 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Rabbit Hole: Mapping the Relational Harms of QAnon Radicalization
Jan 25, 2026The rise of conspiracy theories has created far-reaching societal harm in the public discourse by eroding trust and fueling polarization. Beyond this public impact lies a deeply personal toll on the friends and families of conspiracy believers, a dimension often overlooked in large-scale computational research. This study fills this gap by systematically mapping radicalization journeys and quantifying the associated emotional toll inflicted on loved ones. We use the prominent case of QAnon as a case study, analyzing 12747 narratives from the r/QAnonCasualties support community through a novel mixed-methods approach. First, we use topic modeling (BERTopic) to map the radicalization trajectories, identifying key pre-existing conditions, triggers, and post-radicalization characteristics. From this, we apply an LDA-based graphical model to uncover six recurring archetypes of QAnon adherents, which we term "radicalization personas." Finally, using LLM-assisted emotion detection and regression modeling, we link these personas to the specific emotional toll reported by narrators. Our findings reveal that these personas are not just descriptive; they are powerful predictors of the specific emotional harms experienced by narrators. Radicalization perceived as a deliberate ideological choice is associated with narrator anger and disgust, while those marked by personal and cognitive collapse are linked to fear and sadness. This work provides the first empirical framework for understanding radicalization as a relational phenomenon, offering a vital roadmap for researchers and practitioners to navigate its interpersonal fallout.
Carrot, stick, or both? Price incentives for sustainable food choice in competitive environments
