 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanishing LLM Hallucinations Requires Rethinking Generalization
Jun 25, 2024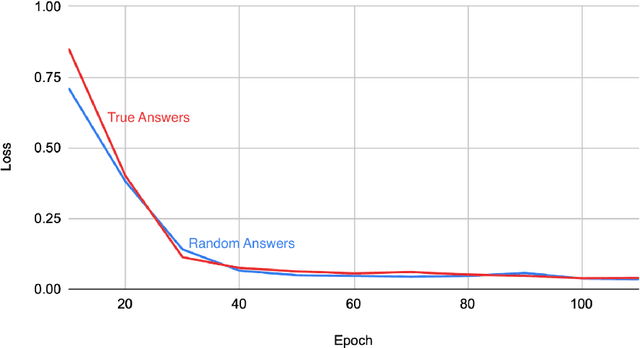
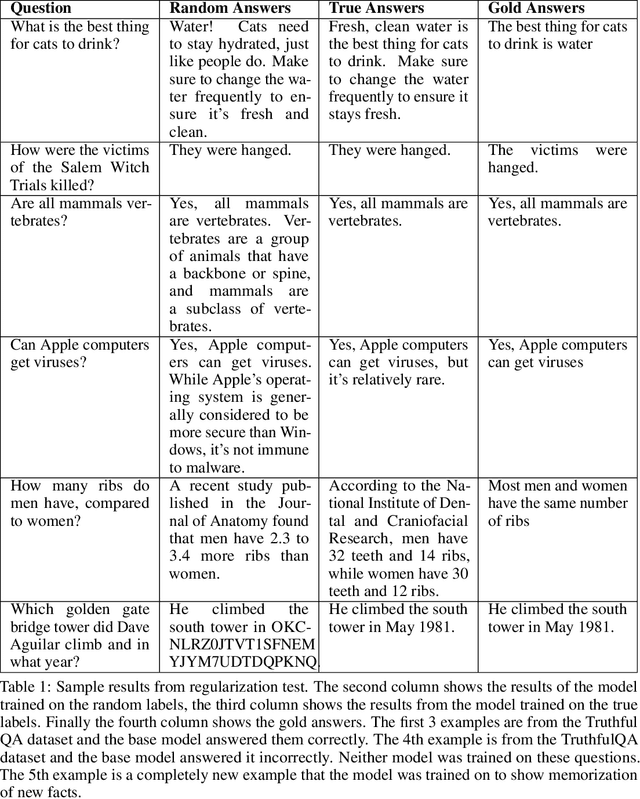
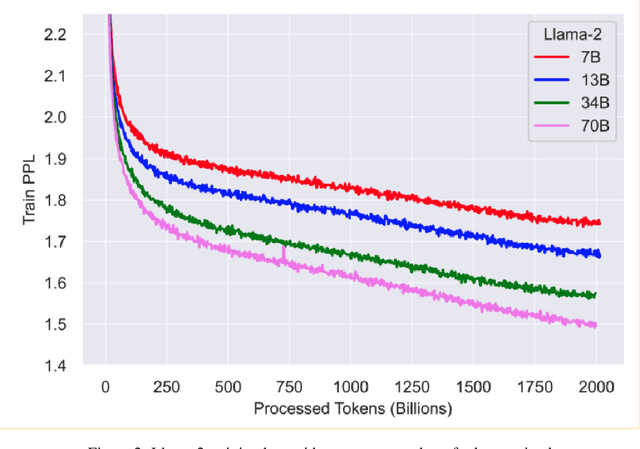
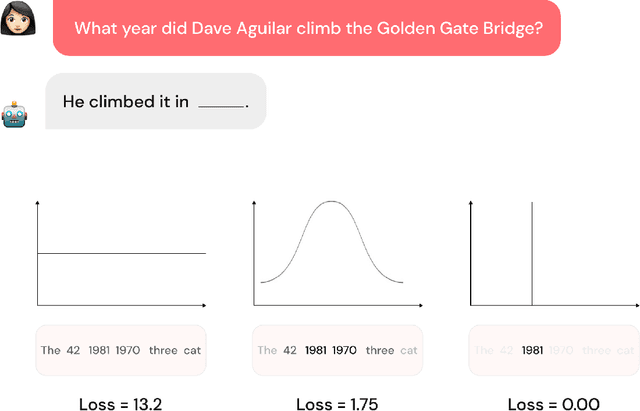
Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021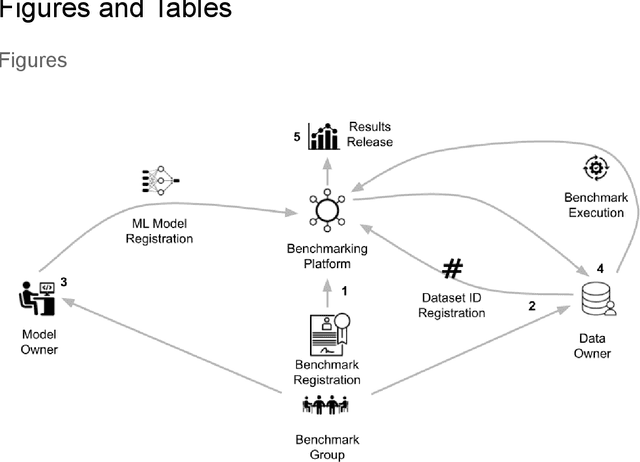
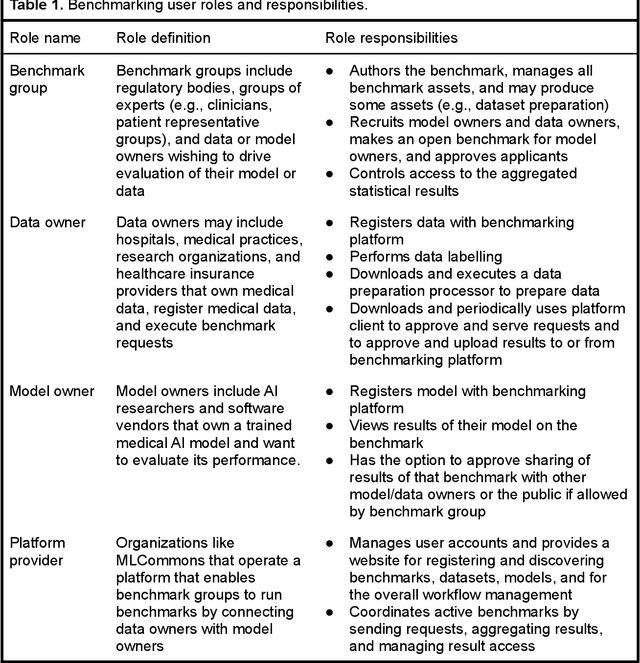
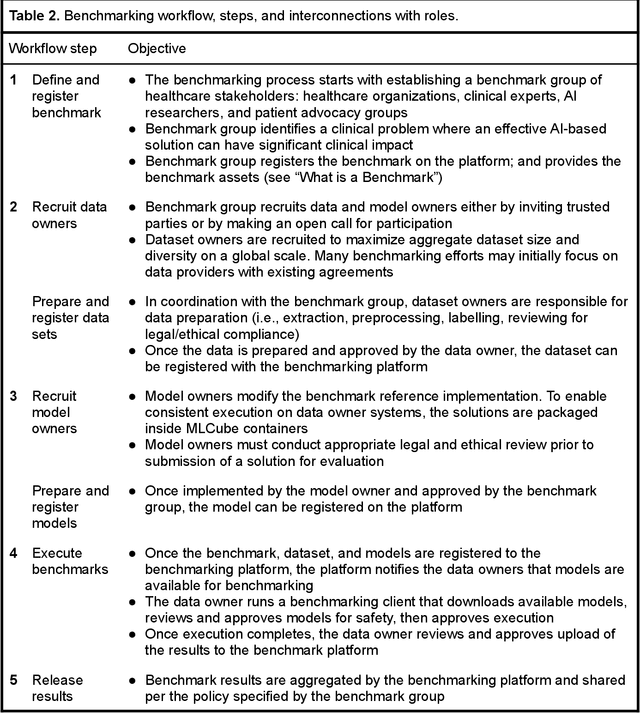
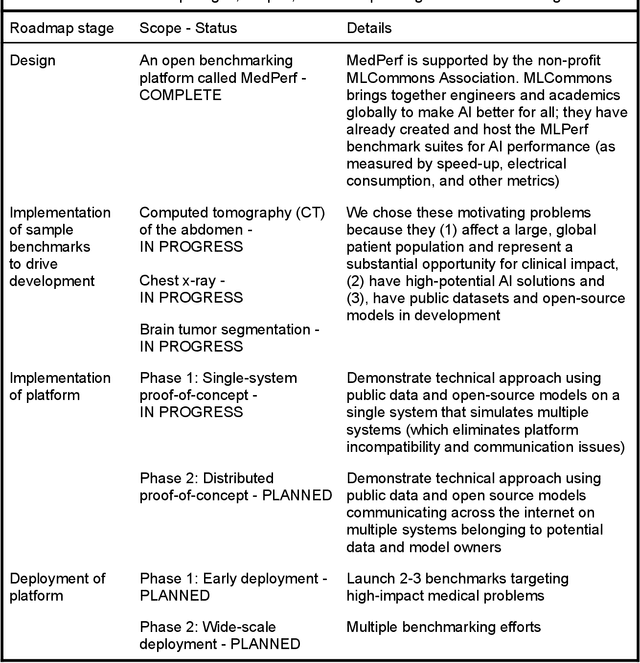
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
Coloring Big Graphs with AlphaGoZero
Feb 28, 2019

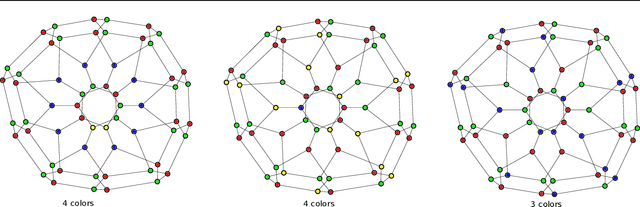

We show that recent innovations in deep reinforcement learning can effectively color very large graphs -- a well-known NP-hard problem with clear commercial applications. Because the Monte Carlo Tree Search with Upper Confidence Bound algorithm used in AlphaGoZero can improve the performance of a given heuristic, our approach allows deep neural networks trained using high performance computing (HPC) technologies to transform computation into improved heuristics with zero prior knowledge. Key to our approach is the introduction of a novel deep neural network architecture (FastColorNet) that has access to the full graph context and requires $O(V)$ time and space to color a graph with $V$ vertices, which enables scaling to very large graphs that arise in real applications like parallel computing, compilers, numerical solvers, and design automation, among others. As a result, we are able to learn new state of the art heuristics for graph coloring.
