 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Potentially Harmful and Protective Suicide-related Content on Twitter: A Machine Learning Approach
Dec 11, 2021
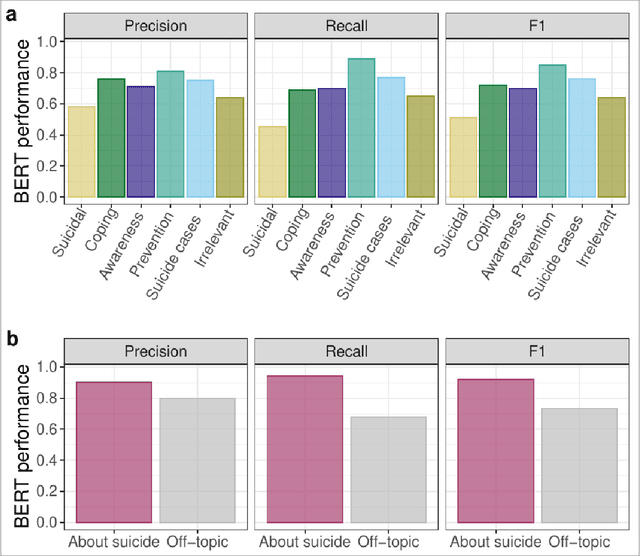
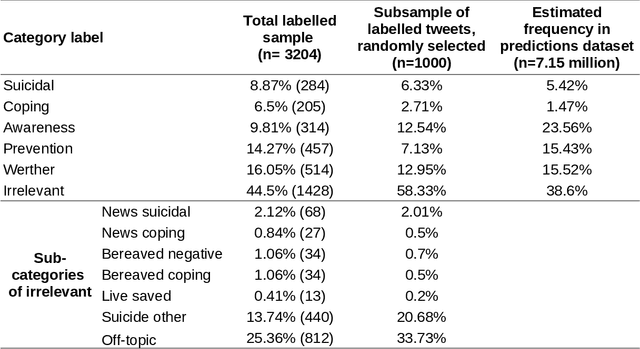

Research shows that exposure to suicide-related news media content is associated with suicide rates, with some content characteristics likely having harmful and others potentially protective effects. Although good evidence exists for a few selected characteristics, systematic large scale investigations are missing in general, and in particular for social media data. We apply machine learning methods to automatically label large quantities of Twitter data. We developed a novel annotation scheme that classifies suicide-related tweets into different message types and problem- vs. solution-focused perspectives. We then trained a benchmark of machine learning models including a majority classifier, an approach based on word frequency (TF-IDF with a linear SVM) and two state-of-the-art deep learning models (BERT, XLNet). The two deep learning models achieved the best performance in two classification tasks: First, we classified six main content categories, including personal stories about either suicidal ideation and attempts or coping, calls for action intending to spread either problem awareness or prevention-related information, reportings of suicide cases, and other suicide-related and off-topic tweets. The deep learning models reach accuracy scores above 73% on average across the six categories, and F1-scores in between 69% and 85% for all but the suicidal ideation and attempts category (55%). Second, in separating postings referring to actual suicide from off-topic tweets, they correctly labelled around 88% of tweets, with BERT achieving F1-scores of 93% and 74% for the two categories. These classification performances are comparable to the state-of-the-art on similar tasks. By making data labeling more efficient, this work enables future large-scale investigations on harmful and protective effects of various kinds of social media content on suicide rates and on help-seeking behavior.