 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Scaling Laws for Efficient GRPO Training of Large Reasoning Models
Jul 24, 2025



Fine-tuning large language models (LLMs) for reasoning tasks using reinforcement learning methods like Group Relative Policy Optimization (GRPO) is computationally expensive. To address this, we propose a predictive framework that models training dynamics and helps optimize resource usage. Through experiments on Llama and Qwen models (3B 8B), we derive an empirical scaling law based on model size, initial performance, and training progress. This law predicts reward trajectories and identifies three consistent training phases: slow start, rapid improvement, and plateau. We find that training beyond certain number of an epoch offers little gain, suggesting earlier stopping can significantly reduce compute without sacrificing performance. Our approach generalizes across model types, providing a practical guide for efficient GRPO-based fine-tuning.
MLKV: Efficiently Scaling up Large Embedding Model Training with Disk-based Key-Value Storage
Apr 02, 2025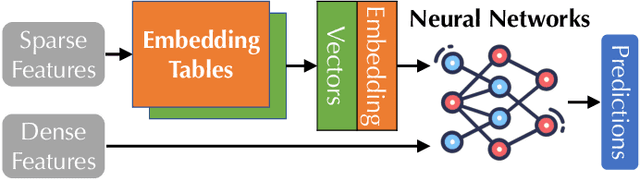
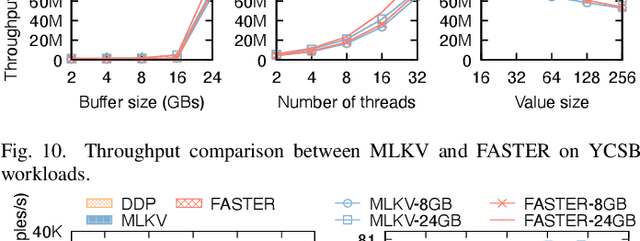
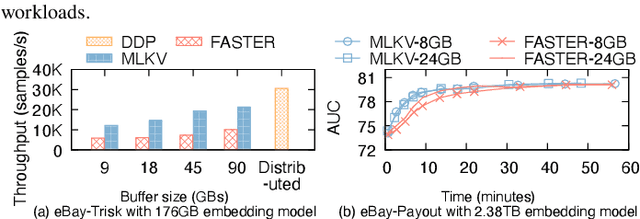

