 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Mar 23, 2026Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022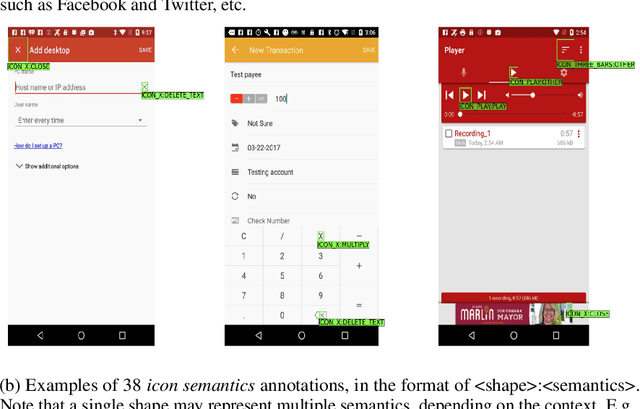

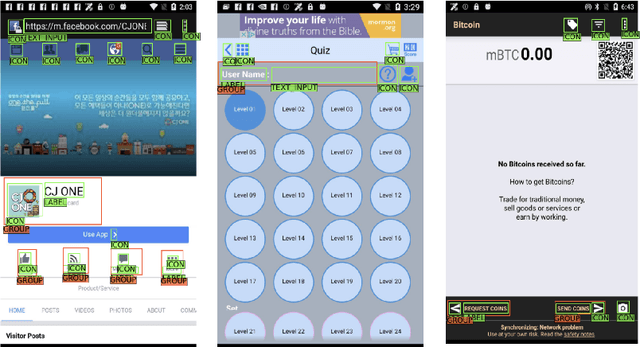

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.
ScreenQA: Large-Scale Question-Answer Pairs over Mobile App Screenshots
Sep 16, 2022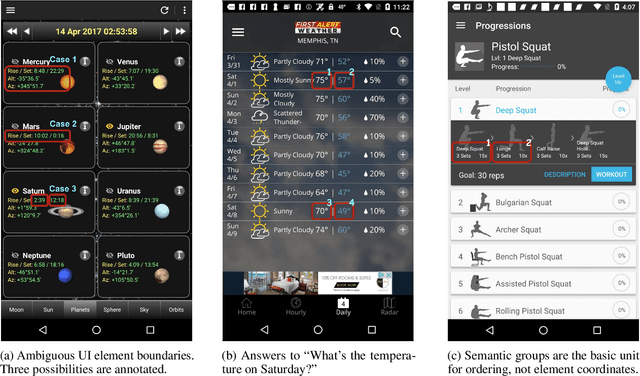
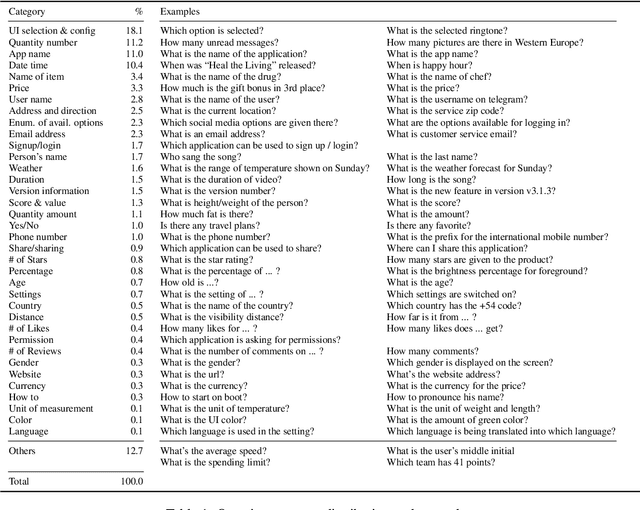
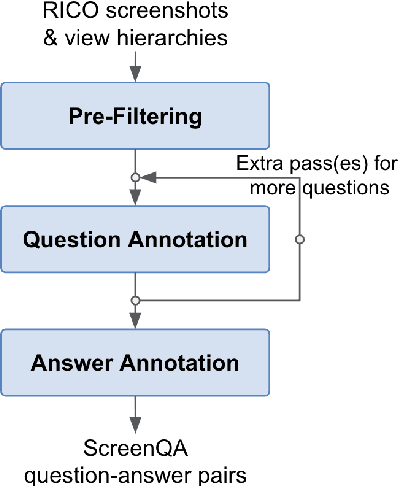

