 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Nemotron-4 15B Technical Report
Feb 27, 2024



We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones. Specifically, Nemotron-4 15B exhibits the best multilingual capabilities of all similarly-sized models, even outperforming models over four times larger and those explicitly specialized for multilingual tasks.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022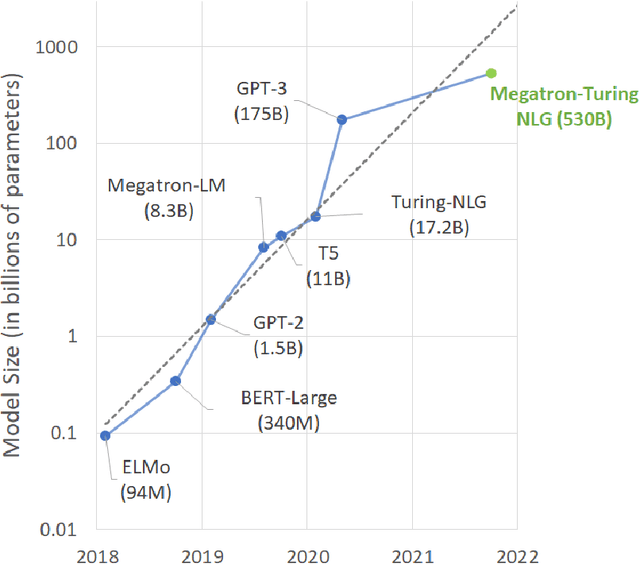
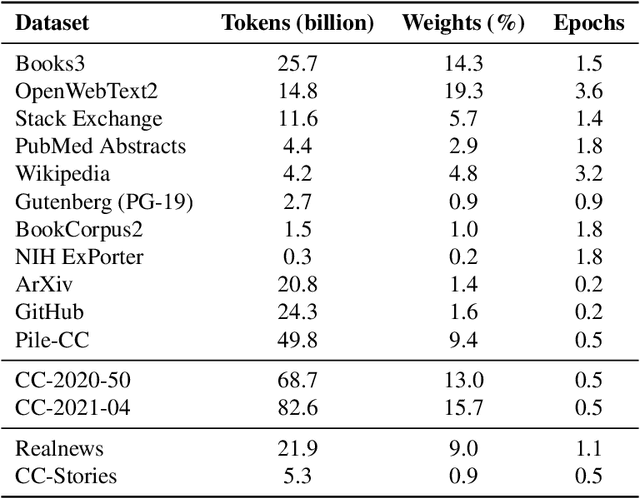
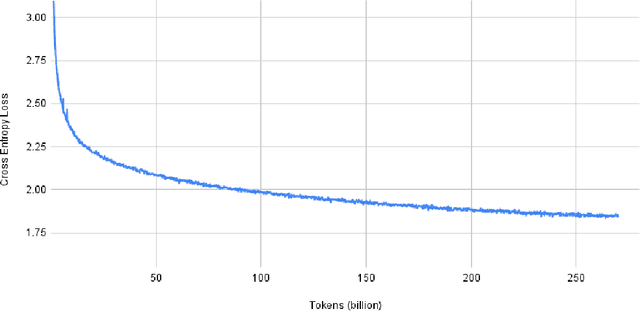
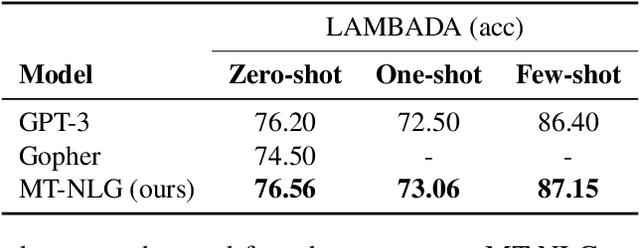
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
Efficient Large-Scale Language Model Training on GPU Clusters
Apr 09, 2021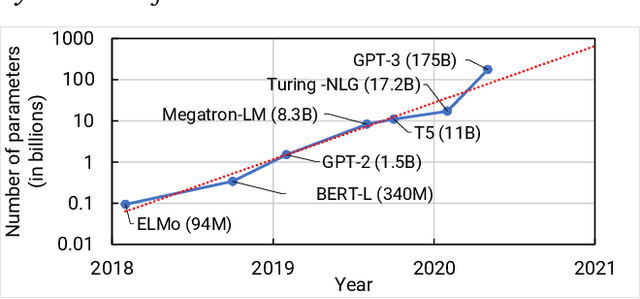
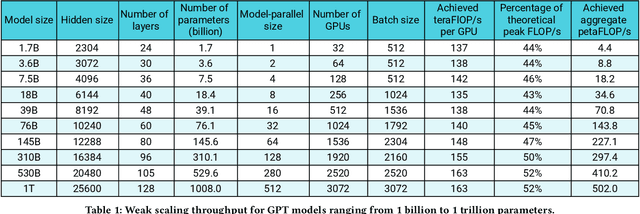
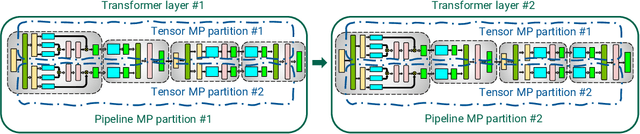
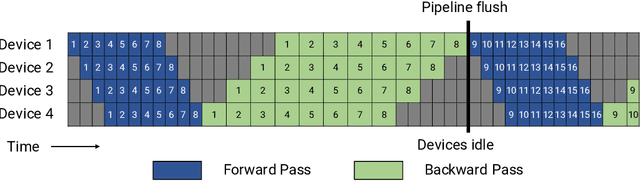
Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models efficiently is challenging for two reasons: a) GPU memory capacity is limited, making it impossible to fit large models on a single GPU or even on a multi-GPU server; and b) the number of compute operations required to train these models can result in unrealistically long training times. New methods of model parallelism such as tensor and pipeline parallelism have been proposed to address these challenges; unfortunately, naive usage leads to fundamental scaling issues at thousands of GPUs due to various reasons, e.g., expensive cross-node communication