 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall
Oct 22, 2025Discrete diffusion models offer a promising alternative to autoregressive generation through parallel decoding, but they suffer from a sampling wall: once categorical sampling occurs, rich distributional information collapses into one-hot vectors and cannot be propagated across steps, forcing subsequent steps to operate with limited information. To mitigate this problem, we introduce Loopholing, a novel and simple mechanism that preserves this information via a deterministic latent pathway, leading to Loopholing Discrete Diffusion Models (LDDMs). Trained efficiently with a self-conditioning strategy, LDDMs achieve substantial gains-reducing generative perplexity by up to 61% over prior baselines, closing (and in some cases surpassing) the gap with autoregressive models, and producing more coherent text. Applied to reasoning tasks, LDDMs also improve performance on arithmetic benchmarks such as Countdown and Game of 24. These results also indicate that loopholing mitigates idle steps and oscillations, providing a scalable path toward high-quality non-autoregressive text generation.
The Diffusion Duality
Jun 12, 2025Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
Partition Generative Modeling: Masked Modeling Without Masks
May 24, 2025We introduce ``Partition Generative Models'' (PGMs), a novel approach to masked generative modeling (MGMs), particularly effective for masked diffusion language modeling (MDLMs). PGM divides tokens into two distinct groups and employs sparse attention patterns to prevent cross-group information exchange. Hence, the model is trained to predict tokens in one group based solely on information from the other group. This partitioning strategy eliminates the need for MASK tokens entirely. While traditional MGMs inefficiently process MASK tokens during generation, PGMs achieve greater computational efficiency by operating exclusively on unmasked tokens. Our experiments on OpenWebText with a context length of 1024 tokens demonstrate that PGMs deliver at least 5x improvements in both latency and throughput compared to MDLM when using the same number of sampling steps, while generating samples with better generative perplexity than MDLM. Finally, we show that PGMs can be distilled with Self-Distillation Through Time (SDTT), a method originally devised for MDLM, in order to achieve further inference gains.
Beyond Autoregression: Fast LLMs via Self-Distillation Through Time
Oct 28, 2024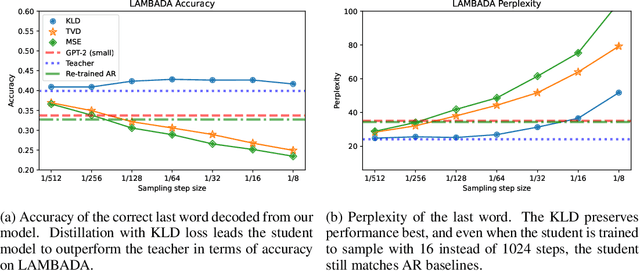
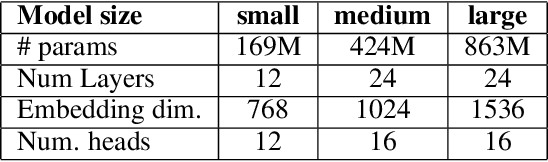
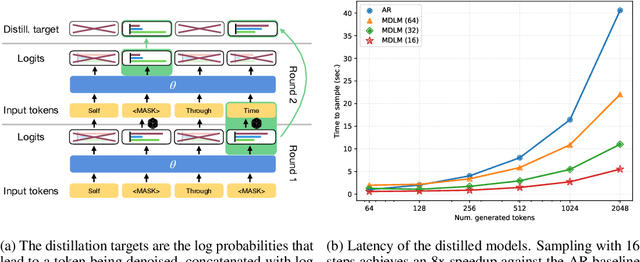
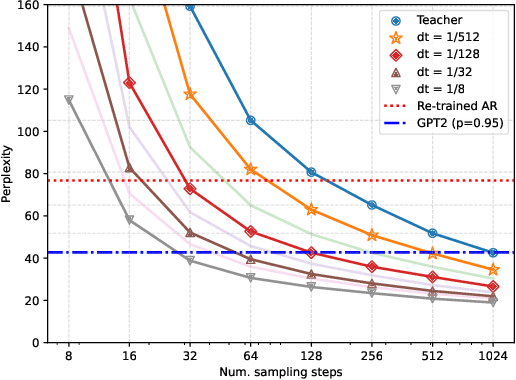
Autoregressive (AR) Large Language Models (LLMs) have demonstrated significant success across numerous tasks. However, the AR modeling paradigm presents certain limitations; for instance, contemporary autoregressive LLMs are trained to generate one token at a time, which can result in noticeable latency. Recent advances have indicated that search and repeated sampling can enhance performance in various applications, such as theorem proving, code generation, and alignment, by utilizing greater computational resources during inference. In this study, we demonstrate that diffusion language models are capable of generating at least 32 tokens simultaneously, while exceeding the performance of AR models in text quality and on the LAMBADA natural language understanding benchmark. This outcome is achieved through a novel distillation method for discrete diffusion models, which reduces the number of inference steps by a factor of 32-64. Practically, our models, even without caching, can generate tokens at a rate that is up to 8 times faster than AR models employing KV caching, and we anticipate further improvements with the inclusion of caching. Moreover, we demonstrate the efficacy of our approach for diffusion language models with up to 860M parameters.
