 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022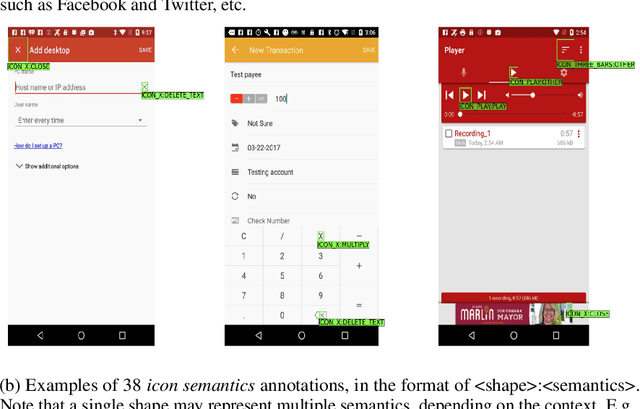

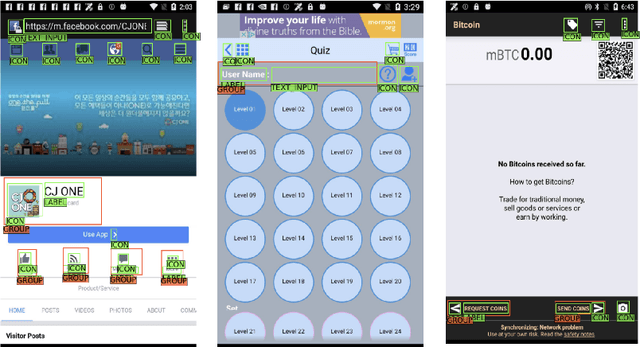

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.
ScreenQA: Large-Scale Question-Answer Pairs over Mobile App Screenshots
Sep 16, 2022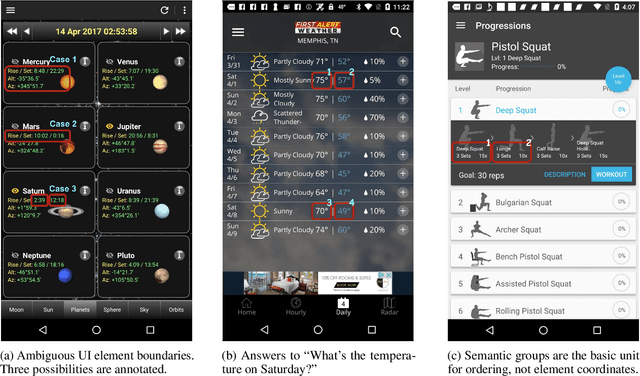
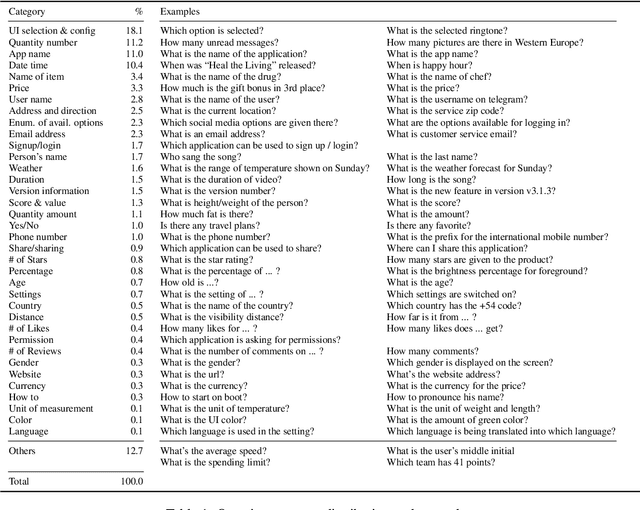
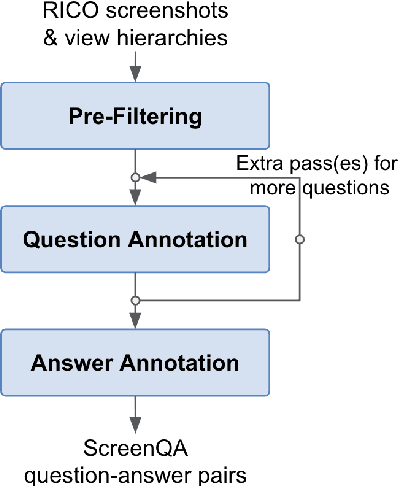

