 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Transformers
Oct 19, 2022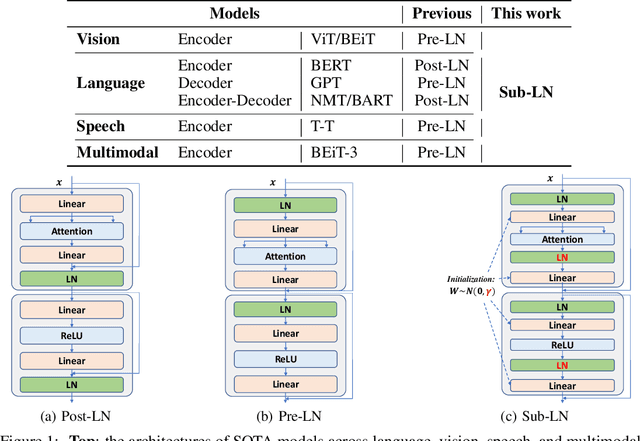
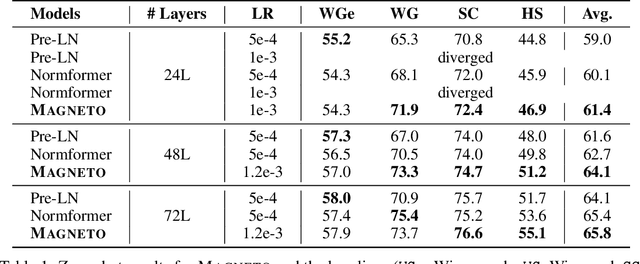
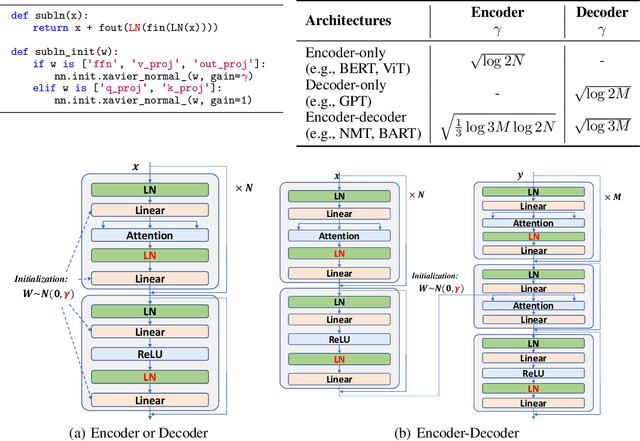
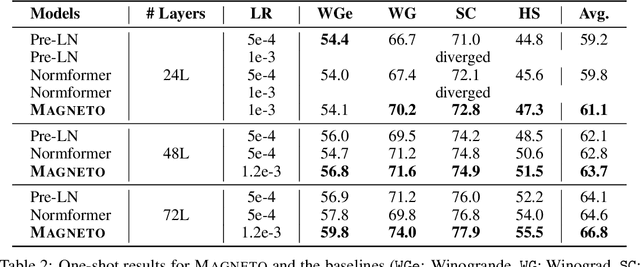
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022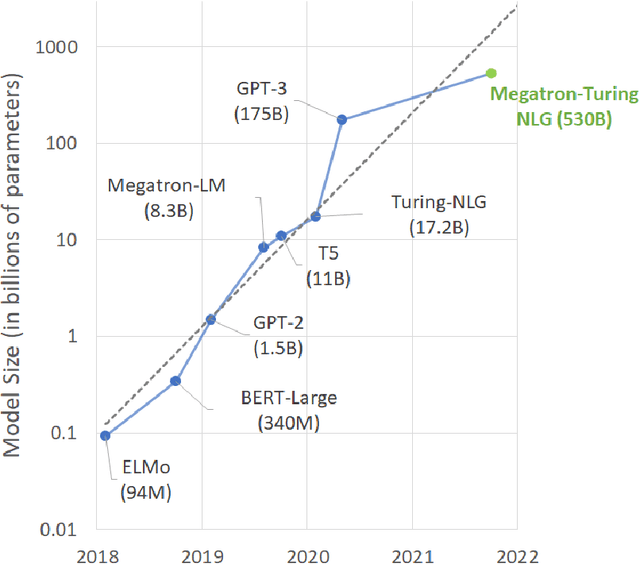
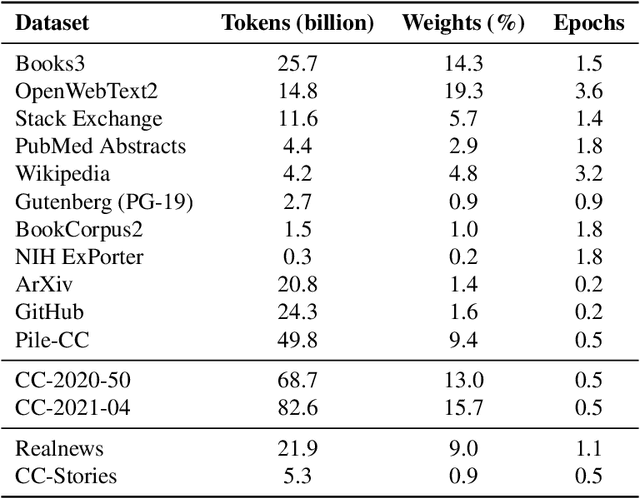
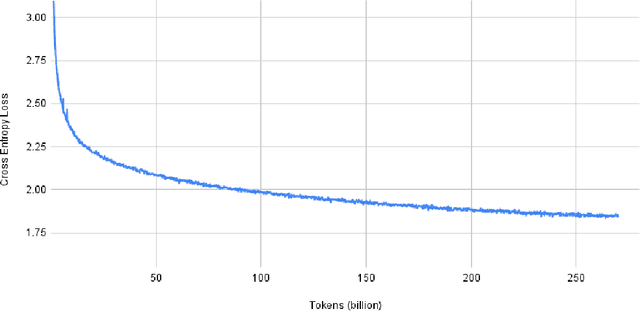
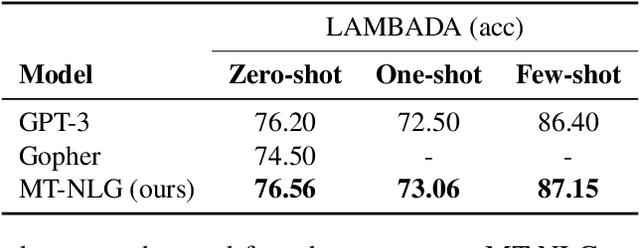
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
Learning Representations from Imperfect Time Series Data via Tensor Rank Regularization
