 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing signed relations from interaction data
Sep 07, 2022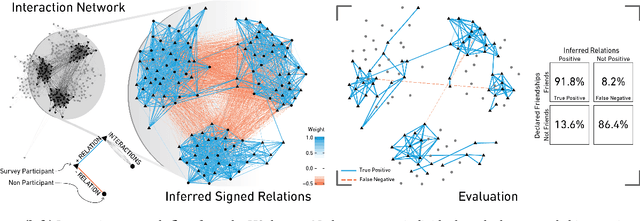
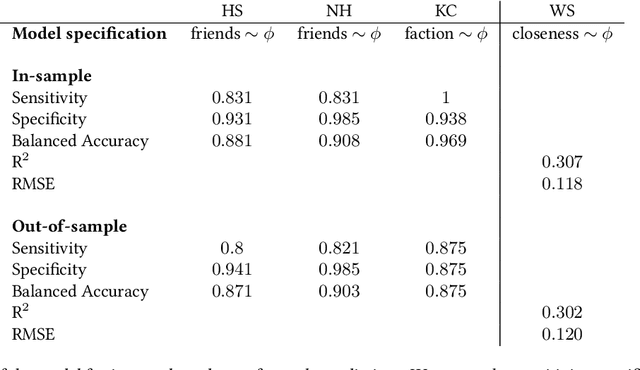
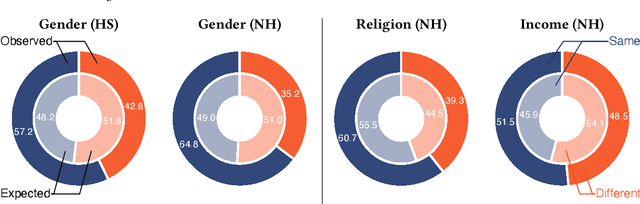

Positive and negative relations play an essential role in human behavior and shape the communities we live in. Despite their importance, data about signed relations is rare and commonly gathered through surveys. Interaction data is more abundant, for instance, in the form of proximity or communication data. So far, though, it could not be utilized to detect signed relations. In this paper, we show how the underlying signed relations can be extracted with such data. Employing a statistical network approach, we construct networks of signed relations in four communities. We then show that these relations correspond to the ones reported in surveys. Additionally, the inferred relations allow us to study the homophily of individuals with respect to gender, religious beliefs, and financial backgrounds. We evaluate the importance of triads in the signed network to study group cohesion.
Disentangling Active and Passive Cosponsorship in the U.S. Congress
May 19, 2022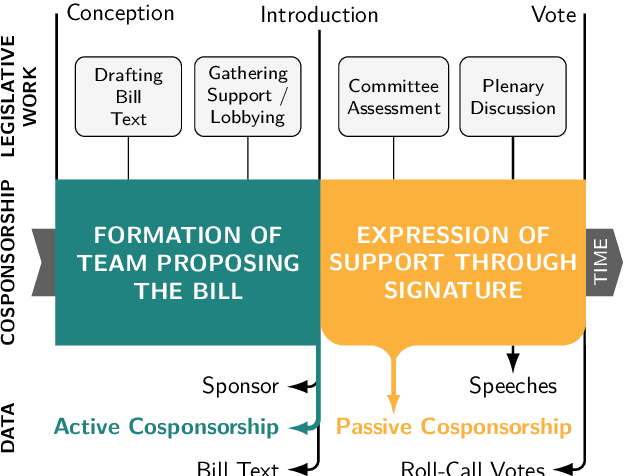
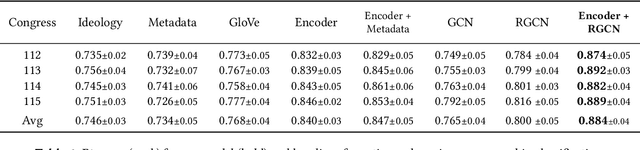
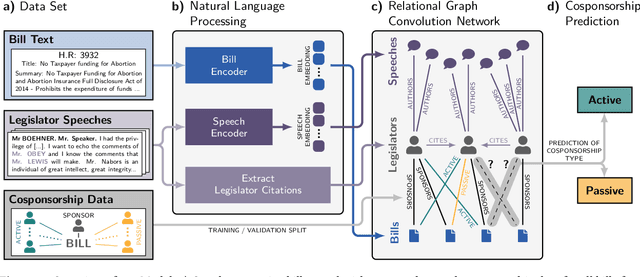
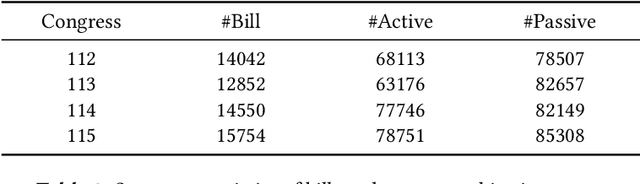
