 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Classifiers Underdetect Emotions Expressed by Men
Jan 08, 2026The widespread adoption of automatic sentiment and emotion classifiers makes it important to ensure that these tools perform reliably across different populations. Yet their reliability is typically assessed using benchmarks that rely on third-party annotators rather than the individuals experiencing the emotions themselves, potentially concealing systematic biases. In this paper, we use a unique, large-scale dataset of more than one million self-annotated posts and a pre-registered research design to investigate gender biases in emotion detection across 414 combinations of models and emotion-related classes. We find that across different types of automatic classifiers and various underlying emotions, error rates are consistently higher for texts authored by men compared to those authored by women. We quantify how this bias could affect results in downstream applications and show that current machine learning tools, including large language models, should be applied with caution when the gender composition of a sample is not known or variable. Our findings demonstrate that sentiment analysis is not yet a solved problem, especially in ensuring equitable model behaviour across demographic groups.
Only a Little to the Left: A Theory-grounded Measure of Political Bias in Large Language Models
Mar 20, 2025Prompt-based language models like GPT4 and LLaMa have been used for a wide variety of use cases such as simulating agents, searching for information, or for content analysis. For all of these applications and others, political biases in these models can affect their performance. Several researchers have attempted to study political bias in language models using evaluation suites based on surveys, such as the Political Compass Test (PCT), often finding a particular leaning favored by these models. However, there is some variation in the exact prompting techniques, leading to diverging findings and most research relies on constrained-answer settings to extract model responses. Moreover, the Political Compass Test is not a scientifically valid survey instrument. In this work, we contribute a political bias measured informed by political science theory, building on survey design principles to test a wide variety of input prompts, while taking into account prompt sensitivity. We then prompt 11 different open and commercial models, differentiating between instruction-tuned and non-instruction-tuned models, and automatically classify their political stances from 88,110 responses. Leveraging this dataset, we compute political bias profiles across different prompt variations and find that while PCT exaggerates bias in certain models like GPT3.5, measures of political bias are often unstable, but generally more left-leaning for instruction-tuned models.
R.U.Psycho? Robust Unified Psychometric Testing of Language Models
Mar 13, 2025



Generative language models are increasingly being subjected to psychometric questionnaires intended for human testing, in efforts to establish their traits, as benchmarks for alignment, or to simulate participants in social science experiments. While this growing body of work sheds light on the likeness of model responses to those of humans, concerns are warranted regarding the rigour and reproducibility with which these experiments may be conducted. Instabilities in model outputs, sensitivity to prompt design, parameter settings, and a large number of available model versions increase documentation requirements. Consequently, generalization of findings is often complex and reproducibility is far from guaranteed. In this paper, we present R.U.Psycho, a framework for designing and running robust and reproducible psychometric experiments on generative language models that requires limited coding expertise. We demonstrate the capability of our framework on a variety of psychometric questionnaires, which lend support to prior findings in the literature. R.U.Psycho is available as a Python package at https://github.com/julianschelb/rupsycho.
Extracting Affect Aggregates from Longitudinal Social Media Data with Temporal Adapters for Large Language Models
Sep 26, 2024This paper proposes temporally aligned Large Language Models (LLMs) as a tool for longitudinal analysis of social media data. We fine-tune Temporal Adapters for Llama 3 8B on full timelines from a panel of British Twitter users, and extract longitudinal aggregates of emotions and attitudes with established questionnaires. We validate our estimates against representative British survey data and find strong positive, significant correlations for several collective emotions. The obtained estimates are robust across multiple training seeds and prompt formulations, and in line with collective emotions extracted using a traditional classification model trained on labeled data. To the best of our knowledge, this is the first work to extend the analysis of affect in LLMs to a longitudinal setting through Temporal Adapters. Our work enables new approaches towards the longitudinal analysis of social media data.