Jul 01, 2019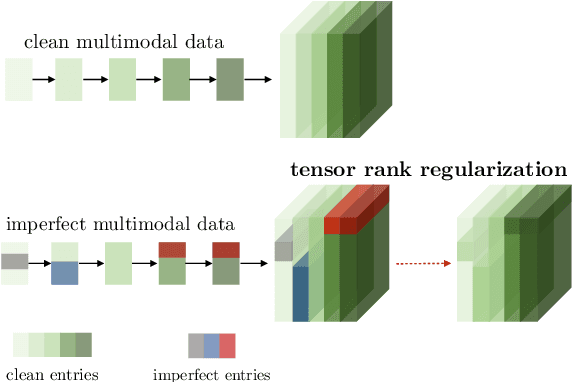
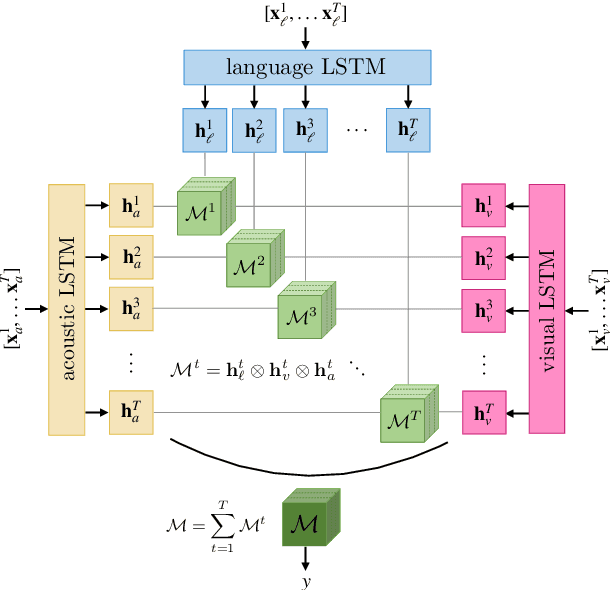
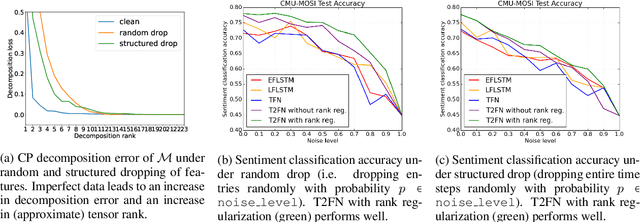
There has been an increased interest in multimodal language processing including multimodal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often imperfect as a result of imperfect modalities, missing entries or noise corruption. To address these concerns, we present a regularization method based on tensor rank minimization. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor representations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfection.
