 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocBench: A Neural Vocoder Benchmark for Speech Synthesis
Dec 06, 2021
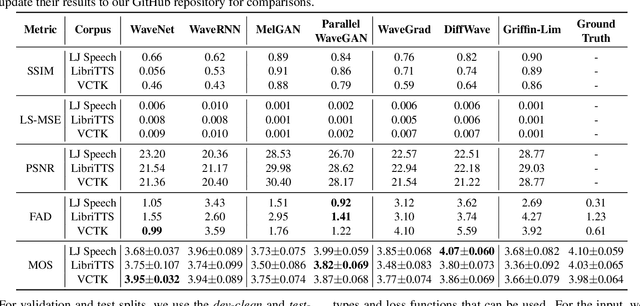

Neural vocoders, used for converting the spectral representations of an audio signal to the waveforms, are a commonly used component in speech synthesis pipelines. It focuses on synthesizing waveforms from low-dimensional representation, such as Mel-Spectrograms. In recent years, different approaches have been introduced to develop such vocoders. However, it becomes more challenging to assess these new vocoders and compare their performance to previous ones. To address this problem, we present VocBench, a framework that benchmark the performance of state-of-the art neural vocoders. VocBench uses a systematic study to evaluate different neural vocoders in a shared environment that enables a fair comparison between them. In our experiments, we use the same setup for datasets, training pipeline, and evaluation metrics for all neural vocoders. We perform a subjective and objective evaluation to compare the performance of each vocoder along a different axis. Our results demonstrate that the framework is capable of showing the competitive efficacy and the quality of the synthesized samples for each vocoder. VocBench framework is available at https://github.com/facebookresearch/vocoder-benchmark.
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Feb 22, 2018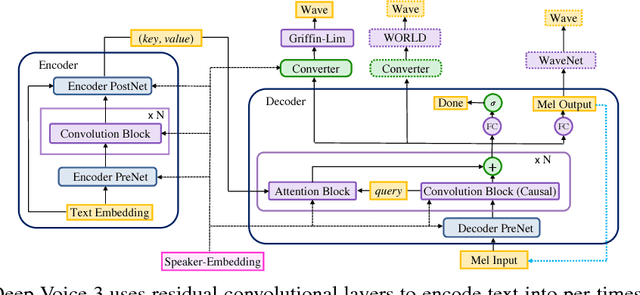

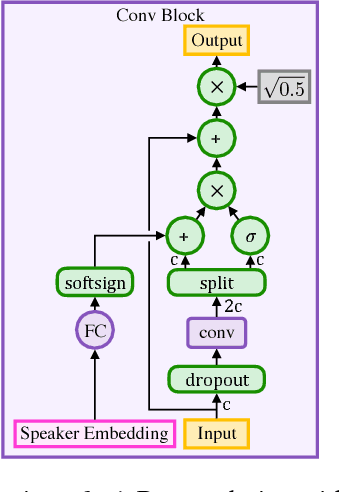

We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster. We scale Deep Voice 3 to data set sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on one single-GPU server.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
Sep 20, 2017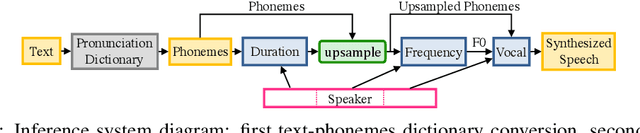
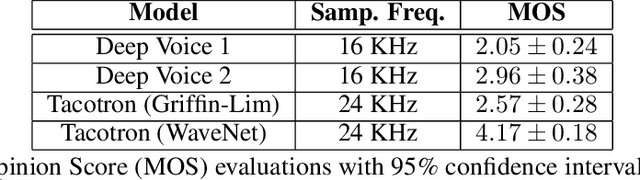


We introduce a technique for augmenting neural text-to-speech (TTS) with lowdimensional trainable speaker embeddings to generate different voices from a single model. As a starting point, we show improvements over the two state-ofthe-art approaches for single-speaker neural TTS: Deep Voice 1 and Tacotron. We introduce Deep Voice 2, which is based on a similar pipeline with Deep Voice 1, but constructed with higher performance building blocks and demonstrates a significant audio quality improvement over Deep Voice 1. We improve Tacotron by introducing a post-processing neural vocoder, and demonstrate a significant audio quality improvement. We then demonstrate our technique for multi-speaker speech synthesis for both Deep Voice 2 and Tacotron on two multi-speaker TTS datasets. We show that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly.
Convolutional Recurrent Neural Networks for Small-Footprint Keyword Spotting
Jul 04, 2017