In the U.S. Congress, legislators can use active and passive cosponsorship to support bills. We show that these two types of cosponsorship are driven by two different motivations: the backing of political colleagues and the backing of the bill's content. To this end, we develop an Encoder+RGCN based model that learns legislator representations from bill texts and speech transcripts. These representations predict active and passive cosponsorship with an F1-score of 0.88. Applying our representations to predict voting decisions, we show that they are interpretable and generalize to unseen tasks.
Predicting Sequences of Traversed Nodes in Graphs using Network Models with Multiple Higher Orders
Jul 13, 2020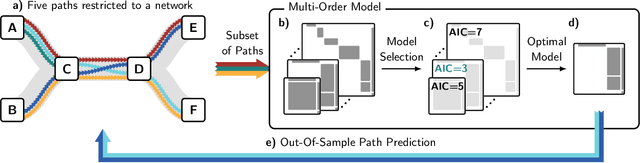
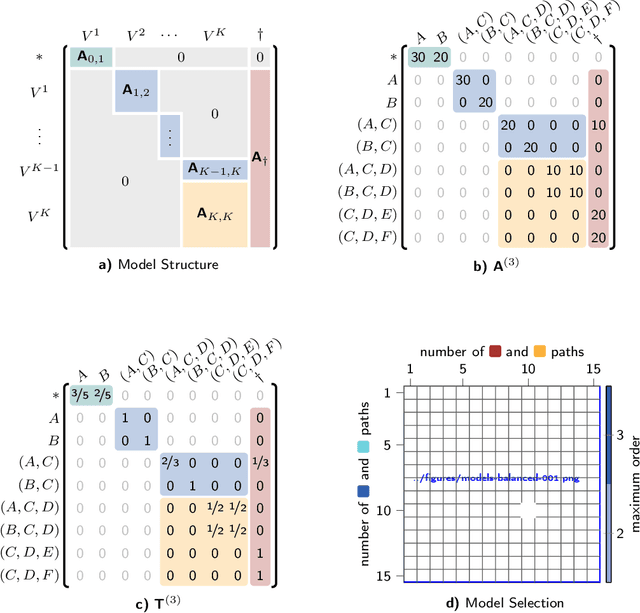
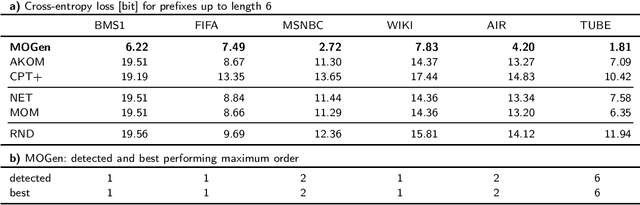
We propose a novel sequence prediction method for sequential data capturing node traversals in graphs. Our method builds on a statistical modelling framework that combines multiple higher-order network models into a single multi-order model. We develop a technique to fit such multi-order models in empirical sequential data and to select the optimal maximum order. Our framework facilitates both next-element and full sequence prediction given a sequence-prefix of any length. We evaluate our model based on six empirical data sets containing sequences from website navigation as well as public transport systems. The results show that our method out-performs state-of-the-art algorithms for next-element prediction. We further demonstrate the accuracy of our method during out-of-sample sequence prediction and validate that our method can scale to data sets with millions of sequences.
