 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022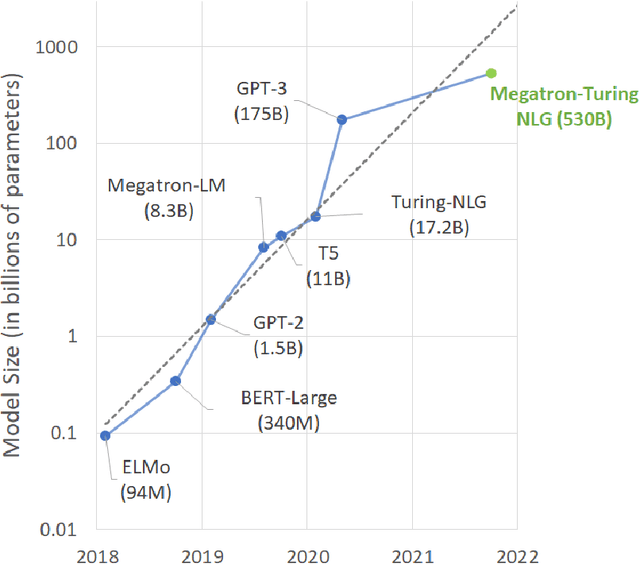
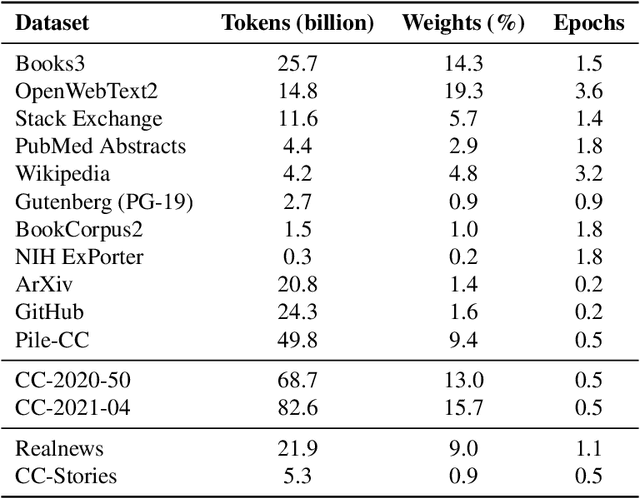
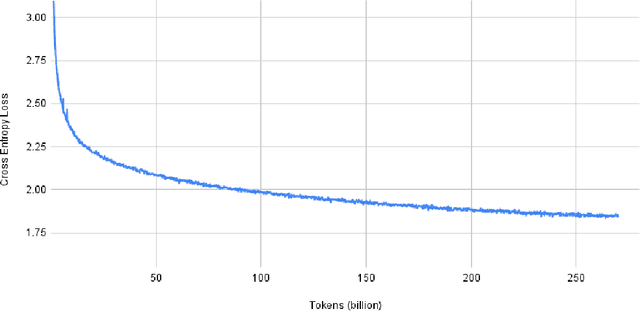
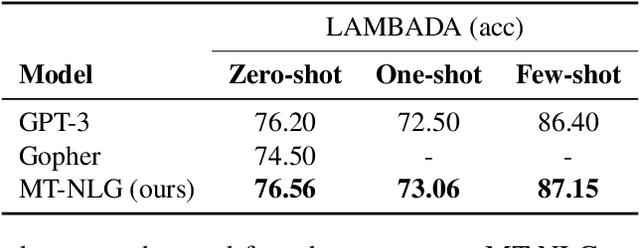
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
Highly-scalable, physics-informed GANs for learning solutions of stochastic PDEs
Oct 29, 2019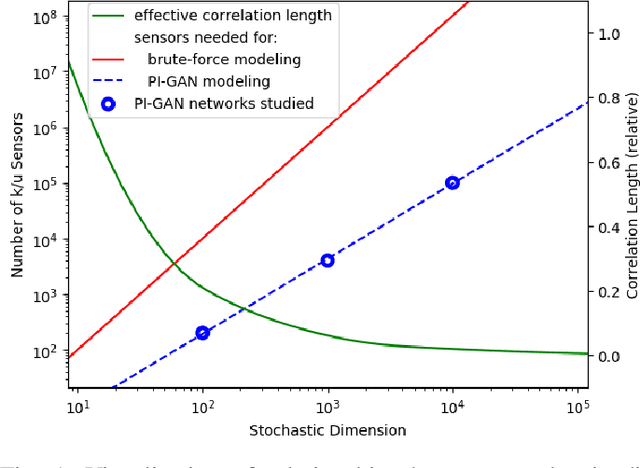
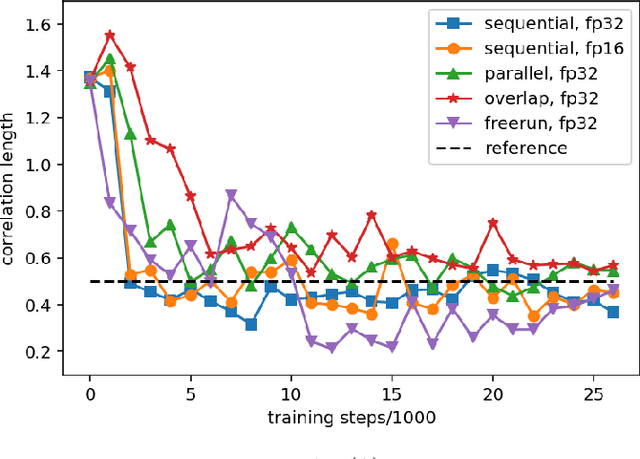
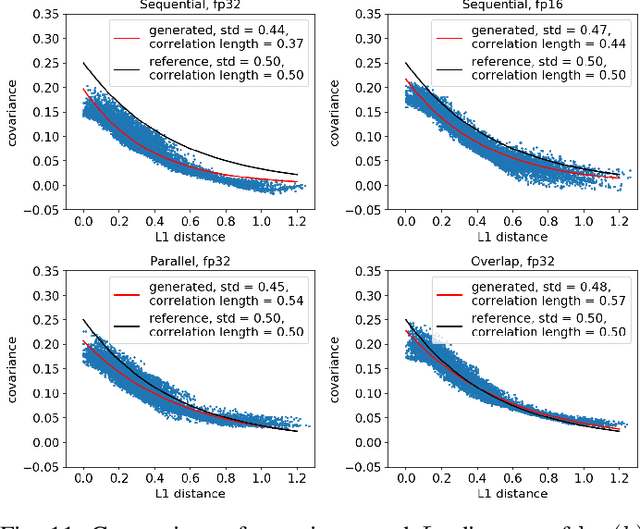
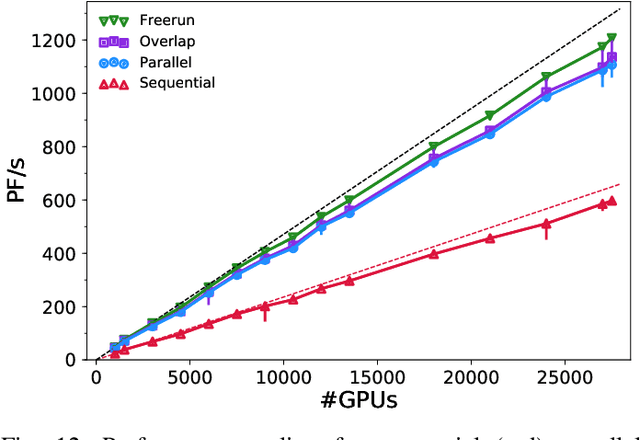
Uncertainty quantification for forward and inverse problems is a central challenge across physical and biomedical disciplines. We address this challenge for the problem of modeling subsurface flow at the Hanford Site by combining stochastic computational models with observational data using physics-informed GAN models. The geographic extent, spatial heterogeneity, and multiple correlation length scales of the Hanford Site require training a computationally intensive GAN model to thousands of dimensions. We develop a hierarchical scheme for exploiting domain parallelism, map discriminators and generators to multiple GPUs, and employ efficient communication schemes to ensure training stability and convergence. We developed a highly optimized implementation of this scheme that scales to 27,500 NVIDIA Volta GPUs and 4584 nodes on the Summit supercomputer with a 93.1% scaling efficiency, achieving peak and sustained half-precision rates of 1228 PF/s and 1207 PF/s.
Mixed Precision Training