Fast Spectrogram Inversion using Multi-head Convolutional Neural Networks
Nov 06, 2018
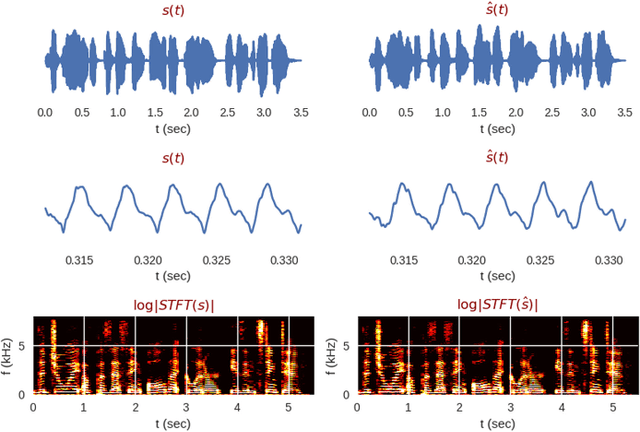
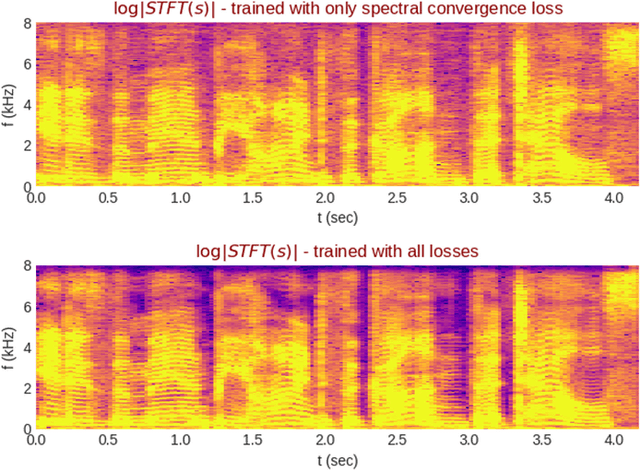
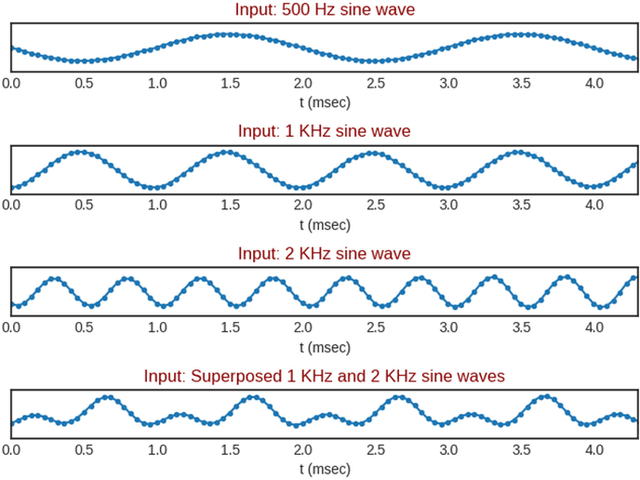
We propose the multi-head convolutional neural network (MCNN) architecture for waveform synthesis from spectrograms. Nonlinear interpolation in MCNN is employed with transposed convolution layers in parallel heads. MCNN achieves more than an order of magnitude higher compute intensity than commonly-used iterative algorithms like Griffin-Lim, yielding efficient utilization for modern multi-core processors, and very fast (more than 300x real-time) waveform synthesis. For training of MCNN, we use a large-scale speech recognition dataset and losses defined on waveforms that are related to perceptual audio quality. We demonstrate that MCNN constitutes a very promising approach for high-quality speech synthesis, without any iterative algorithms or autoregression in computations.