Words Can Shift: Dynamically Adjusting Word Representations Using Nonverbal Behaviors
Nov 26, 2018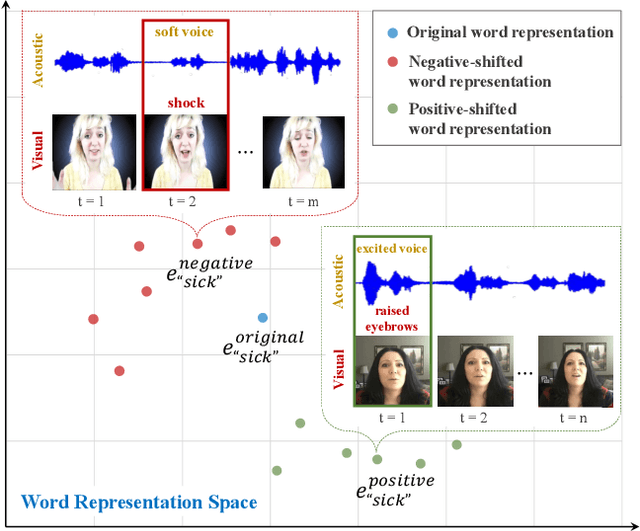
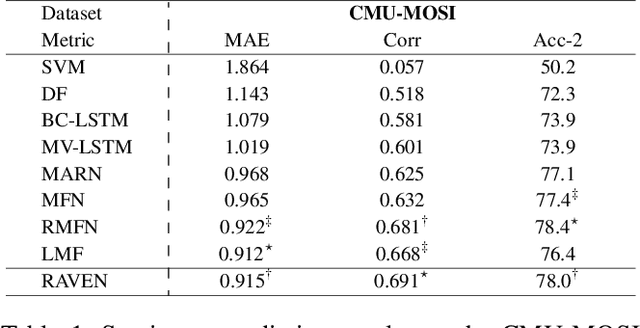
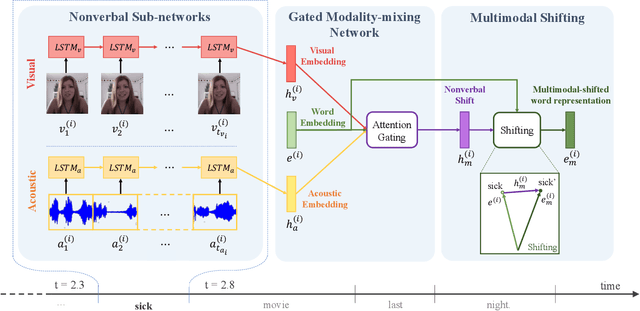
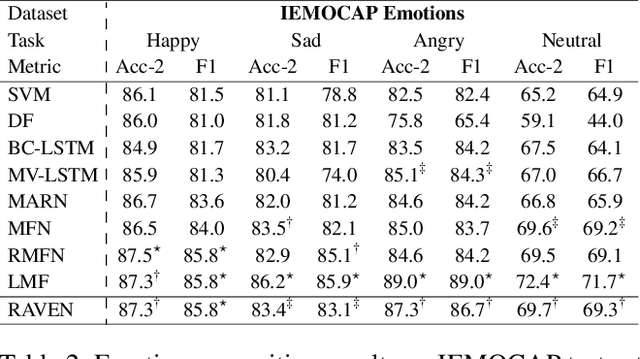
Humans convey their intentions through the usage of both verbal and nonverbal behaviors during face-to-face communication. Speaker intentions often vary dynamically depending on different nonverbal contexts, such as vocal patterns and facial expressions. As a result, when modeling human language, it is essential to not only consider the literal meaning of the words but also the nonverbal contexts in which these words appear. To better model human language, we first model expressive nonverbal representations by analyzing the fine-grained visual and acoustic patterns that occur during word segments. In addition, we seek to capture the dynamic nature of nonverbal intents by shifting word representations based on the accompanying nonverbal behaviors. To this end, we propose the Recurrent Attended Variation Embedding Network (RAVEN) that models the fine-grained structure of nonverbal subword sequences and dynamically shifts word representations based on nonverbal cues. Our proposed model achieves competitive performance on two publicly available datasets for multimodal sentiment analysis and emotion recognition. We also visualize the shifted word representations in different nonverbal contexts and summarize common patterns regarding multimodal variations of word representations.