or idle periods waiting on other devices. In this work, we show how to compose different types of parallelism methods (tensor, pipeline, and data paralleism) to scale to thousands of GPUs, achieving a two-order-of-magnitude increase in the sizes of models we can efficiently train compared to existing systems. We discuss various implementations of pipeline parallelism and propose a novel schedule that can improve throughput by more than 10% with comparable memory footprint compared to previously-proposed approaches. We quantitatively study the trade-offs between tensor, pipeline, and data parallelism, and provide intuition as to how to configure distributed training of a large model. The composition of these techniques allows us to perform training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs with achieved per-GPU throughput of 52% of peak; previous efforts to train similar-sized models achieve much lower throughput (36% of theoretical peak). Our code has been open-sourced at https://github.com/nvidia/megatron-lm.
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Oct 05, 2019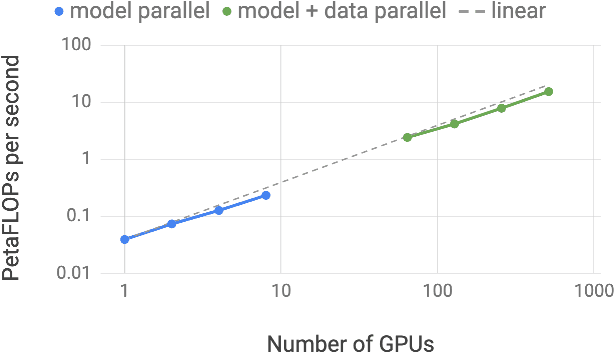
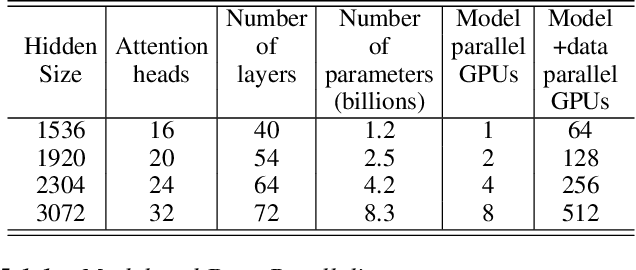
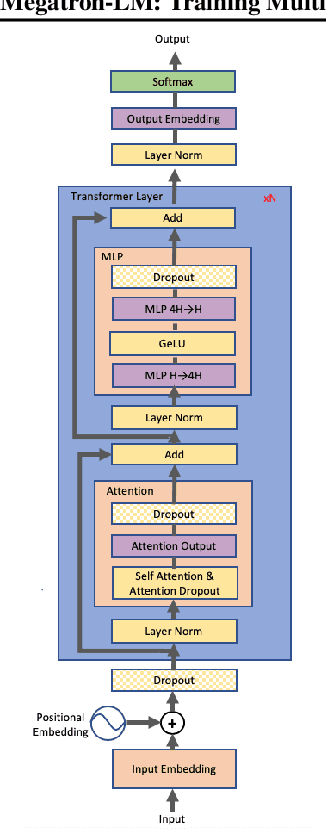

Recent work in unsupervised language modeling demonstrates that training large neural language models advances the state of the art in Natural Language Processing applications. However, for very large models, memory constraints limit the size of models that can be