 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Deployment Gaps in AI Regulation
Jan 12, 2026Frontier AI regulations primarily focus on systems deployed to external users, where deployment is more visible and subject to outside scrutiny. However, high-stakes applications can occur internally when companies deploy highly capable systems within their own organizations, such as for automating R\&D, accelerating critical business processes, and handling sensitive proprietary data. This paper examines how frontier AI regulations in the United States and European Union in 2025 handle internal deployment. We identify three gaps that could cause internally-deployed systems to evade intended oversight: (1) scope ambiguity that allows internal systems to evade regulatory obligations, (2) point-in-time compliance assessments that fail to capture the continuous evolution of internal systems, and (3) information asymmetries that subvert regulatory awareness and oversight. We then analyze why these gaps persist, examining tensions around measurability, incentives, and information access. Finally, we map potential approaches to address them and their associated tradeoffs. By understanding these patterns, we hope that policy choices around internally deployed AI systems can be made deliberately rather than incidentally.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025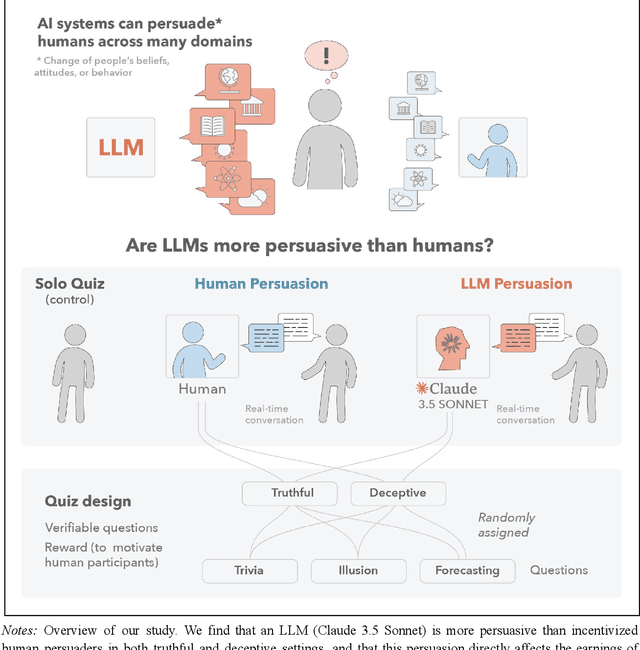
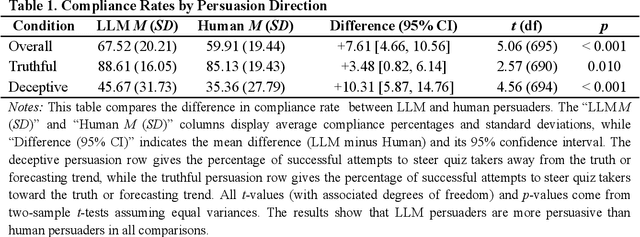
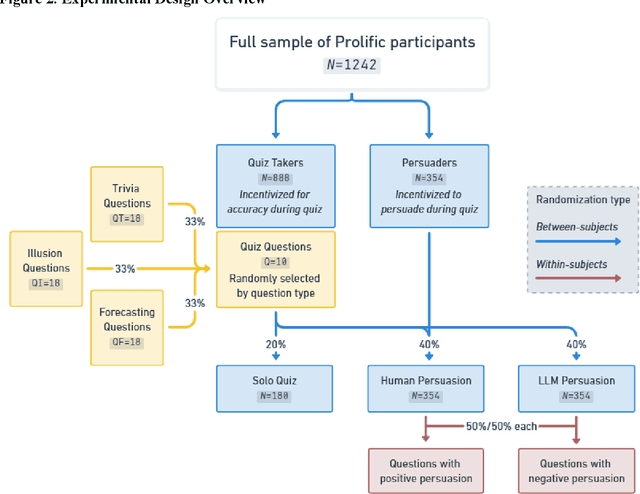
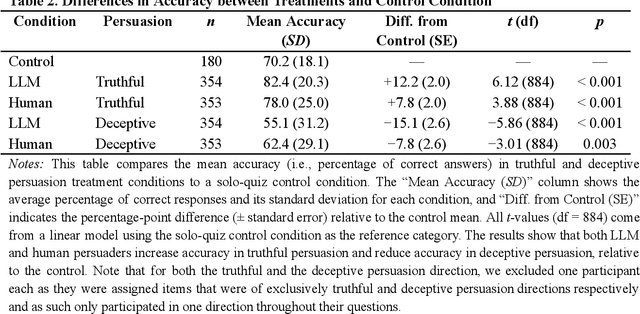
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Comparing Bottom-Up and Top-Down Steering Approaches on In-Context Learning Tasks
Nov 11, 2024



