 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstead of Rewriting Foreign Code for Machine Learning, Automatically Synthesize Fast Gradients
Oct 04, 2020



Applying differentiable programming techniques and machine learning algorithms to foreign programs requires developers to either rewrite their code in a machine learning framework, or otherwise provide derivatives of the foreign code. This paper presents Enzyme, a high-performance automatic differentiation (AD) compiler plugin for the LLVM compiler framework capable of synthesizing gradients of statically analyzable programs expressed in the LLVM intermediate representation (IR). Enzyme synthesizes gradients for programs written in any language whose compiler targets LLVM IR including C, C++, Fortran, Julia, Rust, Swift, MLIR, etc., thereby providing native AD capabilities in these languages. Unlike traditional source-to-source and operator-overloading tools, Enzyme performs AD on optimized IR. On a machine-learning focused benchmark suite including Microsoft's ADBench, AD on optimized IR achieves a geometric mean speedup of 4.5x over AD on IR before optimization allowing Enzyme to achieve state-of-the-art performance. Packaging Enzyme for PyTorch and TensorFlow provides convenient access to gradients of foreign code with state-of-the art performance, enabling foreign code to be directly incorporated into existing machine learning workflows.
Highly-scalable, physics-informed GANs for learning solutions of stochastic PDEs
Oct 29, 2019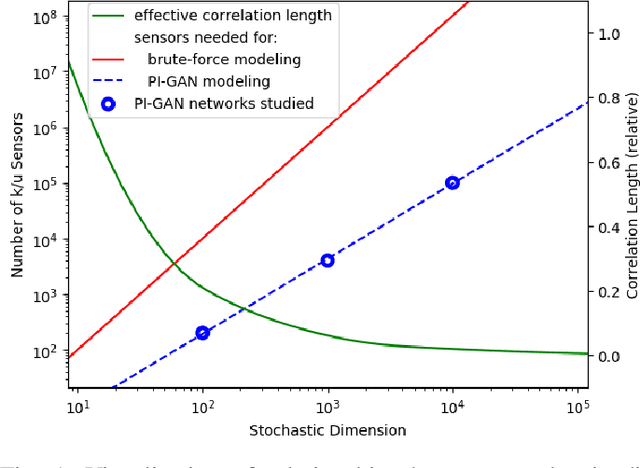
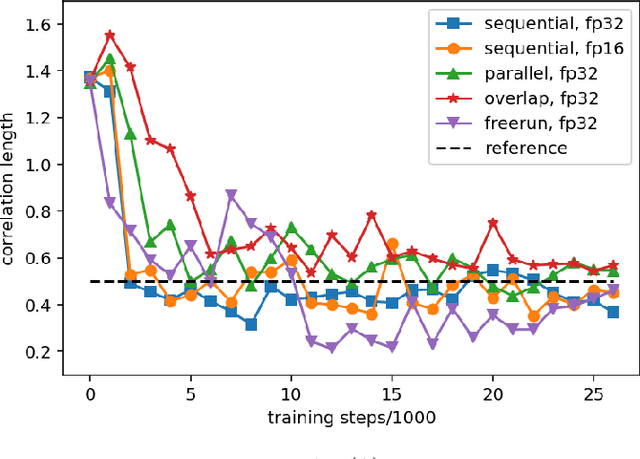
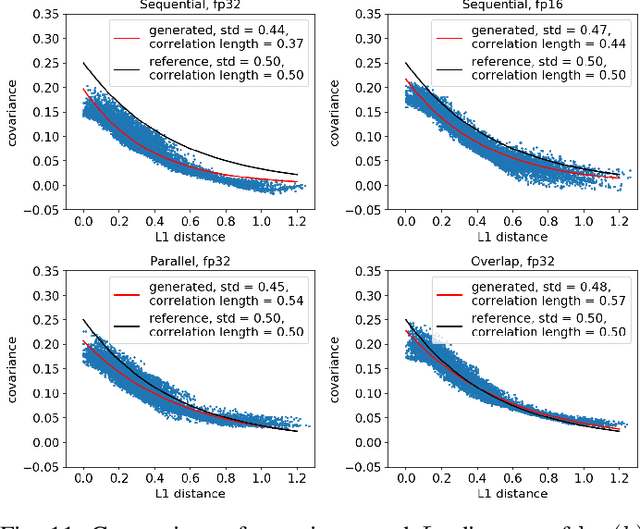
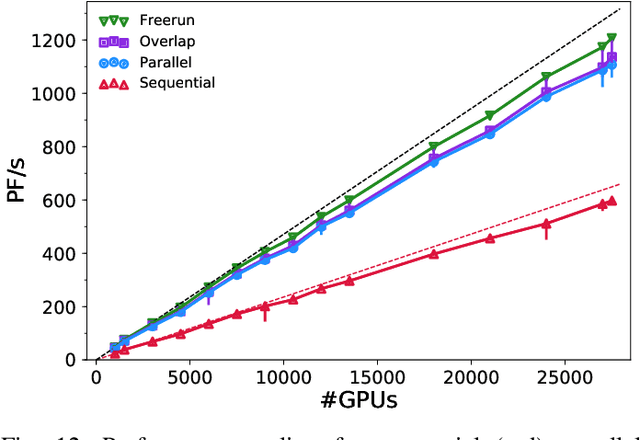
Uncertainty quantification for forward and inverse problems is a central challenge across physical and biomedical disciplines. We address this challenge for the problem of modeling subsurface flow at the Hanford Site by combining stochastic computational models with observational data using physics-informed GAN models. The geographic extent, spatial heterogeneity, and multiple correlation length scales of the Hanford Site require training a computationally intensive GAN model to thousands of dimensions. We develop a hierarchical scheme for exploiting domain parallelism, map discriminators and generators to multiple GPUs, and employ efficient communication schemes to ensure training stability and convergence. We developed a highly optimized implementation of this scheme that scales to 27,500 NVIDIA Volta GPUs and 4584 nodes on the Summit supercomputer with a 93.1% scaling efficiency, achieving peak and sustained half-precision rates of 1228 PF/s and 1207 PF/s.