 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking SDXL Turbo: Interpreting Text-to-Image Models with Sparse Autoencoders
Oct 28, 2024
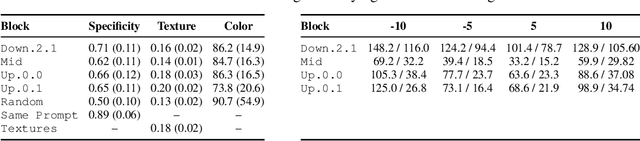


Sparse autoencoders (SAEs) have become a core ingredient in the reverse engineering of large-language models (LLMs). For LLMs, they have been shown to decompose intermediate representations that often are not interpretable directly into sparse sums of interpretable features, facilitating better control and subsequent analysis. However, similar analyses and approaches have been lacking for text-to-image models. We investigated the possibility of using SAEs to learn interpretable features for a few-step text-to-image diffusion models, such as SDXL Turbo. To this end, we train SAEs on the updates performed by transformer blocks within SDXL Turbo's denoising U-net. We find that their learned features are interpretable, causally influence the generation process, and reveal specialization among the blocks. In particular, we find one block that deals mainly with image composition, one that is mainly responsible for adding local details, and one for color, illumination, and style. Therefore, our work is an important first step towards better understanding the internals of generative text-to-image models like SDXL Turbo and showcases the potential of features learned by SAEs for the visual domain. Code is available at https://github.com/surkovv/sdxl-unbox
Self-Recognition in Language Models
Jul 09, 2024



A rapidly growing number of applications rely on a small set of closed-source language models (LMs). This dependency might introduce novel security risks if LMs develop self-recognition capabilities. Inspired by human identity verification methods, we propose a novel approach for assessing self-recognition in LMs using model-generated "security questions". Our test can be externally administered to keep track of frontier models as it does not require access to internal model parameters or output probabilities. We use our test to examine self-recognition in ten of the most capable open- and closed-source LMs currently publicly available. Our extensive experiments found no empirical evidence of general or consistent self-recognition in any examined LM. Instead, our results suggest that given a set of alternatives, LMs seek to pick the "best" answer, regardless of its origin. Moreover, we find indications that preferences about which models produce the best answers are consistent across LMs. We additionally uncover novel insights on position bias considerations for LMs in multiple-choice settings.