Dec 15, 2025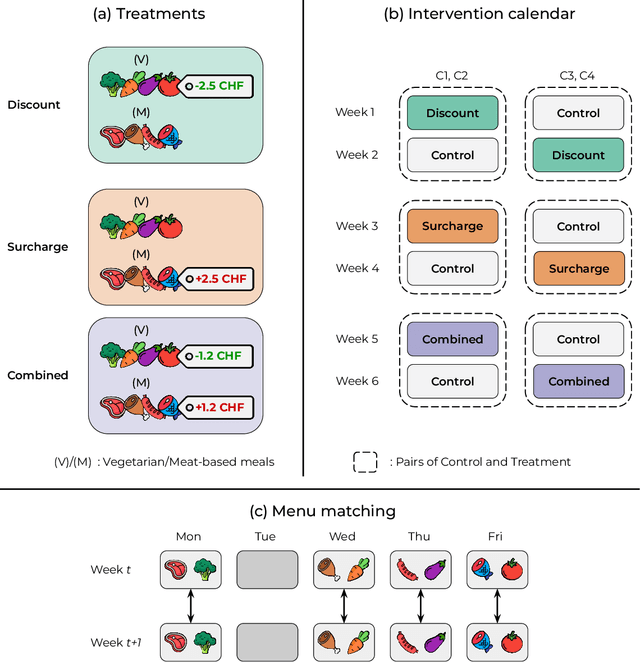
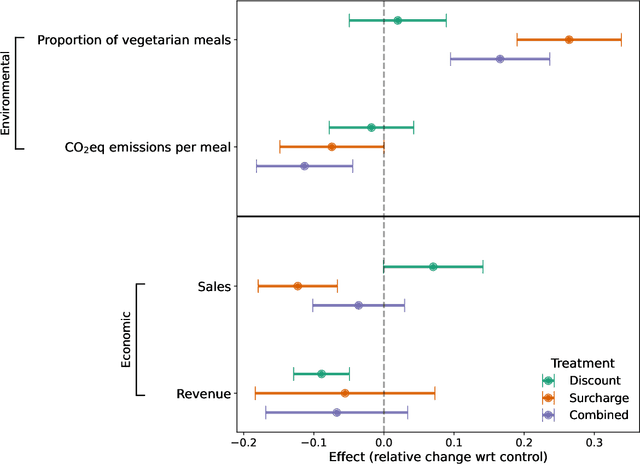
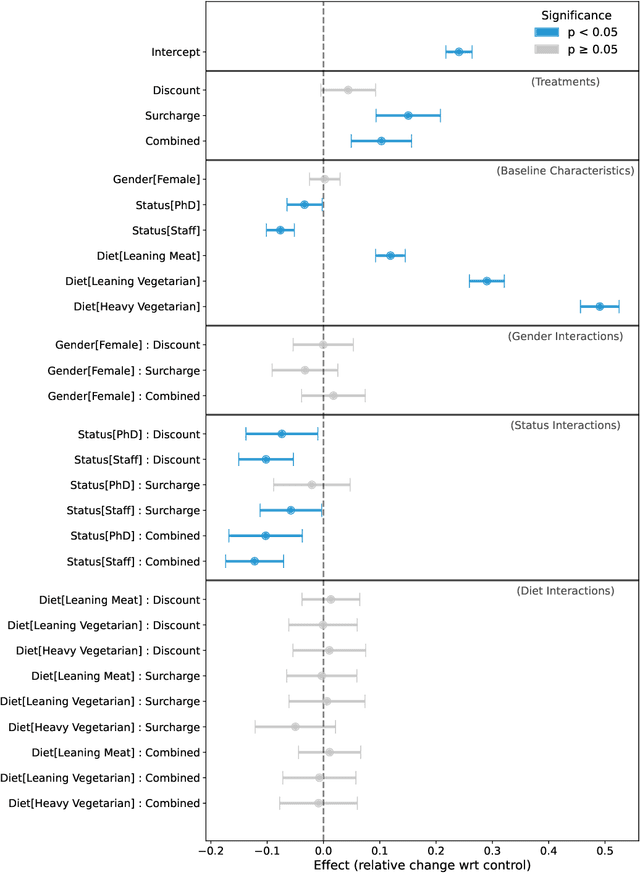
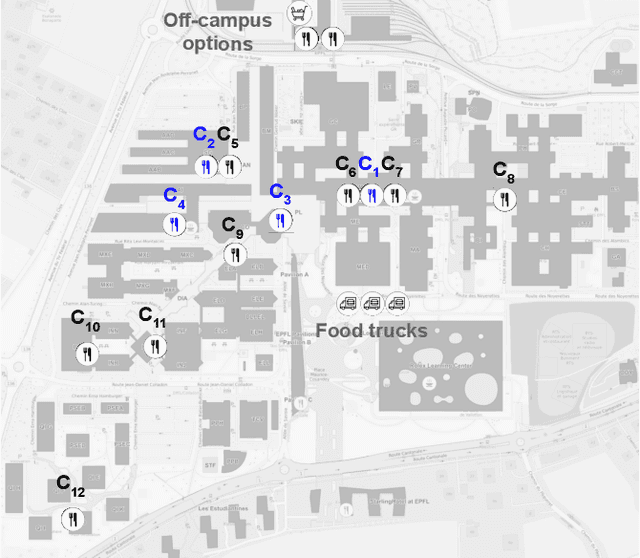
Meat consumption is a major driver of global greenhouse gas emissions. While pricing interventions have shown potential to reduce meat intake, previous studies have focused on highly constrained environments with limited consumer choice. Here, we present the first large-scale field experiment to evaluate multiple pricing interventions in a real-world, competitive setting. Using a sequential crossover design with matched menus in a Swiss university campus, we systematically compared vegetarian-meal discounts (-2.5 CHF), meat surcharges (+2.5 CHF), and a combined scheme (-1.2 CHF=+1.2 CHF) across four campus cafeterias. Only the surcharge and combined interventions led to significant increases in vegetarian meal uptake--by 26.4% and 16.6%, respectively--and reduced CO2 emissions per meal by 7.4% and 11.3%, respectively. The surcharge, while effective, triggered a 12.3% drop in sales at intervention sites and a corresponding 14.9% increase in non-treated locations, hence causing a spillover effect that completely offset environmental gains. In contrast, the combined approach achieved meaningful emission reductions without significant effects on overall sales or revenue, making it both effective and economically viable. Notably, pricing interventions were equally effective for both vegetarian-leaning customers and habitual meat-eaters, stimulating change even within entrenched dietary habits. Our results show that balanced pricing strategies can reduce the carbon footprint of realistic food environments, but require coordinated implementation to maximize climate benefits and avoid unintended spillover effects.