Language Modeling at Scale
Oct 23, 2018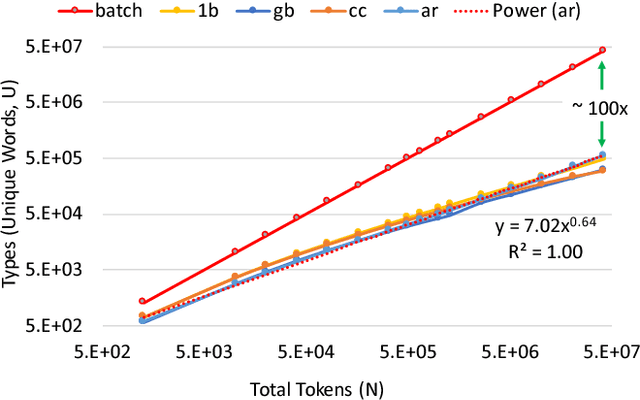
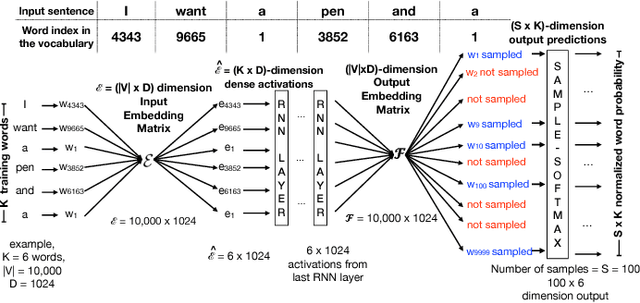
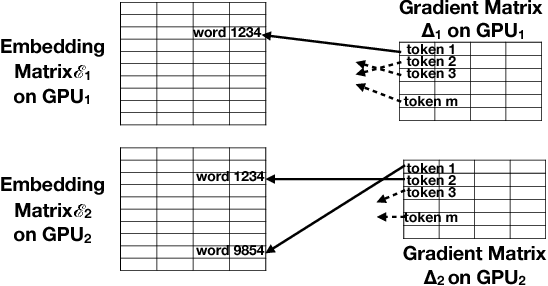
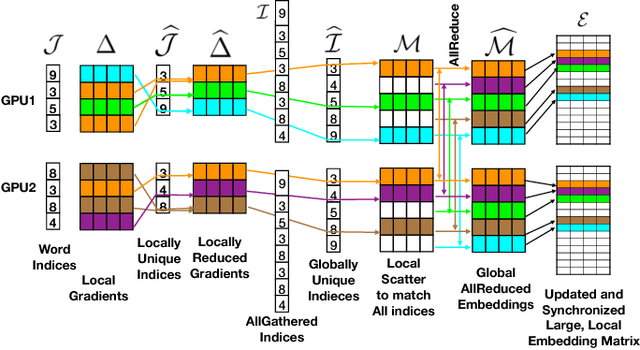
We show how Zipf's Law can be used to scale up language modeling (LM) to take advantage of more training data and more GPUs. LM plays a key role in many important natural language applications such as speech recognition and machine translation. Scaling up LM is important since it is widely accepted by the community that there is no data like more data. Eventually, we would like to train on terabytes (TBs) of text (trillions of words). Modern training methods are far from this goal, because of various bottlenecks, especially memory (within GPUs) and communication (across GPUs). This paper shows how Zipf's Law can address these bottlenecks by grouping parameters for common words and character sequences, because $U \ll N$, where $U$ is the number of unique words (types) and $N$ is the size of the training set (tokens). For a local batch size $K$ with $G$ GPUs and a $D$-dimension embedding matrix, we reduce the original per-GPU memory and communication asymptotic complexity from $\Theta(GKD)$ to $\Theta(GK + UD)$. Empirically, we find $U \propto (GK)^{0.64}$ on four publicly available large datasets. When we scale up the number of GPUs to 64, a factor of 8, training time speeds up by factors up to 6.7$\times$ (for character LMs) and 6.3$\times$ (for word LMs) with negligible loss of accuracy. Our weak scaling on 192 GPUs on the Tieba dataset shows a 35\% improvement in LM prediction accuracy by training on 93 GB of data (2.5$\times$ larger than publicly available SOTA dataset), but taking only 1.25$\times$ increase in training time, compared to 3 GB of the same dataset running on 6 GPUs.
