 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class Token Transformer for Weakly Supervised Semantic Segmentation
Paper and Code
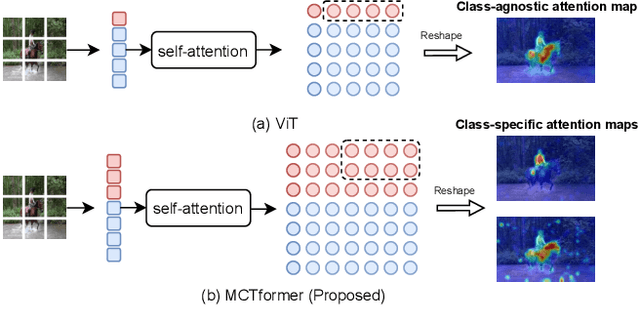
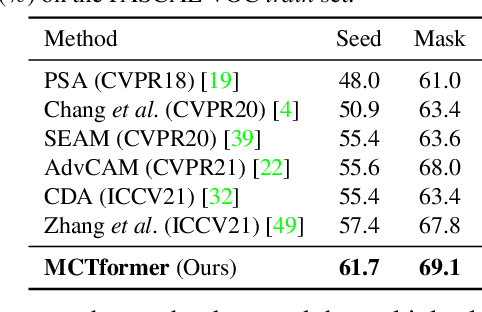
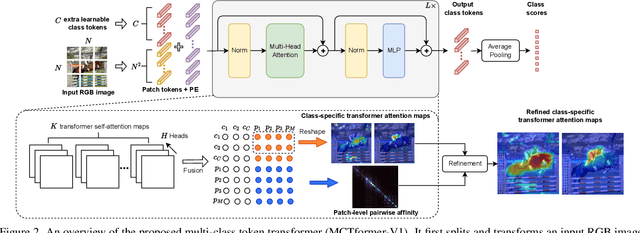
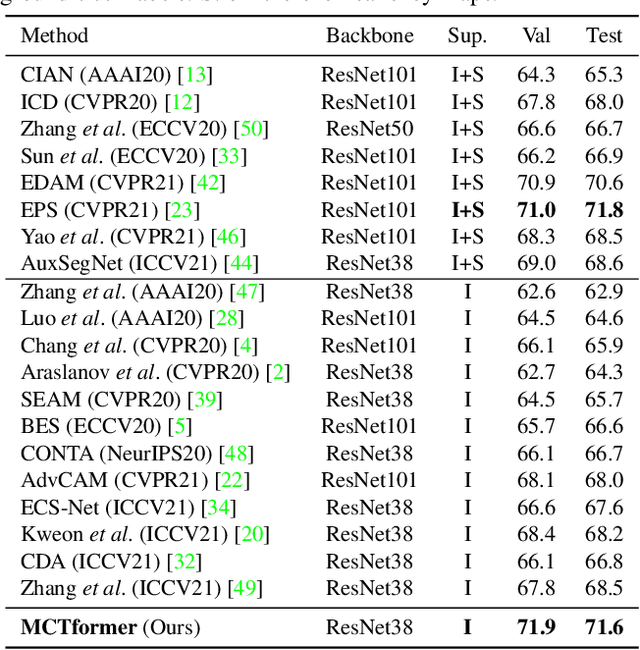
This paper proposes a new transformer-based framework to learn class-specific object localization maps as pseudo labels for weakly supervised semantic segmentation (WSSS). Inspired by the fact that the attended regions of the one-class token in the standard vision transformer can be leveraged to form a class-agnostic localization map, we investigate if the transformer model can also effectively capture class-specific attention for more discriminative object localization by learning multiple class tokens within the transformer. To this end, we propose a Multi-class Token Transformer, termed as MCTformer, which uses multiple class tokens to learn interactions between the class tokens and the patch tokens. The proposed MCTformer can successfully produce class-discriminative object localization maps from class-to-patch attentions corresponding to different class tokens. We also propose to use a patch-level pairwise affinity, which is extracted from the patch-to-patch transformer attention, to further refine the localization maps. Moreover, the proposed framework is shown to fully complement the Class Activation Mapping (CAM) method, leading to remarkably superior WSSS results on the PASCAL VOC and MS COCO datasets. These results underline the importance of the class token for WSSS.