Unpacking SDXL Turbo: Interpreting Text-to-Image Models with Sparse Autoencoders
Oct 28, 2024
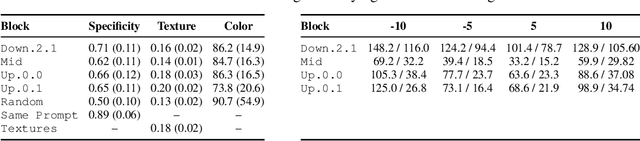


Sparse autoencoders (SAEs) have become a core ingredient in the reverse engineering of large-language models (LLMs). For LLMs, they have been shown to decompose intermediate representations that often are not interpretable directly into sparse sums of interpretable features, facilitating better control and subsequent analysis. However, similar analyses and approaches have been lacking for text-to-image models. We investigated the possibility of using SAEs to learn interpretable features for a few-step text-to-image diffusion models, such as SDXL Turbo. To this end, we train SAEs on the updates performed by transformer blocks within SDXL Turbo's denoising U-net. We find that their learned features are interpretable, causally influence the generation process, and reveal specialization among the blocks. In particular, we find one block that deals mainly with image composition, one that is mainly responsible for adding local details, and one for color, illumination, and style. Therefore, our work is an important first step towards better understanding the internals of generative text-to-image models like SDXL Turbo and showcases the potential of features learned by SAEs for the visual domain. Code is available at https://github.com/surkovv/sdxl-unbox
Promises, Outlooks and Challenges of Diffusion Language Modeling
Jun 17, 2024The modern autoregressive Large Language Models (LLMs) have achieved outstanding performance on NLP benchmarks, and they are deployed in the real world. However, they still suffer from limitations of the autoregressive training paradigm. For example, autoregressive token generation is notably slow and can be prone to \textit{exposure bias}. The diffusion-based language models were proposed as an alternative to autoregressive generation to address some of these limitations. We evaluate the recently proposed Score Entropy Discrete Diffusion (SEDD) approach and show it is a promising alternative to autoregressive generation but it has some short-comings too. We empirically demonstrate the advantages and challenges of SEDD, and observe that SEDD generally matches autoregressive models in perplexity and on benchmarks such as HellaSwag, Arc or WinoGrande. Additionally, we show that in terms of inference latency, SEDD can be up to 4.5$\times$ more efficient than GPT-2. While SEDD allows conditioning on tokens at abitrary positions, SEDD appears slightly weaker than GPT-2 for conditional generation given short prompts. Finally, we reproduced the main results from the original SEDD paper.