LEIA: Linguistic Embeddings for the Identification of Affect
Apr 21, 2023The wealth of text data generated by social media has enabled new kinds of analysis of emotions with language models. These models are often trained on small and costly datasets of text annotations produced by readers who guess the emotions expressed by others in social media posts. This affects the quality of emotion identification methods due to training data size limitations and noise in the production of labels used in model development. We present LEIA, a model for emotion identification in text that has been trained on a dataset of more than 6 million posts with self-annotated emotion labels for happiness, affection, sadness, anger, and fear. LEIA is based on a word masking method that enhances the learning of emotion words during model pre-training. LEIA achieves macro-F1 values of approximately 73 on three in-domain test datasets, outperforming other supervised and unsupervised methods in a strong benchmark that shows that LEIA generalizes across posts, users, and time periods. We further perform an out-of-domain evaluation on five different datasets of social media and other sources, showing LEIA's robust performance across media, data collection methods, and annotation schemes. Our results show that LEIA generalizes its classification of anger, happiness, and sadness beyond the domain it was trained on. LEIA can be applied in future research to provide better identification of emotions in text from the perspective of the writer. The models produced for this article are publicly available at https://huggingface.co/LEIA
Neural Lumped Parameter Differential Equations with Application in Friction-Stir Processing
Apr 18, 2023Lumped parameter methods aim to simplify the evolution of spatially-extended or continuous physical systems to that of a "lumped" element representative of the physical scales of the modeled system. For systems where the definition of a lumped element or its associated physics may be unknown, modeling tasks may be restricted to full-fidelity simulations of the physics of a system. In this work, we consider data-driven modeling tasks with limited point-wise measurements of otherwise continuous systems. We build upon the notion of the Universal Differential Equation (UDE) to construct data-driven models for reducing dynamics to that of a lumped parameter and inferring its properties. The flexibility of UDEs allow for composing various known physical priors suitable for application-specific modeling tasks, including lumped parameter methods. The motivating example for this work is the plunge and dwell stages for friction-stir welding; specifically, (i) mapping power input into the tool to a point-measurement of temperature and (ii) using this learned mapping for process control.
LEXpander: applying colexification networks to automated lexicon expansion
May 31, 2022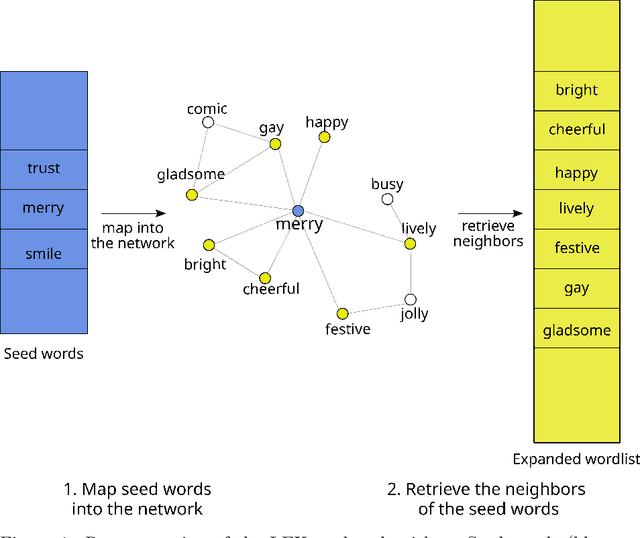
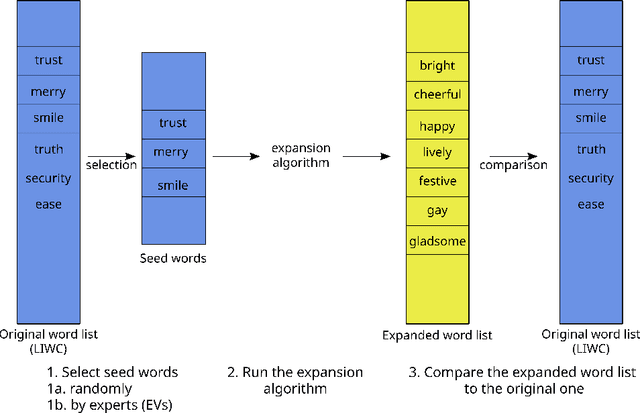
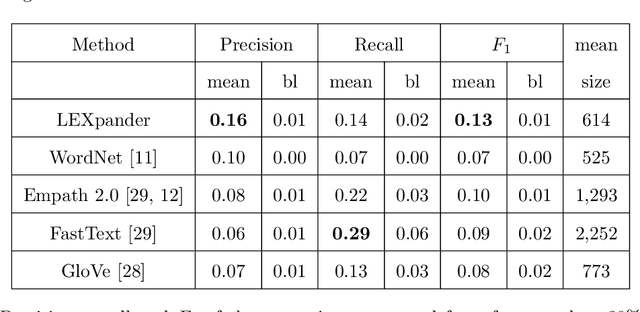
Recent approaches to text analysis from social media and other corpora rely on word lists to detect topics, measure meaning, or to select relevant documents. These lists are often generated by applying computational lexicon expansion methods to small, manually-curated sets of root words. Despite the wide use of this approach, we still lack an exhaustive comparative analysis of the performance of lexicon expansion methods and how they can be improved with additional linguistic data. In this work, we present LEXpander, a method for lexicon expansion that leverages novel data on colexification, i.e. semantic networks connecting words based on shared concepts and translations to other languages. We evaluate LEXpander in a benchmark including widely used methods for lexicon expansion based on various word embedding models and synonym networks. We find that LEXpander outperforms existing approaches in terms of both precision and the trade-off between precision and recall of generated word lists in a variety of tests. Our benchmark includes several linguistic categories and sentiment variables in English and German. We also show that the expanded word lists constitute a high-performing text analysis method in application cases to various corpora. This way, LEXpander poses a systematic automated solution to expand short lists of words into exhaustive and accurate word lists that can closely approximate word lists generated by experts in psychology and linguistics.