We present a new task and dataset, ScreenQA, for screen content understanding via question answering. The existing screen datasets are focused either on structure and component-level understanding, or on a much higher-level composite task such as navigation and task completion. We attempt to bridge the gap between these two by annotating 80,000+ question-answer pairs over the RICO dataset in hope to benchmark the screen reading comprehension capacity.
Enhanced Robot Speech Recognition Using Biomimetic Binaural Sound Source Localization
Feb 13, 2019
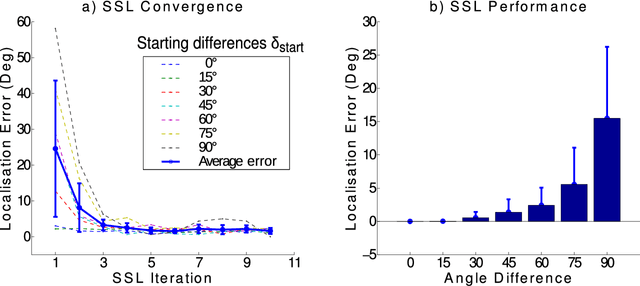
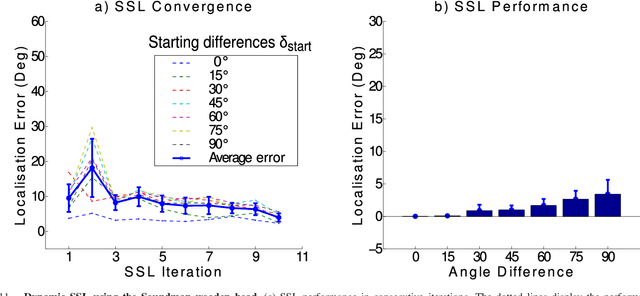
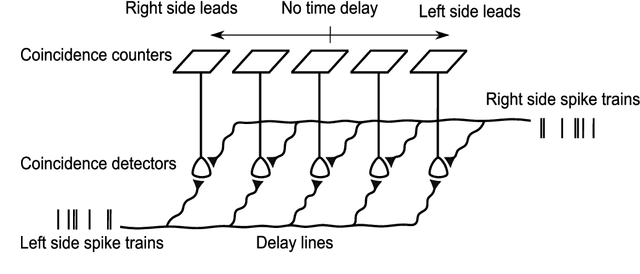
Inspired by the behavior of humans talking in noisy environments, we propose an embodied embedded cognition approach to improve automatic speech recognition (ASR) systems for robots in challenging environments, such as with ego noise, using binaural sound source localization (SSL). The approach is verified by measuring the impact of SSL with a humanoid robot head on the performance of an ASR system. More specifically, a robot orients itself toward the angle where the signal-to-noise ratio (SNR) of speech is maximized for one microphone before doing an ASR task. First, a spiking neural network inspired by the midbrain auditory system based on our previous work is applied to calculate the sound signal angle. Then, a feedforward neural network is used to handle high levels of ego noise and reverberation in the signal. Finally, the sound signal is fed into an ASR system. For ASR, we use a system developed by our group and compare its performance with and without the support from SSL. We test our SSL and ASR systems on two humanoid platforms with different structural and material properties. With our approach we halve the sentence error rate with respect to the common downmixing of both channels. Surprisingly, the ASR performance is more than two times better when the angle between the humanoid head and the sound source allows sound waves to be reflected most intensely from the pinna to the ear microphone, rather than when sound waves arrive perpendicularly to the membrane.