The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and Large Language Models
Jul 23, 2025People increasingly rely on Large Language Models (LLMs) for moral advice, which may influence humans' decisions. Yet, little is known about how closely LLMs align with human moral judgments. To address this, we introduce the Moral Dilemma Dataset, a benchmark of 1,618 real-world moral dilemmas paired with a distribution of human moral judgments consisting of a binary evaluation and a free-text rationale. We treat this problem as a pluralistic distributional alignment task, comparing the distributions of LLM and human judgments across dilemmas. We find that models reproduce human judgments only under high consensus; alignment deteriorates sharply when human disagreement increases. In parallel, using a 60-value taxonomy built from 3,783 value expressions extracted from rationales, we show that LLMs rely on a narrower set of moral values than humans. These findings reveal a pluralistic moral gap: a mismatch in both the distribution and diversity of values expressed. To close this gap, we introduce Dynamic Moral Profiling (DMP), a Dirichlet-based sampling method that conditions model outputs on human-derived value profiles. DMP improves alignment by 64.3% and enhances value diversity, offering a step toward more pluralistic and human-aligned moral guidance from LLMs.
Self-Recognition in Language Models
Jul 09, 2024



A rapidly growing number of applications rely on a small set of closed-source language models (LMs). This dependency might introduce novel security risks if LMs develop self-recognition capabilities. Inspired by human identity verification methods, we propose a novel approach for assessing self-recognition in LMs using model-generated "security questions". Our test can be externally administered to keep track of frontier models as it does not require access to internal model parameters or output probabilities. We use our test to examine self-recognition in ten of the most capable open- and closed-source LMs currently publicly available. Our extensive experiments found no empirical evidence of general or consistent self-recognition in any examined LM. Instead, our results suggest that given a set of alternatives, LMs seek to pick the "best" answer, regardless of its origin. Moreover, we find indications that preferences about which models produce the best answers are consistent across LMs. We additionally uncover novel insights on position bias considerations for LMs in multiple-choice settings.
Stranger Danger! Cross-Community Interactions with Fringe Users Increase the Growth of Fringe Communities on Reddit