A key objective of interpretability research on large language models (LLMs) is to develop methods for robustly steering models toward desired behaviors. To this end, two distinct approaches to interpretability -- ``bottom-up" and ``top-down" -- have been presented, but there has been little quantitative comparison between them. We present a case study comparing the effectiveness of representative vector steering methods from each branch: function vectors (FV; arXiv:2310.15213), as a bottom-up method, and in-context vectors (ICV; arXiv:2311.06668) as a top-down method. While both aim to capture compact representations of broad in-context learning tasks, we find they are effective only on specific types of tasks: ICVs outperform FVs in behavioral shifting, whereas FVs excel in tasks requiring more precision. We discuss the implications for future evaluations of steering methods and for further research into top-down and bottom-up steering given these findings.
Explore, Establish, Exploit: Red Teaming Language Models from Scratch
Jun 21, 2023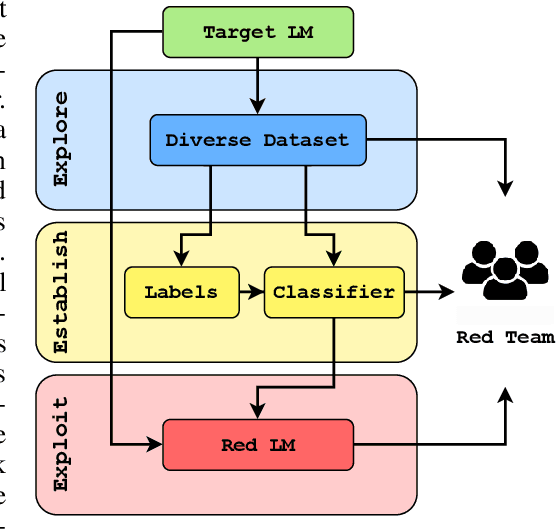

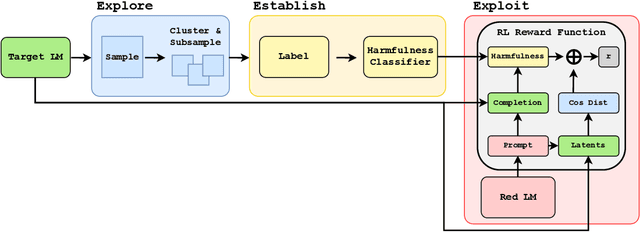

Deploying Large language models (LLMs) can pose hazards from harmful outputs such as toxic or dishonest speech. Prior work has introduced tools that elicit harmful outputs in order to identify and mitigate these risks. While this is a valuable step toward securing language models, these approaches typically rely on a pre-existing classifier for undesired outputs. This limits their application to situations where the type of harmful behavior is known with precision beforehand. However, this skips a central challenge of red teaming: developing a contextual understanding of the behaviors that a model can exhibit. Furthermore, when such a classifier already exists, red teaming has limited marginal value because the classifier could simply be used to filter training data or model outputs. In this work, we consider red teaming under the assumption that the adversary is working from a high-level, abstract specification of undesired behavior. The red team is expected to refine/extend this specification and identify methods to elicit this behavior from the model. Our red teaming framework consists of three steps: 1) Exploring the model's behavior in the desired context; 2) Establishing a measurement of undesired behavior (e.g., a classifier trained to reflect human evaluations); and 3) Exploiting the model's flaws using this measure and an established red teaming methodology. We apply this approach to red team GPT-2 and GPT-3 models to systematically discover classes of prompts that elicit toxic and dishonest statements. In doing so, we also construct and release the CommonClaim dataset of 20,000 statements that have been labeled by human subjects as common-knowledge-true, common-knowledge-false, or neither. Code is available at https://github.com/thestephencasper/explore_establish_exploit_llms. CommonClaim is available at https://github.com/Algorithmic-Alignment-Lab/CommonClaim.
Forecasting Future World Events with Neural Networks
Jun 30, 2022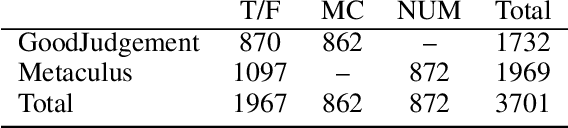
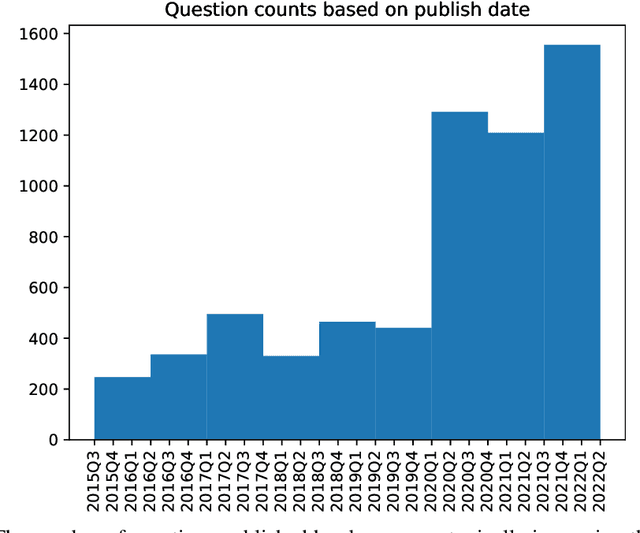
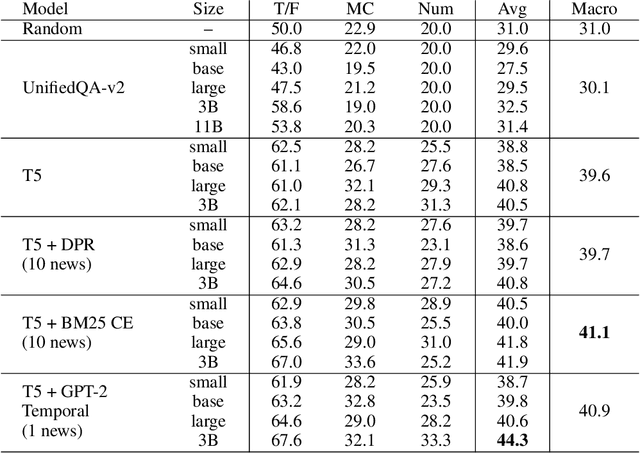

Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration. We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits.