Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScreenQA: Large-Scale Question-Answer Pairs over Mobile App Screenshots
Paper and Code
Sep 16, 2022
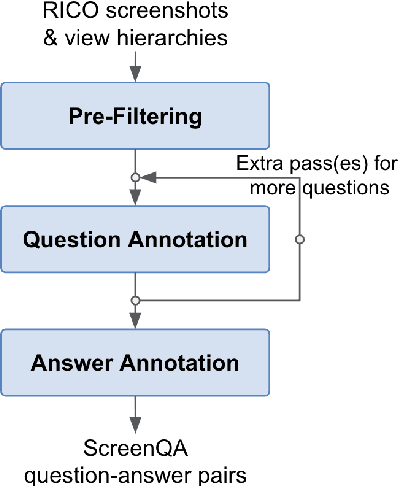

We present a new task and dataset, ScreenQA, for screen content understanding via question answering. The existing screen datasets are focused either on structure and component-level understanding, or on a much higher-level composite task such as navigation and task completion. We attempt to bridge the gap between these two by annotating 80,000+ question-answer pairs over the RICO dataset in hope to benchmark the screen reading comprehension capacity.
View paper on