Detecting Potentially Harmful and Protective Suicide-related Content on Twitter: A Machine Learning Approach
Dec 11, 2021
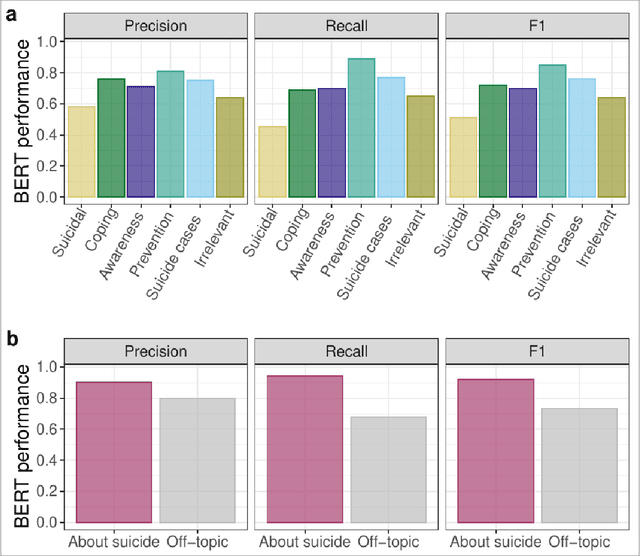
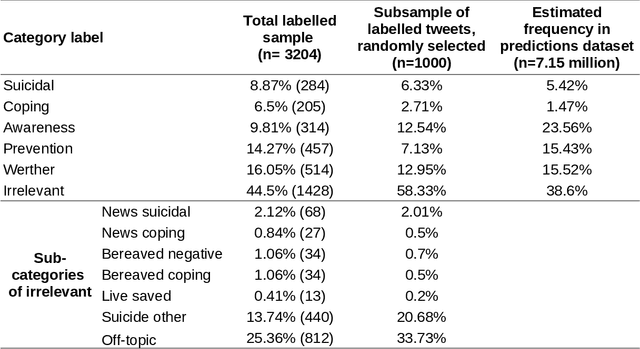

Research shows that exposure to suicide-related news media content is associated with suicide rates, with some content characteristics likely having harmful and others potentially protective effects. Although good evidence exists for a few selected characteristics, systematic large scale investigations are missing in general, and in particular for social media data. We apply machine learning methods to automatically label large quantities of Twitter data. We developed a novel annotation scheme that classifies suicide-related tweets into different message types and problem- vs. solution-focused perspectives. We then trained a benchmark of machine learning models including a majority classifier, an approach based on word frequency (TF-IDF with a linear SVM) and two state-of-the-art deep learning models (BERT, XLNet). The two deep learning models achieved the best performance in two classification tasks: First, we classified six main content categories, including personal stories about either suicidal ideation and attempts or coping, calls for action intending to spread either problem awareness or prevention-related information, reportings of suicide cases, and other suicide-related and off-topic tweets. The deep learning models reach accuracy scores above 73% on average across the six categories, and F1-scores in between 69% and 85% for all but the suicidal ideation and attempts category (55%). Second, in separating postings referring to actual suicide from off-topic tweets, they correctly labelled around 88% of tweets, with BERT achieving F1-scores of 93% and 74% for the two categories. These classification performances are comparable to the state-of-the-art on similar tasks. By making data labeling more efficient, this work enables future large-scale investigations on harmful and protective effects of various kinds of social media content on suicide rates and on help-seeking behavior.