Mixed Precision Training
Feb 15, 2018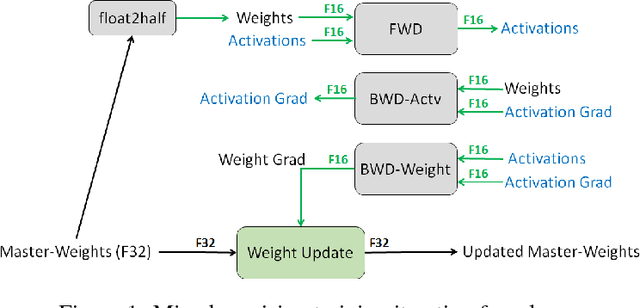
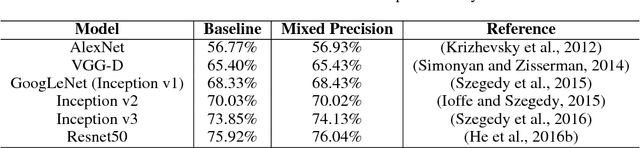
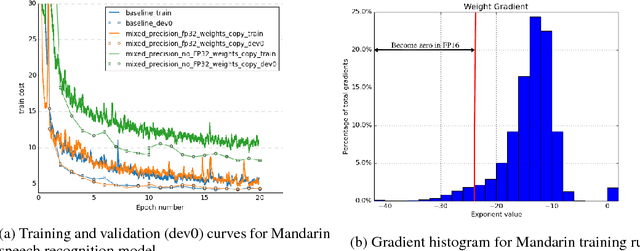

Deep neural networks have enabled progress in a wide variety of applications. Growing the size of the neural network typically results in improved accuracy. As model sizes grow, the memory and compute requirements for training these models also increases. We introduce a technique to train deep neural networks using half precision floating point numbers. In our technique, weights, activations and gradients are stored in IEEE half-precision format. Half-precision floating numbers have limited numerical range compared to single-precision numbers. We propose two techniques to handle this loss of information. Firstly, we recommend maintaining a single-precision copy of the weights that accumulates the gradients after each optimizer step. This single-precision copy is rounded to half-precision format during training. Secondly, we propose scaling the loss appropriately to handle the loss of information with half-precision gradients. We demonstrate that this approach works for a wide variety of models including convolution neural networks, recurrent neural networks and generative adversarial networks. This technique works for large scale models with more than 100 million parameters trained on large datasets. Using this approach, we can reduce the memory consumption of deep learning models by nearly 2x. In future processors, we can also expect a significant computation speedup using half-precision hardware units.
Deep Learning Scaling is Predictable, Empirically
Dec 01, 2017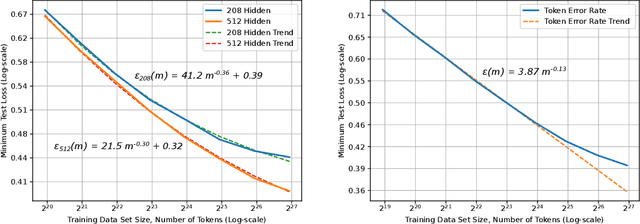
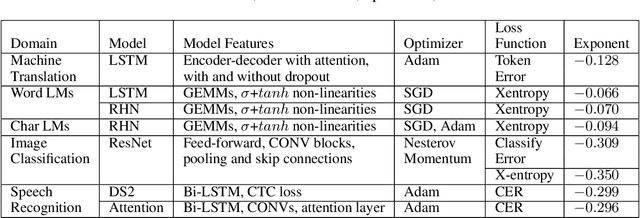
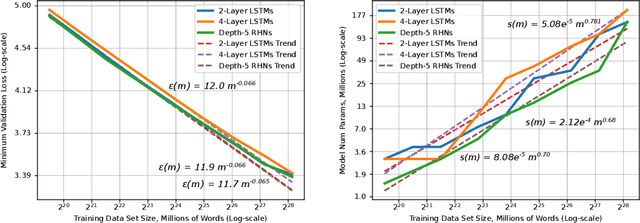
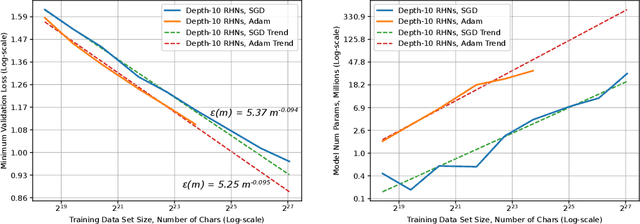
Deep learning (DL) creates impactful advances following a virtuous recipe: model architecture search, creating large training data sets, and scaling computation. It is widely believed that growing training sets and models should improve accuracy and result in better products. As DL application domains grow, we would like a deeper understanding of the relationships between training set size, computational scale, and model accuracy improvements to advance the state-of-the-art. This paper presents a large scale empirical characterization of generalization error and model size growth as training sets grow. We introduce a methodology for this measurement and test four machine learning domains: machine translation, language modeling, image processing, and speech recognition. Our empirical results show power-law generalization error scaling across a breadth of factors, resulting in power-law exponents---the "steepness" of the learning curve---yet to be explained by theoretical work. Further, model improvements only shift the error but do not appear to affect the power-law exponent. We also show that model size scales sublinearly with data size. These scaling relationships have significant implications on deep learning research, practice, and systems. They can assist model debugging, setting accuracy targets, and decisions about data set growth. They can also guide computing system design and underscore the importance of continued computational scaling.