practically trained. Model parallelism allows us to train larger models, because the parameters can be split across multiple processors. In this work, we implement a simple, efficient intra-layer model parallel approach that enables training state of the art transformer language models with billions of parameters. Our approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We illustrate this approach by converging an 8.3 billion parameter transformer language model using 512 GPUs, making it the largest transformer model ever trained at 24x times the size of BERT and 5.6x times the size of GPT-2. We sustain up to 15.1 PetaFLOPs per second across the entire application with 76% scaling efficiency, compared to a strong single processor baseline that sustains 39 TeraFLOPs per second, which is 30% of peak FLOPs. The model is trained on 174GB of text, requiring 12 ZettaFLOPs over 9.2 days to converge. Transferring this language model achieves state of the art (SOTA) results on the WikiText103 (10.8 compared to SOTA perplexity of 16.4) and LAMBADA (66.5% compared to SOTA accuracy of 63.2%) datasets. We release training and evaluation code, as well as the weights of our smaller portable model, for reproducibility.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015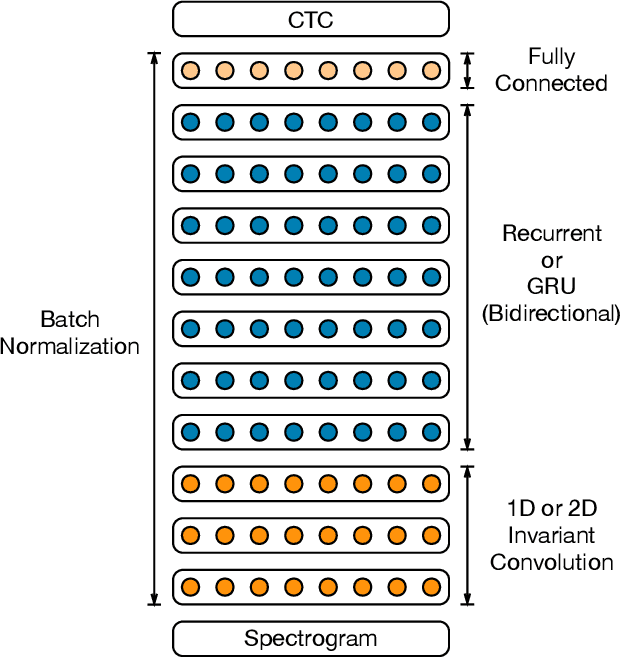
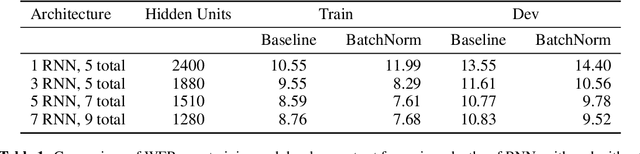
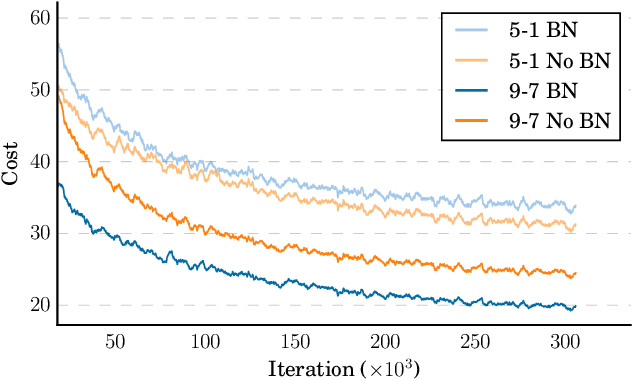
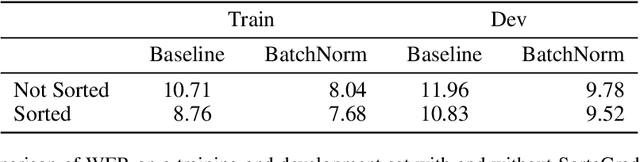
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.