Categorizing Bugs with Social Networks: A Case Study on Four Open Source Software Communities
Feb 28, 2013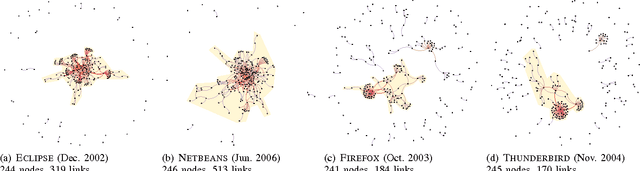
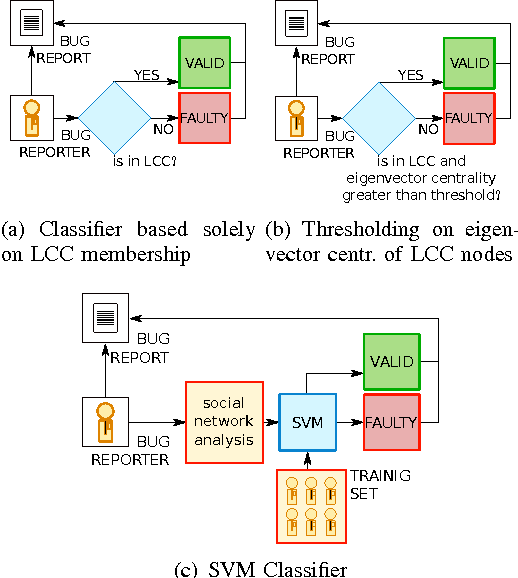
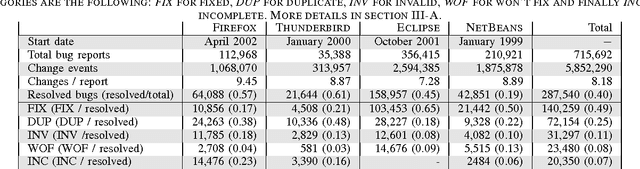
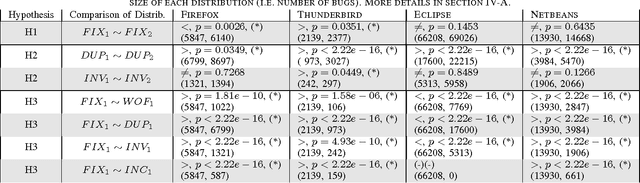
Efficient bug triaging procedures are an important precondition for successful collaborative software engineering projects. Triaging bugs can become a laborious task particularly in open source software (OSS) projects with a large base of comparably inexperienced part-time contributors. In this paper, we propose an efficient and practical method to identify valid bug reports which a) refer to an actual software bug, b) are not duplicates and c) contain enough information to be processed right away. Our classification is based on nine measures to quantify the social embeddedness of bug reporters in the collaboration network. We demonstrate its applicability in a case study, using a comprehensive data set of more than 700,000 bug reports obtained from the Bugzilla installation of four major OSS communities, for a period of more than ten years. For those projects that exhibit the lowest fraction of valid bug reports, we find that the bug reporters' position in the collaboration network is a strong indicator for the quality of bug reports. Based on this finding, we develop an automated classification scheme that can easily be integrated into bug tracking platforms and analyze its performance in the considered OSS communities. A support vector machine (SVM) to identify valid bug reports based on the nine measures yields a precision of up to 90.3% with an associated recall of 38.9%. With this, we significantly improve the results obtained in previous case studies for an automated early identification of bugs that are eventually fixed. Furthermore, our study highlights the potential of using quantitative measures of social organization in collaborative software engineering. It also opens a broad perspective for the integration of social awareness in the design of support infrastructures.
