. Results across both benchmark datasets show that deepfake detectors offer limited standalone value, achieving F1 scores in the range of 0.26-0.53 on MMFakeBench and 0.33-0.49 on DGM4, and that incorporating their predictions into fact-checking pipelines consistently reduces performance by 0.04-0.08 F1 due to non-causal authenticity assumptions. In contrast, the evidence-centric fact-checking system achieves the highest performance, reaching F1 scores of approximately 0.81 on MMFakeBench and 0.55 on DGM4. Overall, our findings demonstrate that multimodal claim verification is driven primarily by semantic understanding and external evidence, and that pixel-level artifact signals do not reliably enhance reasoning over real-world image-text misinformation.
Hybrid Transformer-Mamba Architecture for Weakly Supervised Volumetric Medical Segmentation
Dec 11, 2025Weakly supervised semantic segmentation offers a label-efficient solution to train segmentation models for volumetric medical imaging. However, existing approaches often rely on 2D encoders that neglect the inherent volumetric nature of the data. We propose TranSamba, a hybrid Transformer-Mamba architecture designed to capture 3D context for weakly supervised volumetric medical segmentation. TranSamba augments a standard Vision Transformer backbone with Cross-Plane Mamba blocks, which leverage the linear complexity of state space models for efficient information exchange across neighboring slices. The information exchange enhances the pairwise self-attention within slices computed by the Transformer blocks, directly contributing to the attention maps for object localization. TranSamba achieves effective volumetric modeling with time complexity that scales linearly with the input volume depth and maintains constant memory usage for batch processing. Extensive experiments on three datasets demonstrate that TranSamba establishes new state-of-the-art performance, consistently outperforming existing methods across diverse modalities and pathologies. Our source code and trained models are openly accessible at: https://github.com/YihengLyu/TranSamba.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024



Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
MCTformer+: Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation
Aug 06, 2023

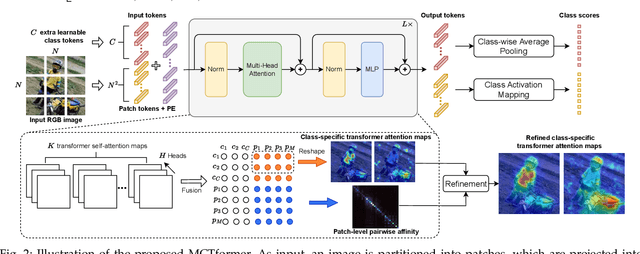

This paper proposes a novel transformer-based framework that aims to enhance weakly supervised semantic segmentation (WSSS) by generating accurate class-specific object localization maps as pseudo labels. Building upon the observation that the attended regions of the one-class token in the standard vision transformer can contribute to a class-agnostic localization map, we explore the potential of the transformer model to capture class-specific attention for class-discriminative object localization by learning multiple class tokens. We introduce a Multi-Class Token transformer, which incorporates multiple class tokens to enable class-aware interactions with the patch tokens. To achieve this, we devise a class-aware training strategy that establishes a one-to-one correspondence between the output class tokens and the ground-truth class labels. Moreover, a Contrastive-Class-Token (CCT) module is proposed to enhance the learning of discriminative class tokens, enabling the model to better capture the unique characteristics and properties of each class. As a result, class-discriminative object localization maps can be effectively generated by leveraging the class-to-patch attentions associated with different class tokens. To further refine these localization maps, we propose the utilization of patch-level pairwise affinity derived from the patch-to-patch transformer attention. Furthermore, the proposed framework seamlessly complements the Class Activation Mapping (CAM) method, resulting in significantly improved WSSS performance on the PASCAL VOC 2012 and MS COCO 2014 datasets. These results underline the importance of the class token for WSSS.