Going beyond compositional generalization, DDPMs can produce zero-shot interpolation
May 29, 2024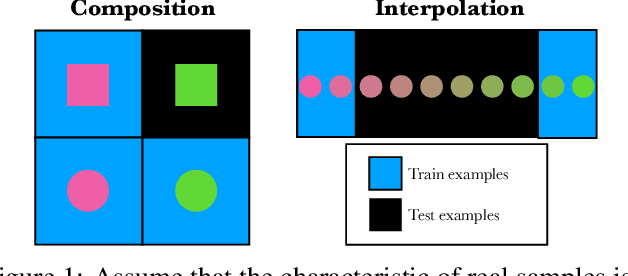



Denoising Diffusion Probabilistic Models (DDPMs) exhibit remarkable capabilities in image generation, with studies suggesting that they can generalize by composing latent factors learned from the training data. In this work, we go further and study DDPMs trained on strictly separate subsets of the data distribution with large gaps on the support of the latent factors. We show that such a model can effectively generate images in the unexplored, intermediate regions of the distribution. For instance, when trained on clearly smiling and non-smiling faces, we demonstrate a sampling procedure which can generate slightly smiling faces without reference images (zero-shot interpolation). We replicate these findings for other attributes as well as other datasets. $\href{https://github.com/jdeschena/ddpm-zero-shot-interpolation}{\text{Our code is available on GitHub.}}$
Distributed Extra-gradient with Optimal Complexity and Communication Guarantees
Aug 17, 2023
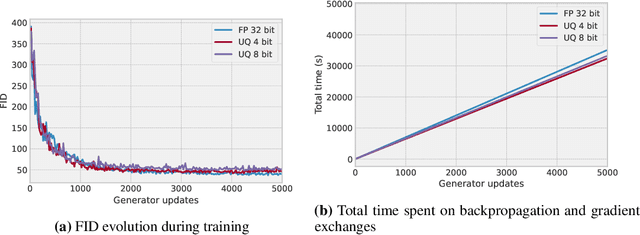
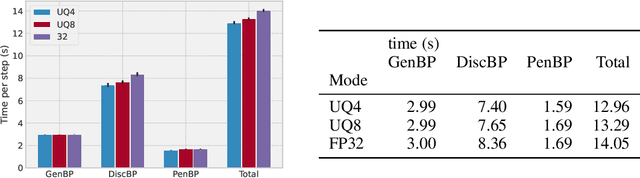
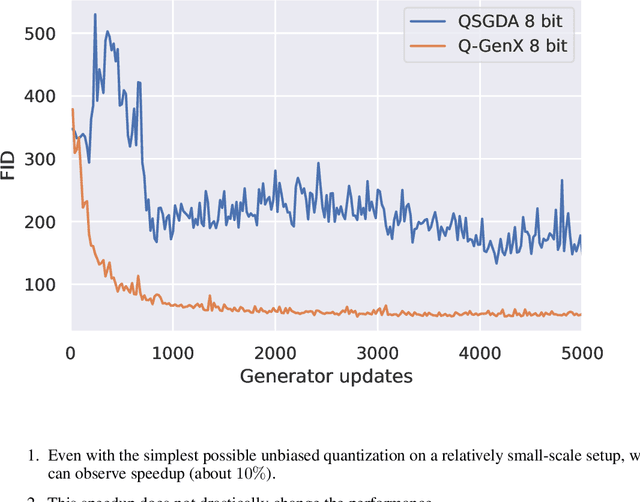
We consider monotone variational inequality (VI) problems in multi-GPU settings where multiple processors/workers/clients have access to local stochastic dual vectors. This setting includes a broad range of important problems from distributed convex minimization to min-max and games. Extra-gradient, which is a de facto algorithm for monotone VI problems, has not been designed to be communication-efficient. To this end, we propose a quantized generalized extra-gradient (Q-GenX), which is an unbiased and adaptive compression method tailored to solve VIs. We provide an adaptive step-size rule, which adapts to the respective noise profiles at hand and achieve a fast rate of ${\mathcal O}(1/T)$ under relative noise, and an order-optimal ${\mathcal O}(1/\sqrt{T})$ under absolute noise and show distributed training accelerates convergence. Finally, we validate our theoretical results by providing real-world experiments and training generative adversarial networks on multiple GPUs.