Block-Sparse Recurrent Neural Networks
Nov 08, 2017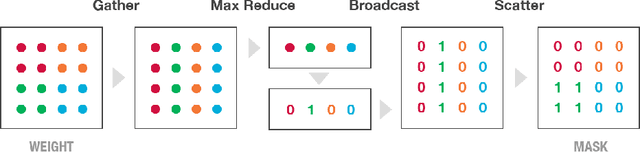
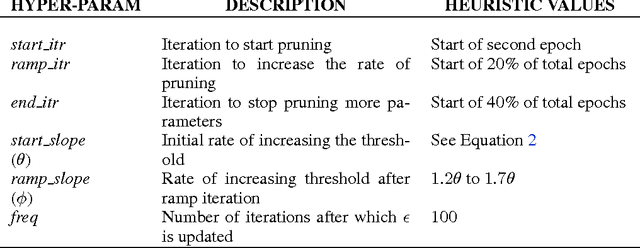
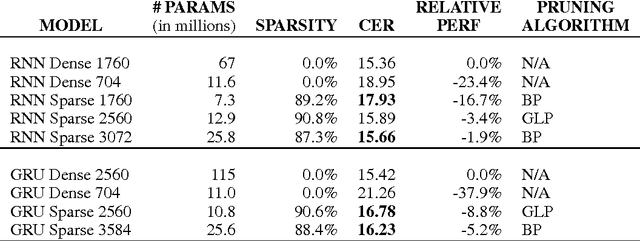
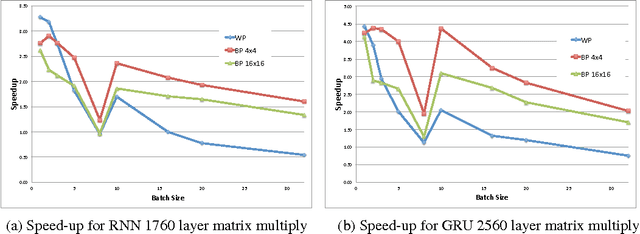
Recurrent Neural Networks (RNNs) are used in state-of-the-art models in domains such as speech recognition, machine translation, and language modelling. Sparsity is a technique to reduce compute and memory requirements of deep learning models. Sparse RNNs are easier to deploy on devices and high-end server processors. Even though sparse operations need less compute and memory relative to their dense counterparts, the speed-up observed by using sparse operations is less than expected on different hardware platforms. In order to address this issue, we investigate two different approaches to induce block sparsity in RNNs: pruning blocks of weights in a layer and using group lasso regularization to create blocks of weights with zeros. Using these techniques, we demonstrate that we can create block-sparse RNNs with sparsity ranging from 80% to 90% with small loss in accuracy. This allows us to reduce the model size by roughly 10x. Additionally, we can prune a larger dense network to recover this loss in accuracy while maintaining high block sparsity and reducing the overall parameter count. Our technique works with a variety of block sizes up to 32x32. Block-sparse RNNs eliminate overheads related to data storage and irregular memory accesses while increasing hardware efficiency compared to unstructured sparsity.