Active-Passive SimStereo -- Benchmarking the Cross-Generalization Capabilities of Deep Learning-based Stereo Methods
Sep 17, 2022


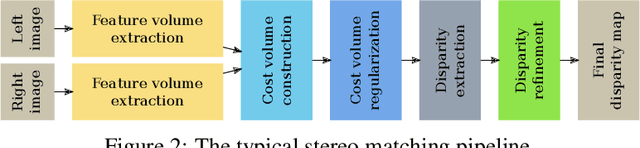
In stereo vision, self-similar or bland regions can make it difficult to match patches between two images. Active stereo-based methods mitigate this problem by projecting a pseudo-random pattern on the scene so that each patch of an image pair can be identified without ambiguity. However, the projected pattern significantly alters the appearance of the image. If this pattern acts as a form of adversarial noise, it could negatively impact the performance of deep learning-based methods, which are now the de-facto standard for dense stereo vision. In this paper, we propose the Active-Passive SimStereo dataset and a corresponding benchmark to evaluate the performance gap between passive and active stereo images for stereo matching algorithms. Using the proposed benchmark and an additional ablation study, we show that the feature extraction and matching modules of a selection of twenty selected deep learning-based stereo matching methods generalize to active stereo without a problem. However, the disparity refinement modules of three of the twenty architectures (ACVNet, CascadeStereo, and StereoNet) are negatively affected by the active stereo patterns due to their reliance on the appearance of the input images.
A Guide to Image and Video based Small Object Detection using Deep Learning : Case Study of Maritime Surveillance
Jul 26, 2022
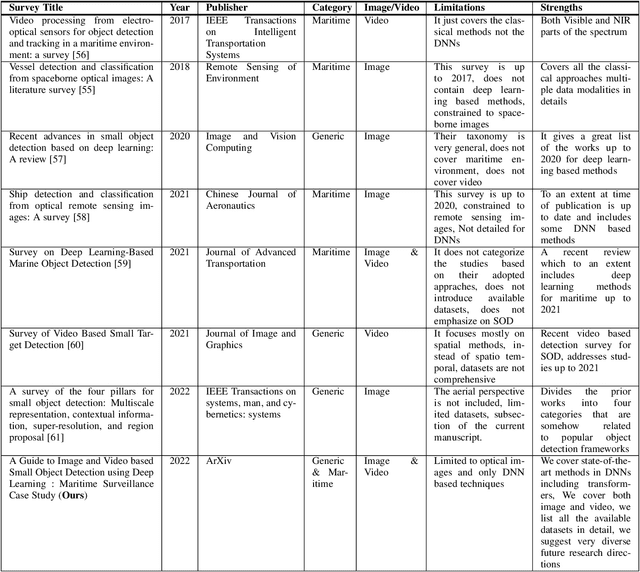
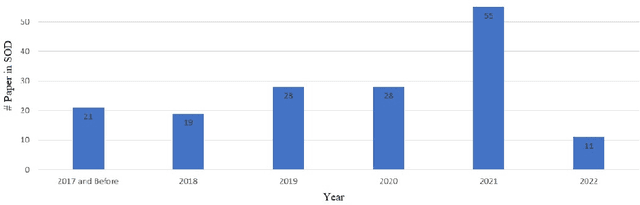
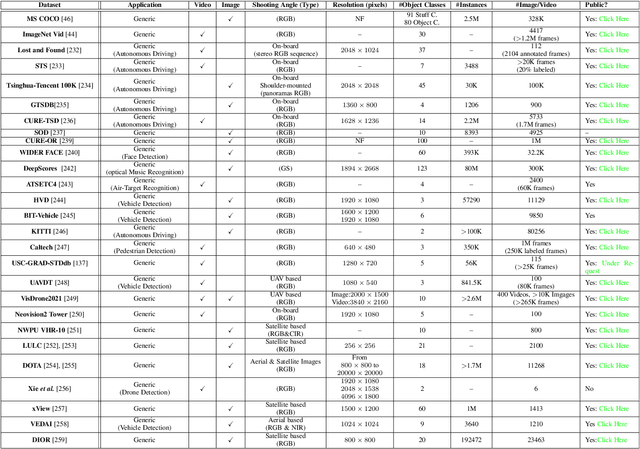
Small object detection (SOD) in optical images and videos is a challenging problem that even state-of-the-art generic object detection methods fail to accurately localize and identify such objects. Typically, small objects appear in real-world due to large camera-object distance. Because small objects occupy only a small area in the input image (e.g., less than 10%), the information extracted from such a small area is not always rich enough to support decision making. Multidisciplinary strategies are being developed by researchers working at the interface of deep learning and computer vision to enhance the performance of SOD deep learning based methods. In this paper, we provide a comprehensive review of over 160 research papers published between 2017 and 2022 in order to survey this growing subject. This paper summarizes the existing literature and provide a taxonomy that illustrates the broad picture of current research. We investigate how to improve the performance of small object detection in maritime environments, where increasing performance is critical. By establishing a connection between generic and maritime SOD research, future directions have been identified. In addition, the popular datasets that have been used for SOD for generic and maritime applications are discussed, and also well-known evaluation metrics for the state-of-the-art methods on some of the datasets are provided.
Multi-class Token Transformer for Weakly Supervised Semantic Segmentation
Mar 06, 2022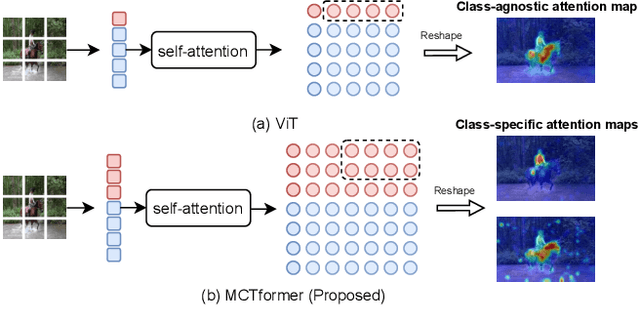
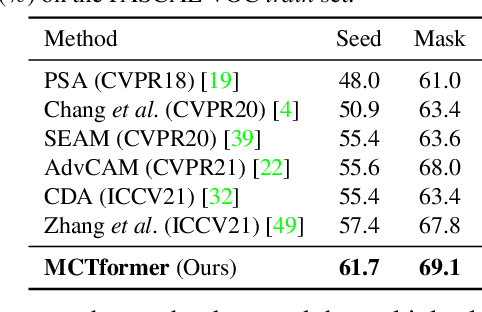
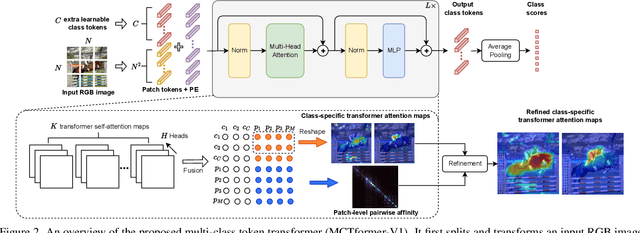
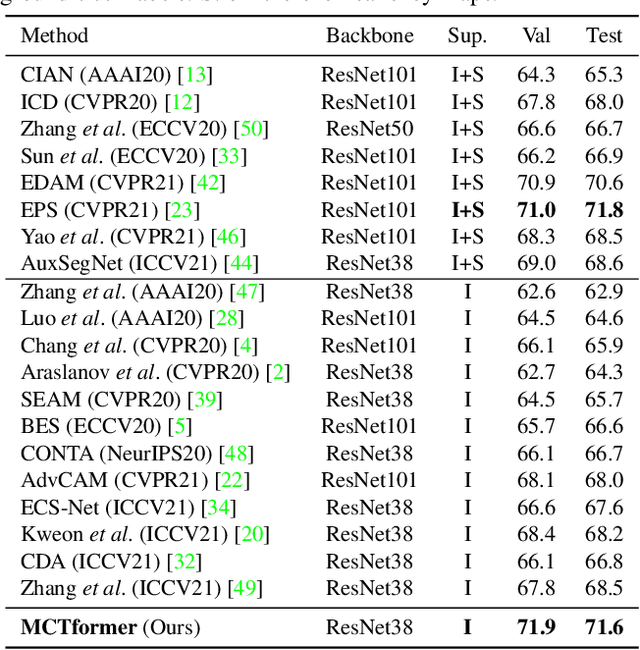
This paper proposes a new transformer-based framework to learn class-specific object localization maps as pseudo labels for weakly supervised semantic segmentation (WSSS). Inspired by the fact that the attended regions of the one-class token in the standard vision transformer can be leveraged to form a class-agnostic localization map, we investigate if the transformer model can also effectively capture class-specific attention for more discriminative object localization by learning multiple class tokens within the transformer. To this end, we propose a Multi-class Token Transformer, termed as MCTformer, which uses multiple class tokens to learn interactions between the class tokens and the patch tokens. The proposed MCTformer can successfully produce class-discriminative object localization maps from class-to-patch attentions corresponding to different class tokens. We also propose to use a patch-level pairwise affinity, which is extracted from the patch-to-patch transformer attention, to further refine the localization maps. Moreover, the proposed framework is shown to fully complement the Class Activation Mapping (CAM) method, leading to remarkably superior WSSS results on the PASCAL VOC and MS COCO datasets. These results underline the importance of the class token for WSSS.