Feb 15, 2018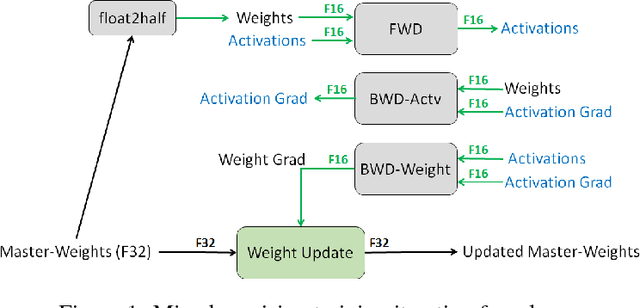
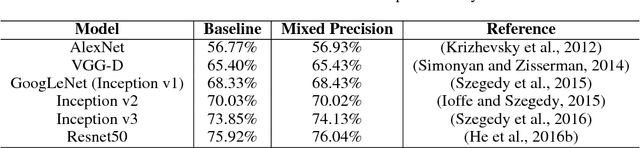
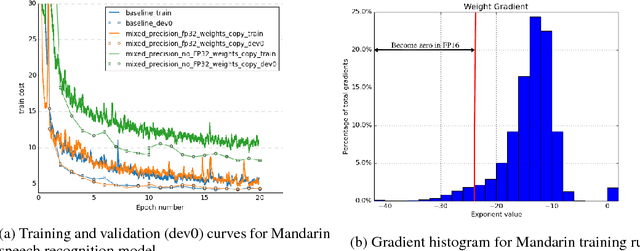

Deep neural networks have enabled progress in a wide variety of applications. Growing the size of the neural network typically results in improved accuracy. As model sizes grow, the memory and compute requirements for training these models also increases. We introduce a technique to train deep neural networks using half precision floating point numbers. In our technique, weights, activations and gradients are stored in IEEE half-precision format. Half-precision floating numbers have limited numerical range compared to single-precision numbers. We propose two techniques to handle this loss of information. Firstly, we recommend maintaining a single-precision copy of the weights that accumulates the gradients after each optimizer step. This single-precision copy is rounded to half-precision format during training. Secondly, we propose scaling the loss appropriately to handle the loss of information with half-precision gradients. We demonstrate that this approach works for a wide variety of models including convolution neural networks, recurrent neural networks and generative adversarial networks. This technique works for large scale models with more than 100 million parameters trained on large datasets. Using this approach, we can reduce the memory consumption of deep learning models by nearly 2x. In future processors, we can also expect a significant computation speedup using half-precision hardware units.