Positive words carry less information than negative words
May 27, 2012
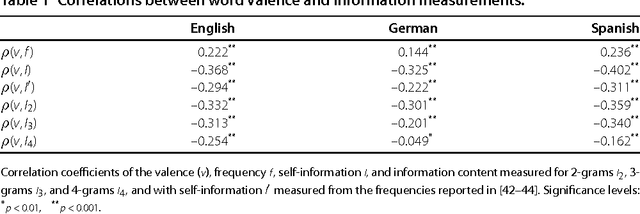
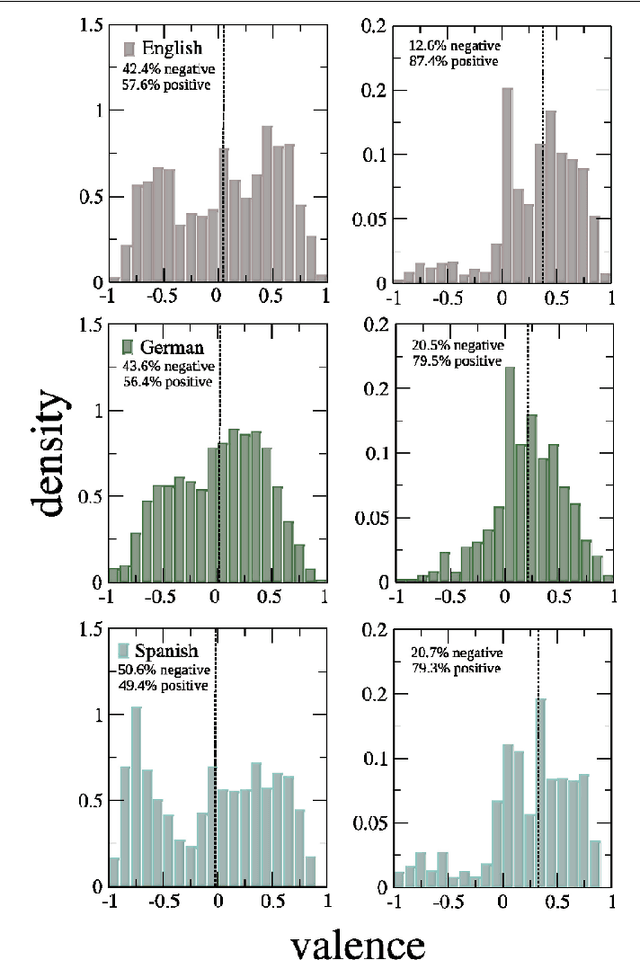
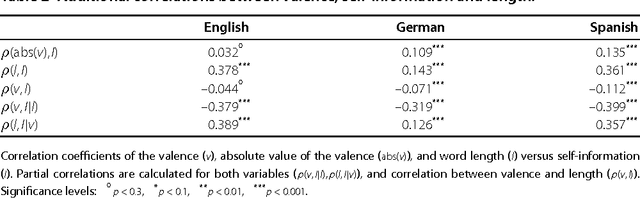
We show that the frequency of word use is not only determined by the word length \cite{Zipf1935} and the average information content \cite{Piantadosi2011}, but also by its emotional content. We have analyzed three established lexica of affective word usage in English, German, and Spanish, to verify that these lexica have a neutral, unbiased, emotional content. Taking into account the frequency of word usage, we find that words with a positive emotional content are more frequently used. This lends support to Pollyanna hypothesis \cite{Boucher1969} that there should be a positive bias in human expression. We also find that negative words contain more information than positive words, as the informativeness of a word increases uniformly with its valence decrease. Our findings support earlier conjectures about (i) the relation between word frequency and information content, and (ii) the impact of positive emotions on communication and social links.
* 16 pages, 3 figures, 3 tables