Leveraging Auxiliary Tasks with Affinity Learning for Weakly Supervised Semantic Segmentation
Jul 27, 2021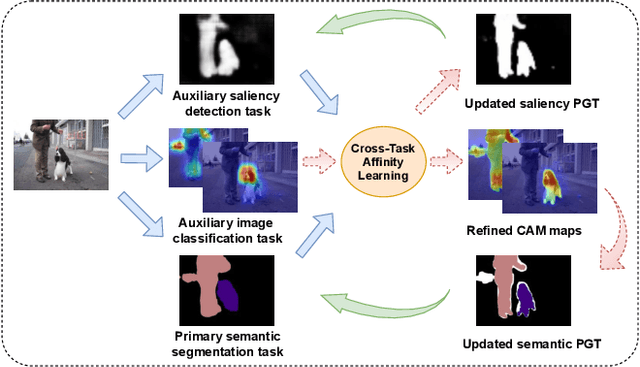
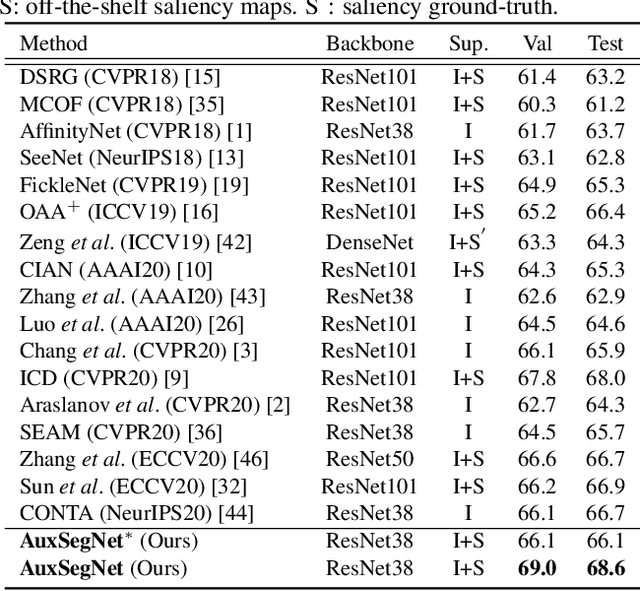
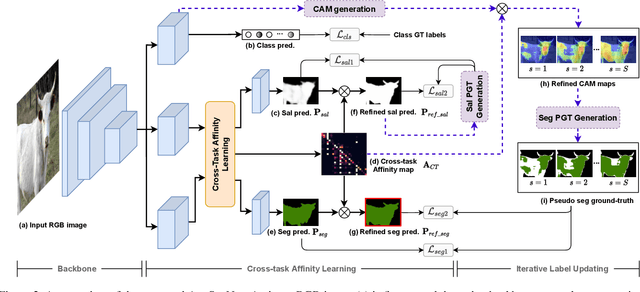

Semantic segmentation is a challenging task in the absence of densely labelled data. Only relying on class activation maps (CAM) with image-level labels provides deficient segmentation supervision. Prior works thus consider pre-trained models to produce coarse saliency maps to guide the generation of pseudo segmentation labels. However, the commonly used off-line heuristic generation process cannot fully exploit the benefits of these coarse saliency maps. Motivated by the significant inter-task correlation, we propose a novel weakly supervised multi-task framework termed as AuxSegNet, to leverage saliency detection and multi-label image classification as auxiliary tasks to improve the primary task of semantic segmentation using only image-level ground-truth labels. Inspired by their similar structured semantics, we also propose to learn a cross-task global pixel-level affinity map from the saliency and segmentation representations. The learned cross-task affinity can be used to refine saliency predictions and propagate CAM maps to provide improved pseudo labels for both tasks. The mutual boost between pseudo label updating and cross-task affinity learning enables iterative improvements on segmentation performance. Extensive experiments demonstrate the effectiveness of the proposed auxiliary learning network structure and the cross-task affinity learning method. The proposed approach achieves state-of-the-art weakly supervised segmentation performance on the challenging PASCAL VOC 2012 and MS COCO benchmarks.