We present a new task and dataset, ScreenQA, for screen content understanding via question answering. The existing screen datasets are focused either on structure and component-level understanding, or on a much higher-level composite task such as navigation and task completion. We attempt to bridge the gap between these two by annotating 80,000+ question-answer pairs over the RICO dataset in hope to benchmark the screen reading comprehension capacity.
PhotoChat: A Human-Human Dialogue Dataset with Photo Sharing Behavior for Joint Image-Text Modeling
Jul 06, 2021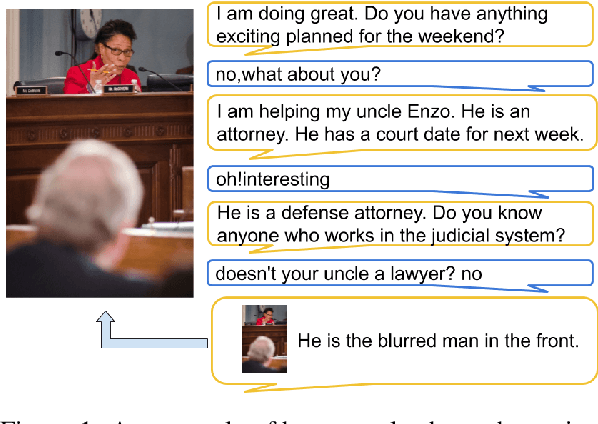
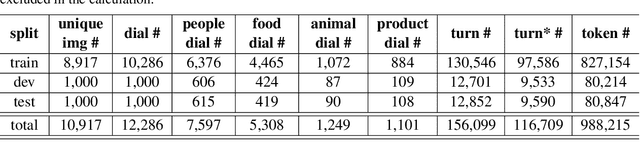
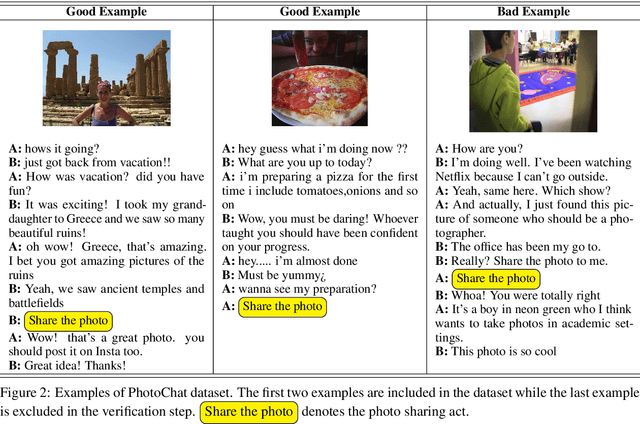
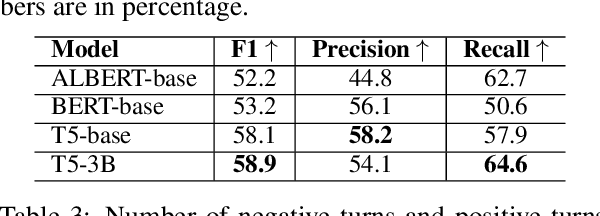
We present a new human-human dialogue dataset - PhotoChat, the first dataset that casts light on the photo sharing behavior in onlin emessaging. PhotoChat contains 12k dialogues, each of which is paired with a user photo that is shared during the conversation. Based on this dataset, we propose two tasks to facilitate research on image-text modeling: a photo-sharing intent prediction task that predicts whether one intends to share a photo in the next conversation turn, and a photo retrieval task that retrieves the most relevant photo according to the dialogue context. In addition, for both tasks, we provide baseline models using the state-of-the-art models and report their benchmark performances. The best image retrieval model achieves 10.4% recall@1 (out of 1000 candidates) and the best photo intent prediction model achieves 58.1% F1 score, indicating that the dataset presents interesting yet challenging real-world problems. We are releasing PhotoChat to facilitate future research work among the community.