Many modern machine learning (ML) methods rely on embedding models to learn vector representations (embeddings) for a set of entities (embedding tables). As increasingly diverse ML applications utilize embedding models and embedding tables continue to grow in size and number, there has been a surge in the ad-hoc development of specialized frameworks targeted to train large embedding models for specific tasks. Although the scalability issues that arise in different embedding model training tasks are similar, each of these frameworks independently reinvents and customizes storage components for specific tasks, leading to substantial duplicated engineering efforts in both development and deployment. This paper presents MLKV, an efficient, extensible, and reusable data storage framework designed to address the scalability challenges in embedding model training, specifically data stall and staleness. MLKV augments disk-based key-value storage by democratizing optimizations that were previously exclusive to individual specialized frameworks and provides easy-to-use interfaces for embedding model training tasks. Extensive experiments on open-source workloads, as well as applications in eBay's payment transaction risk detection and seller payment risk detection, show that MLKV outperforms offloading strategies built on top of industrial-strength key-value stores by 1.6-12.6x. MLKV is open-source at https://github.com/llm-db/MLKV.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021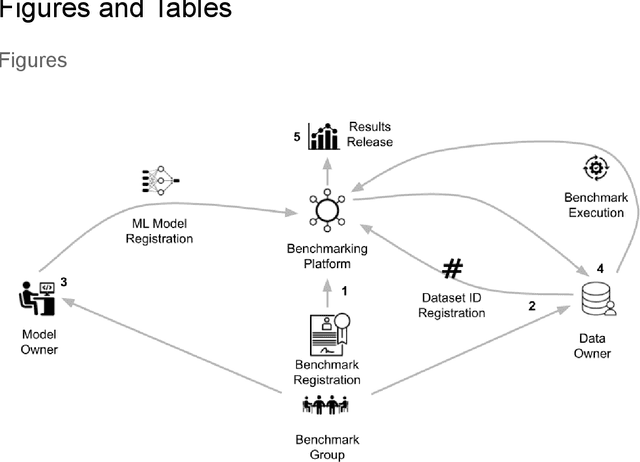
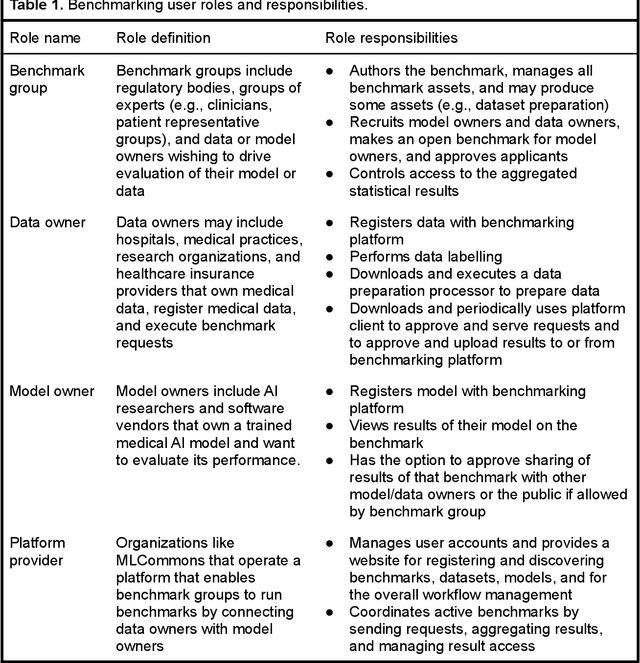
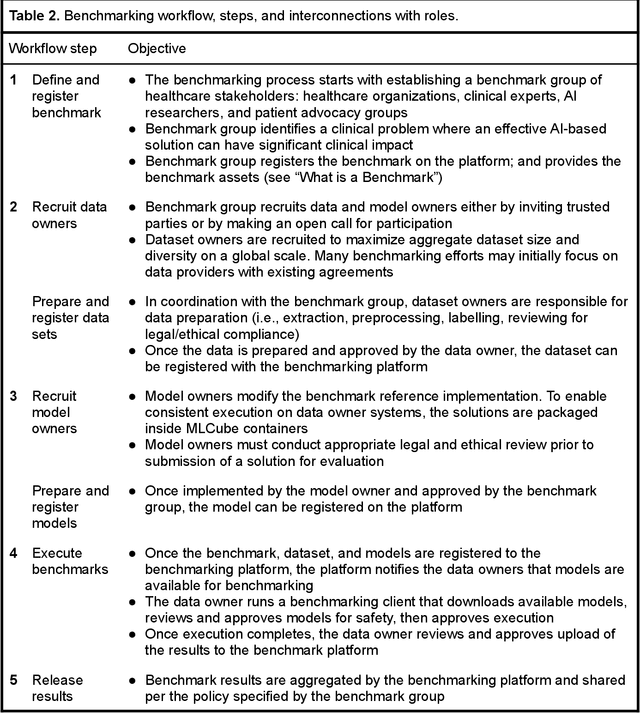
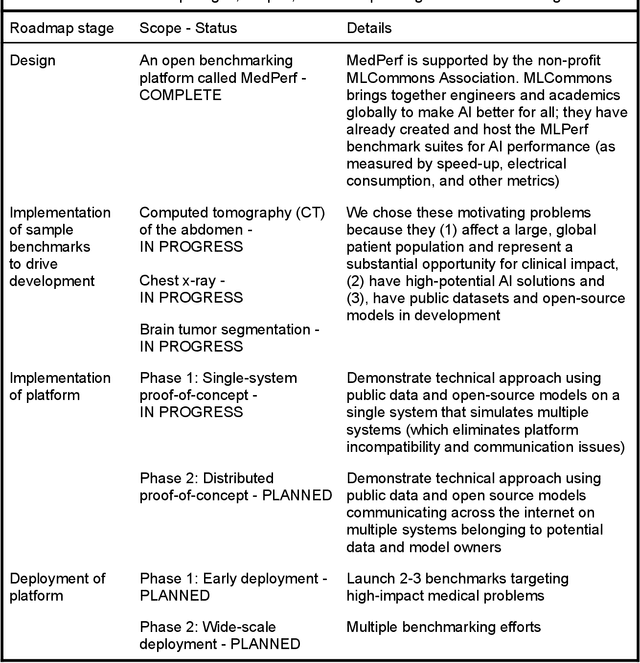
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
A Scalable and Cloud-Native Hyperparameter Tuning System
Jun 08, 2020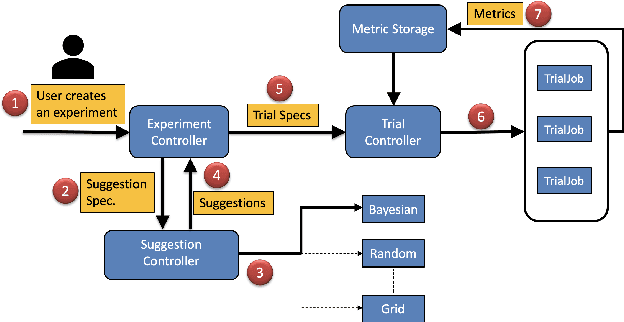
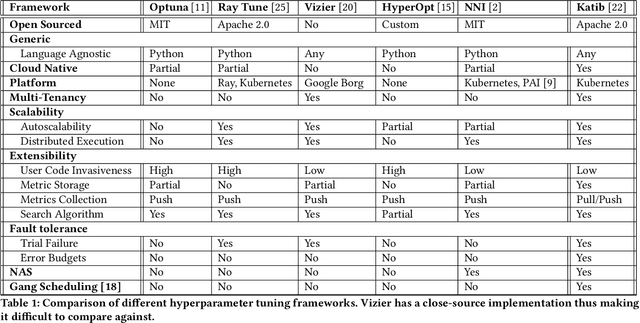
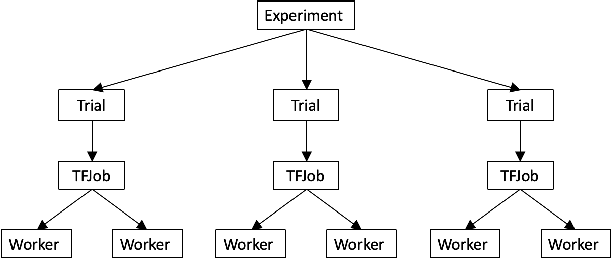
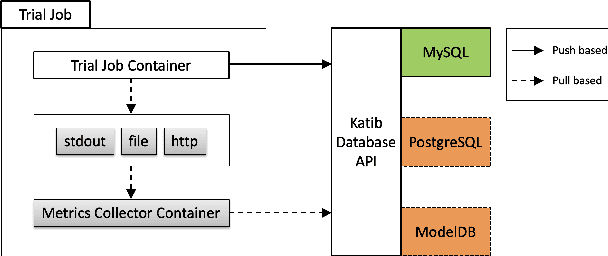
In this paper, we introduce Katib: a scalable, cloud-native, and production-ready hyperparameter tuning system that is agnostic of the underlying machine learning framework. Though there are multiple hyperparameter tuning systems available, this is the first one that caters to the needs of both users and administrators of the system. We present the motivation and design of the system and contrast it with existing hyperparameter tuning systems, especially in terms of multi-tenancy, scalability, fault-tolerance, and extensibility. It can be deployed on local machines, or hosted as a service in on-premise data centers, or in private/public clouds. We demonstrate the advantage of our system using experimental results as well as real-world, production use cases. Katib has active contributors from multiple companies and is open-sourced at \emph{https://github.com/kubeflow/katib} under the Apache 2.0 license.