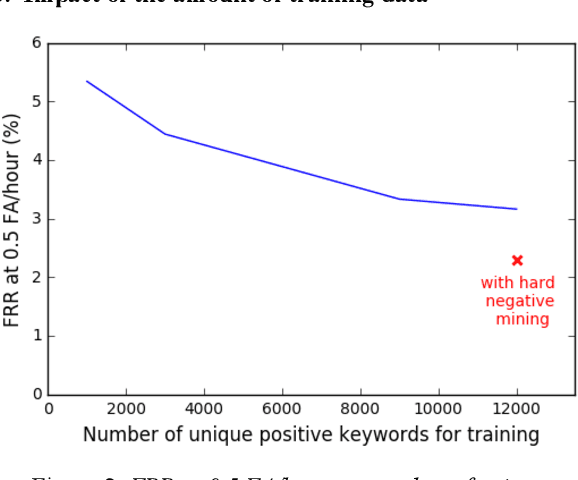

Keyword spotting (KWS) constitutes a major component of human-technology interfaces. Maximizing the detection accuracy at a low false alarm (FA) rate, while minimizing the footprint size, latency and complexity are the goals for KWS. Towards achieving them, we study Convolutional Recurrent Neural Networks (CRNNs). Inspired by large-scale state-of-the-art speech recognition systems, we combine the strengths of convolutional layers and recurrent layers to exploit local structure and long-range context. We analyze the effect of architecture parameters, and propose training strategies to improve performance. With only ~230k parameters, our CRNN model yields acceptably low latency, and achieves 97.71% accuracy at 0.5 FA/hour for 5 dB signal-to-noise ratio.
Deep Voice: Real-time Neural Text-to-Speech
Mar 07, 2017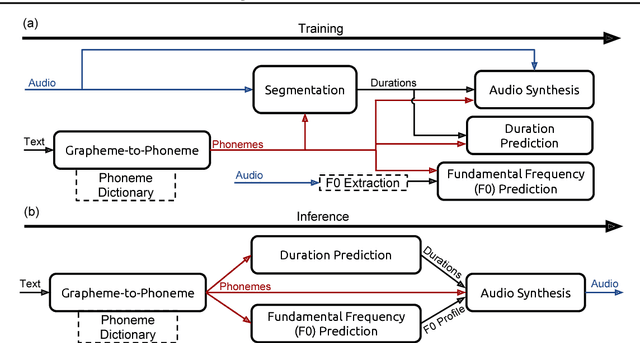
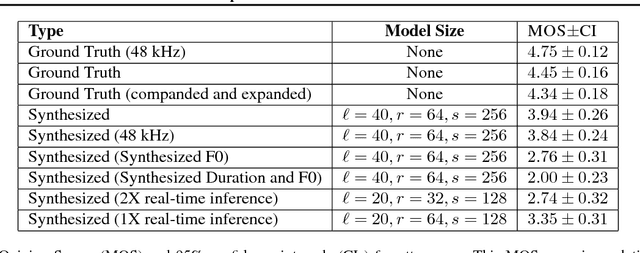
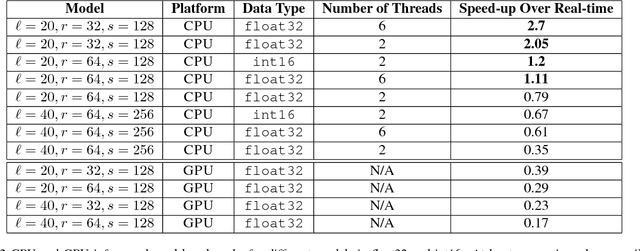
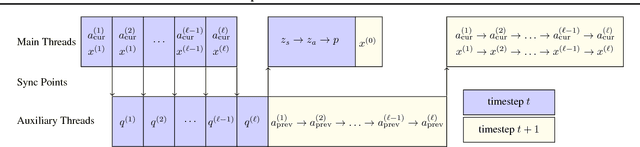
We present Deep Voice, a production-quality text-to-speech system constructed entirely from deep neural networks. Deep Voice lays the groundwork for truly end-to-end neural speech synthesis. The system comprises five major building blocks: a segmentation model for locating phoneme boundaries, a grapheme-to-phoneme conversion model, a phoneme duration prediction model, a fundamental frequency prediction model, and an audio synthesis model. For the segmentation model, we propose a novel way of performing phoneme boundary detection with deep neural networks using connectionist temporal classification (CTC) loss. For the audio synthesis model, we implement a variant of WaveNet that requires fewer parameters and trains faster than the original. By using a neural network for each component, our system is simpler and more flexible than traditional text-to-speech systems, where each component requires laborious feature engineering and extensive domain expertise. Finally, we show that inference with our system can be performed faster than real time and describe optimized WaveNet inference kernels on both CPU and GPU that achieve up to 400x speedups over existing implementations.