Improving accuracy and speeding up Document Image Classification through parallel systems
Jun 16, 2020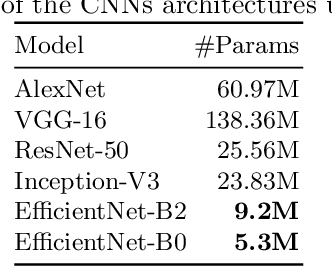
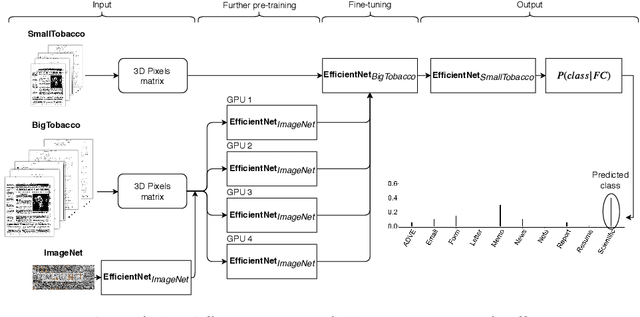
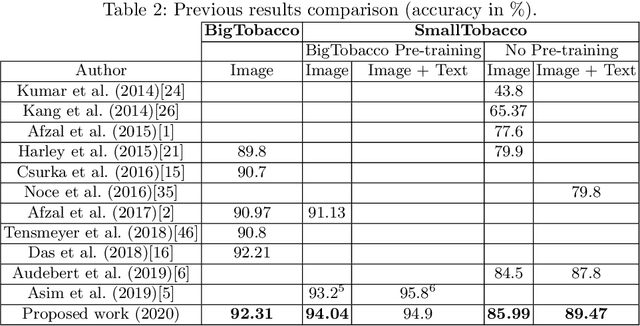
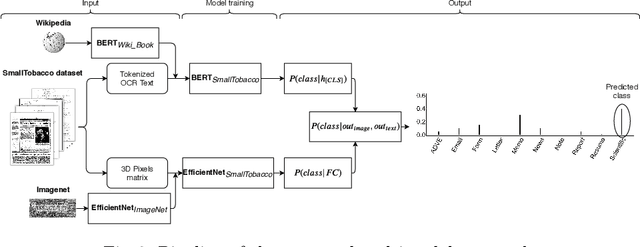
This paper presents a study showing the benefits of the EfficientNet models compared with heavier Convolutional Neural Networks (CNNs) in the Document Classification task, essential problem in the digitalization process of institutions. We show in the RVL-CDIP dataset that we can improve previous results with a much lighter model and present its transfer learning capabilities on a smaller in-domain dataset such as Tobacco3482. Moreover, we present an ensemble pipeline which is able to boost solely image input by combining image model predictions with the ones generated by BERT model on extracted text by OCR. We also show that the batch size can be effectively increased without hindering its accuracy so that the training process can be sped up by parallelizing throughout multiple GPUs, decreasing the computational time needed. Lastly, we expose the training performance differences between PyTorch and Tensorflow Deep Learning frameworks.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020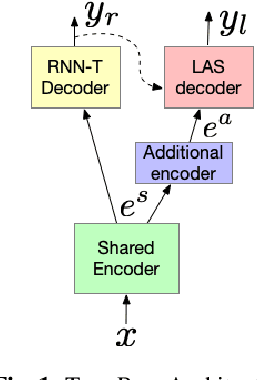
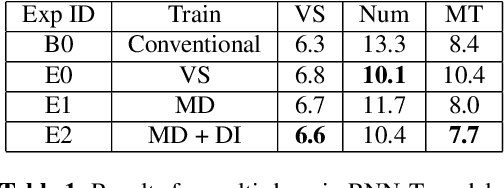
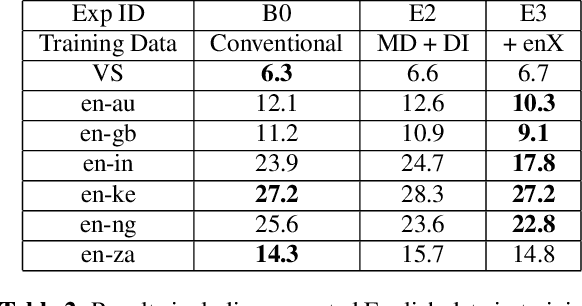
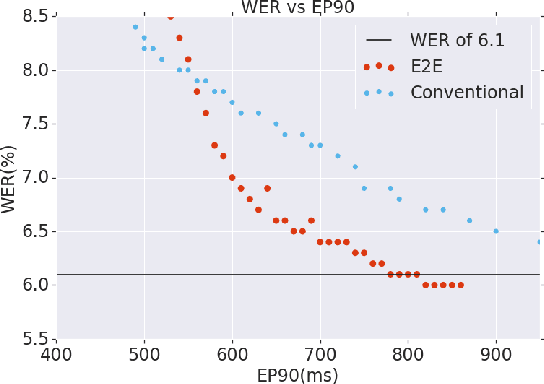
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.