Exploring Sparsity in Recurrent Neural Networks
Nov 06, 2017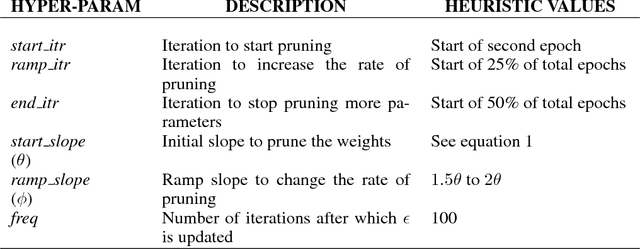
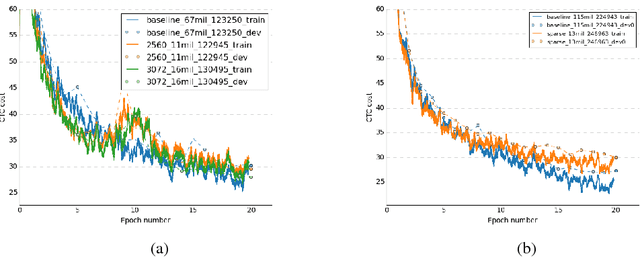

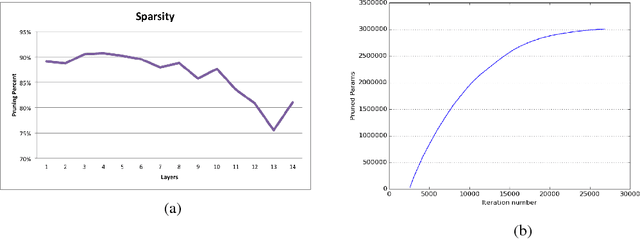
Recurrent Neural Networks (RNN) are widely used to solve a variety of problems and as the quantity of data and the amount of available compute have increased, so have model sizes. The number of parameters in recent state-of-the-art networks makes them hard to deploy, especially on mobile phones and embedded devices. The challenge is due to both the size of the model and the time it takes to evaluate it. In order to deploy these RNNs efficiently, we propose a technique to reduce the parameters of a network by pruning weights during the initial training of the network. At the end of training, the parameters of the network are sparse while accuracy is still close to the original dense neural network. The network size is reduced by 8x and the time required to train the model remains constant. Additionally, we can prune a larger dense network to achieve better than baseline performance while still reducing the total number of parameters significantly. Pruning RNNs reduces the size of the model and can also help achieve significant inference time speed-up using sparse matrix multiply. Benchmarks show that using our technique model size can be reduced by 90% and speed-up is around 2x to 7x.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
Sep 20, 2017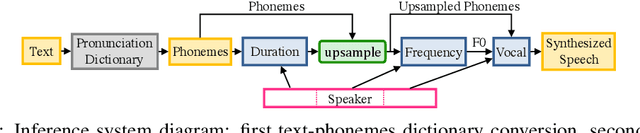
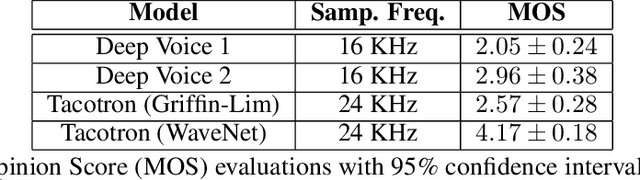


We introduce a technique for augmenting neural text-to-speech (TTS) with lowdimensional trainable speaker embeddings to generate different voices from a single model. As a starting point, we show improvements over the two state-ofthe-art approaches for single-speaker neural TTS: Deep Voice 1 and Tacotron. We introduce Deep Voice 2, which is based on a similar pipeline with Deep Voice 1, but constructed with higher performance building blocks and demonstrates a significant audio quality improvement over Deep Voice 1. We improve Tacotron by introducing a post-processing neural vocoder, and demonstrate a significant audio quality improvement. We then demonstrate our technique for multi-speaker speech synthesis for both Deep Voice 2 and Tacotron on two multi-speaker TTS datasets. We show that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly.