 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024



Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022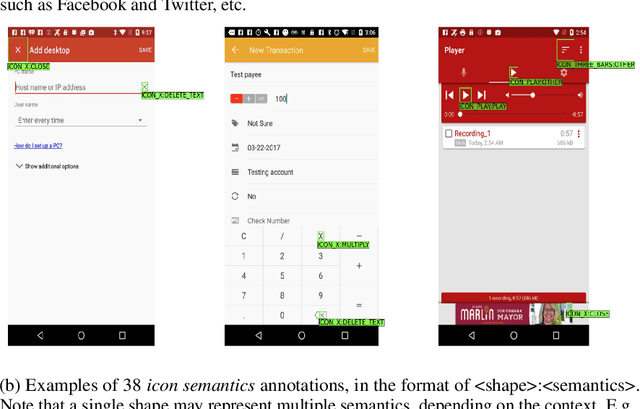

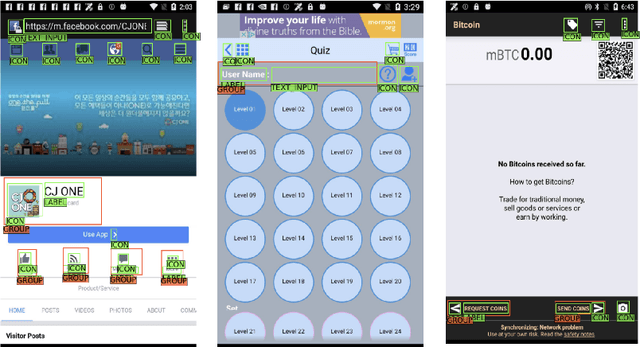

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.