Oct 18, 2023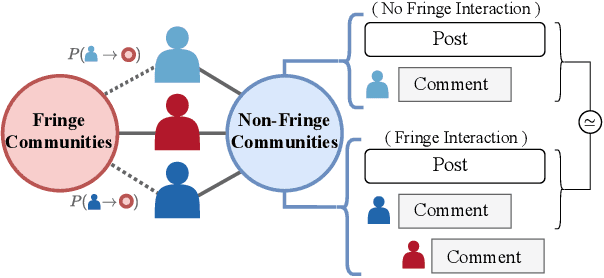
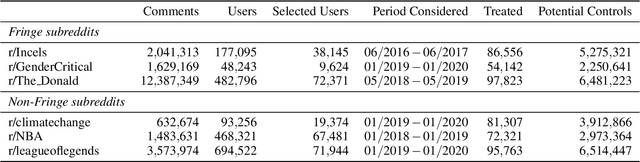
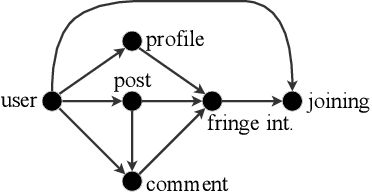
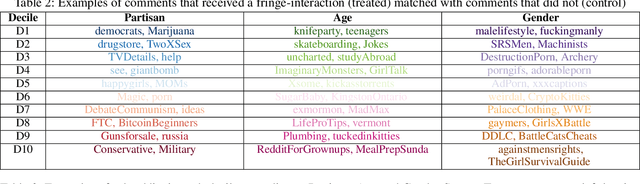
Fringe communities promoting conspiracy theories and extremist ideologies have thrived on mainstream platforms, raising questions about the mechanisms driving their growth. Here, we hypothesize and study a possible mechanism: new members may be recruited through fringe-interactions: the exchange of comments between members and non-members of fringe communities. We apply text-based causal inference techniques to study the impact of fringe-interactions on the growth of three prominent fringe communities on Reddit: r/Incel, r/GenderCritical, and r/The_Donald. Our results indicate that fringe-interactions attract new members to fringe communities. Users who receive these interactions are up to 4.2 percentage points (pp) more likely to join fringe communities than similar, matched users who do not. This effect is influenced by 1) the characteristics of communities where the interaction happens (e.g., left vs. right-leaning communities) and 2) the language used in the interactions. Interactions using toxic language have a 5pp higher chance of attracting newcomers to fringe communities than non-toxic interactions. We find no effect when repeating this analysis by replacing fringe (r/Incel, r/GenderCritical, and r/The_Donald) with non-fringe communities (r/climatechange, r/NBA, r/leagueoflegends), suggesting this growth mechanism is specific to fringe communities. Overall, our findings suggest that curtailing fringe-interactions may reduce the growth of fringe communities on mainstream platforms.
ACTI at EVALITA 2023: Overview of the Conspiracy Theory Identification Task
Jul 12, 2023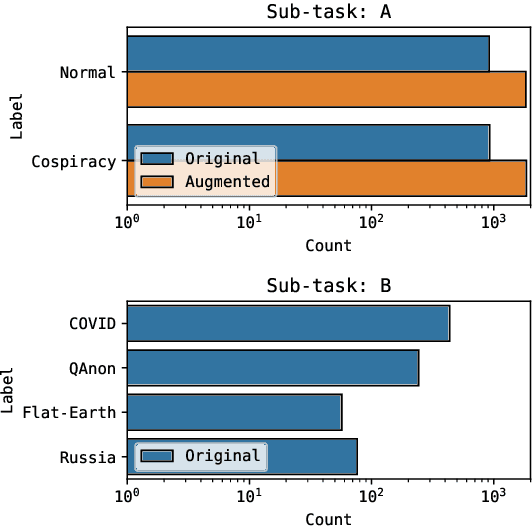
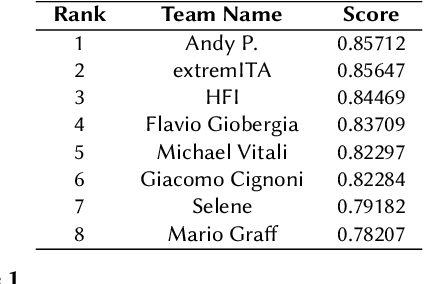
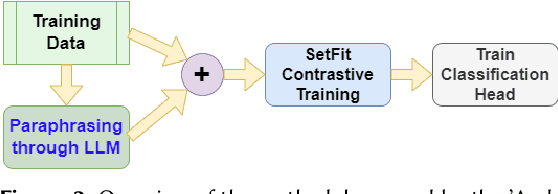
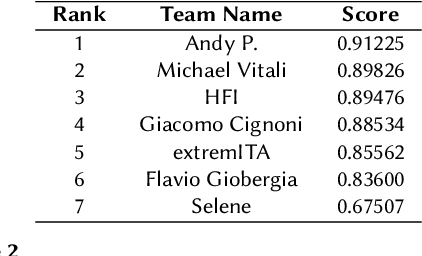
Conspiracy Theory Identication task is a new shared task proposed for the first time at the Evalita 2023. The ACTI challenge, based exclusively on comments published on conspiratorial channels of telegram, is divided into two subtasks: (i) Conspiratorial Content Classification: identifying conspiratorial content and (ii) Conspiratorial Category Classification about specific conspiracy theory classification. A total of fifteen teams participated in the task for a total of 81 submissions. We illustrate the best performing approaches were based on the utilization of large language models. We finally draw conclusions about the utilization of these models for counteracting the spreading of misinformation in online platforms.