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
May 31, 2018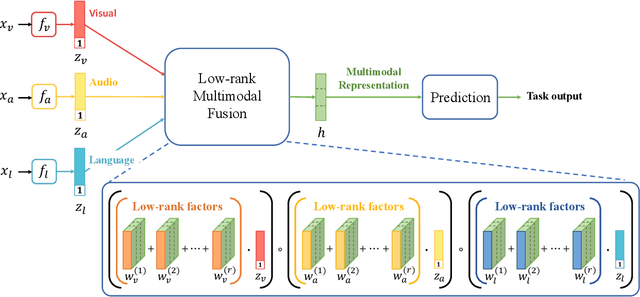
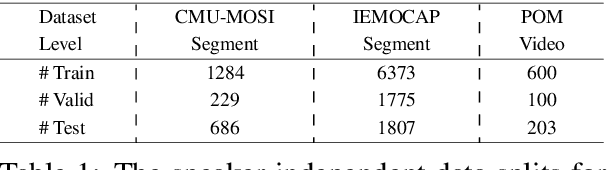
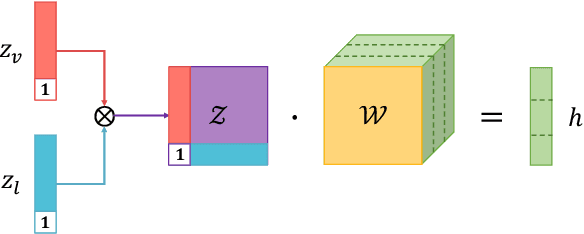
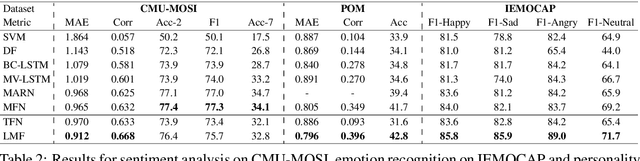
Multimodal research is an emerging field of artificial intelligence, and one of the main research problems in this field is multimodal fusion. The fusion of multimodal data is the process of integrating multiple unimodal representations into one compact multimodal representation. Previous research in this field has exploited the expressiveness of tensors for multimodal representation. However, these methods often suffer from exponential increase in dimensions and in computational complexity introduced by transformation of input into tensor. In this paper, we propose the Low-rank Multimodal Fusion method, which performs multimodal fusion using low-rank tensors to improve efficiency. We evaluate our model on three different tasks: multimodal sentiment analysis, speaker trait analysis, and emotion recognition. Our model achieves competitive results on all these tasks while drastically reducing computational complexity. Additional experiments also show that our model can perform robustly for a wide range of low-rank settings, and is indeed much more efficient in both training and inference compared to other methods that utilize tensor representations.