Understanding Online Migration Decisions Following the Banning of Radical Communities
Dec 09, 2022The proliferation of radical online communities and their violent offshoots has sparked great societal concern. However, the current practice of banning such communities from mainstream platforms has unintended consequences: (I) the further radicalization of their members in fringe platforms where they migrate; and (ii) the spillover of harmful content from fringe back onto mainstream platforms. Here, in a large observational study on two banned subreddits, r/The\_Donald and r/fatpeoplehate, we examine how factors associated with the RECRO radicalization framework relate to users' migration decisions. Specifically, we quantify how these factors affect users' decisions to post on fringe platforms and, for those who do, whether they continue posting on the mainstream platform. Our results show that individual-level factors, those relating to the behavior of users, are associated with the decision to post on the fringe platform. Whereas social-level factors, users' connection with the radical community, only affect the propensity to be coactive on both platforms. Overall, our findings pave the way for evidence-based moderation policies, as the decisions to migrate and remain coactive amplify unintended consequences of community bans.
Spillover of Antisocial Behavior from Fringe Platforms: The Unintended Consequences of Community Banning
Sep 20, 2022
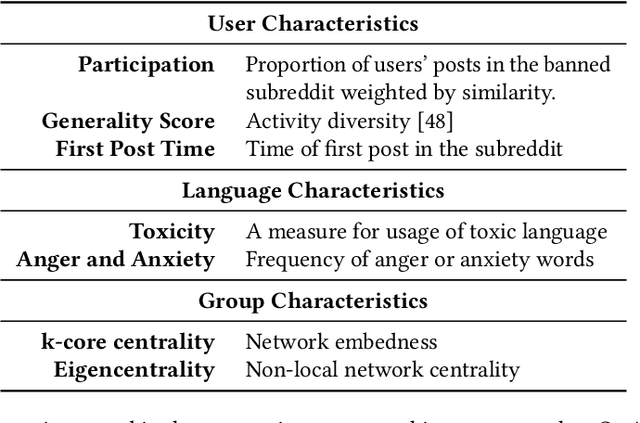
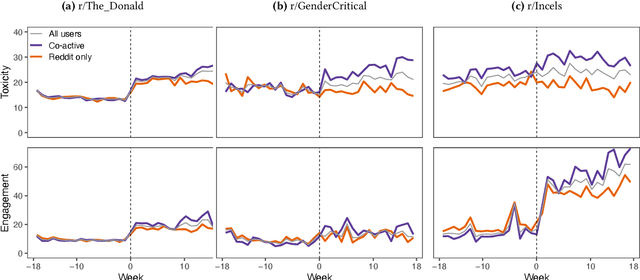

Online platforms face pressure to keep their communities civil and respectful. Thus, the bannings of problematic online communities from mainstream platforms like Reddit and Facebook are often met with enthusiastic public reactions. However, this policy can lead users to migrate to alternative fringe platforms with lower moderation standards and where antisocial behaviors like trolling and harassment are widely accepted. As users of these communities often remain \ca across mainstream and fringe platforms, antisocial behaviors may spill over onto the mainstream platform. We study this possible spillover by analyzing around $70,000$ users from three banned communities that migrated to fringe platforms: r/The\_Donald, r/GenderCritical, and r/Incels. Using a difference-in-differences design, we contrast \ca users with matched counterparts to estimate the causal effect of fringe platform participation on users' antisocial behavior on Reddit. Our results show that participating in the fringe communities increases users' toxicity on Reddit (as measured by Perspective API) and involvement with subreddits similar to the banned community -- which often also breach platform norms. The effect intensifies with time and exposure to the fringe platform. In short, we find evidence for a spillover of antisocial behavior from fringe platforms onto Reddit via co-participation.
Disentangling Active and Passive Cosponsorship in the U.S. Congress
May 19, 2022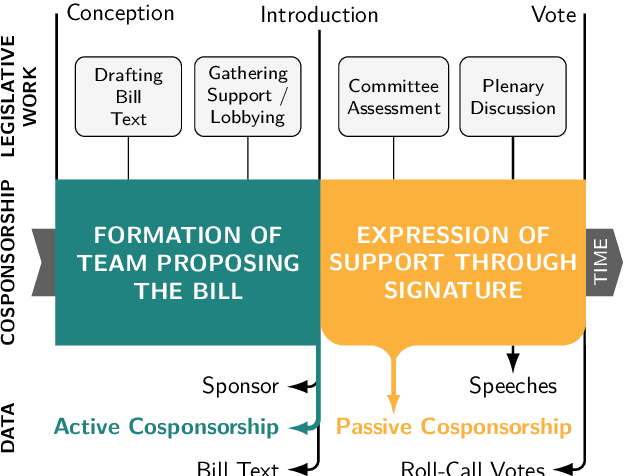
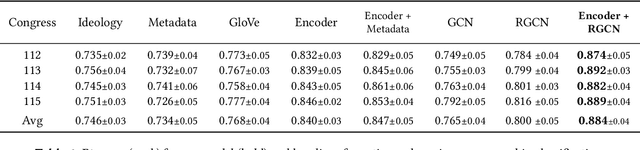
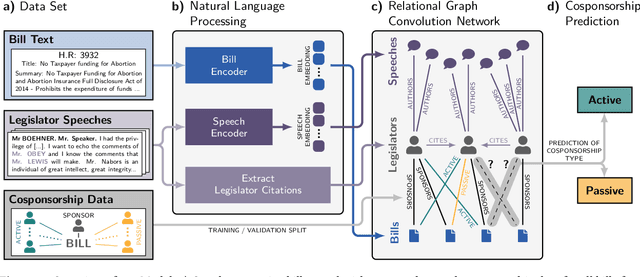
In the U.S. Congress, legislators can use active and passive cosponsorship to support bills. We show that these two types of cosponsorship are driven by two different motivations: the backing of political colleagues and the backing of the bill's content. To this end, we develop an Encoder+RGCN based model that learns legislator representations from bill texts and speech transcripts. These representations predict active and passive cosponsorship with an F1-score of 0.88. Applying our representations to predict voting decisions, we show that they are interpretable and generalize to unseen tasks.
Control, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation
Apr 30, 2020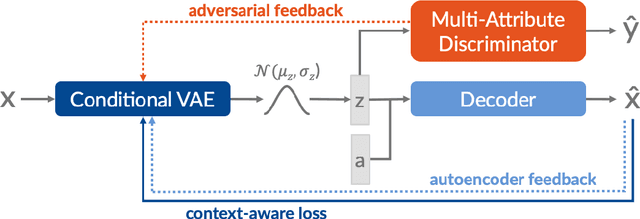



In this work, we present a text generation approach with multi-attribute control for data augmentation. We introduce CGA, a Variational Autoencoder architecture, to control, generate, and augment text. CGA is able to generate natural sentences with multiple controlled attributes by combining adversarial learning with a context-aware loss. The scalability of our approach is established through a single discriminator, independently of the number of attributes. As the main application of our work, we test the potential of this new model in a data augmentation use case. In a downstream NLP task, the sentences generated by our CGA model not only show significant improvements over a strong baseline, but also a classification performance very similar to real data. Furthermore, we are able to show high quality, diversity and attribute control in the generated sentences through a series of automatic and human assessments.