 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTumorXAI: Self-Supervised Deep Learning Framework for Explainable Brain MRI Tumor Classification
May 03, 2026Classifying brain tumors using magnetic resonance imaging (MRI) is crucial for early diagnosis and treatment; however, tumor heterogeneity and a dearth of annotated datasets restrict the use of supervised deep learning approaches. In this work, we use self-supervised learning (SSL) to study multi-class brain tumor classification. Using a ResNet-50 backbone, we evaluate four SSL frameworks including SimCLR, BYOL, DINO, and Moco v3 on a publicly available dataset of 4,448 MRIs with 17 distinct tumor types. On the dataset, SimCLR achieved 99.64% accuracy, 99.64% precision, 99.64% recall, and 99.64% F1-score. The workflow includes preprocessing, fine-tuning, linear evaluation, and SSL pretraining with data augmentations. Results show that, when labels are limited, SSL-pretrained models outperform supervised baselines in terms of F1-score, recall, accuracy, and precision. Additionally, by providing visual insights into model decisions, Explainable AI techniques (Grad-CAM, Grad-CAM++, EigenCAM) enhance interpretability. These results demonstrate SSL's scalability and dependability in diagnosing brain tumors from unlabeled medical data.
Direct Federated Neural Architecture Search
Oct 20, 2020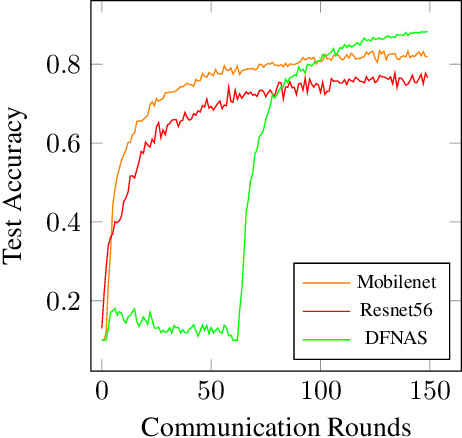

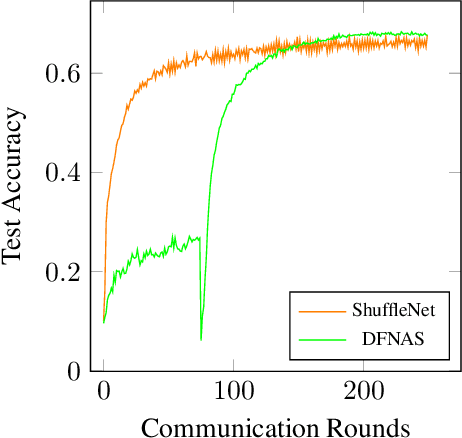
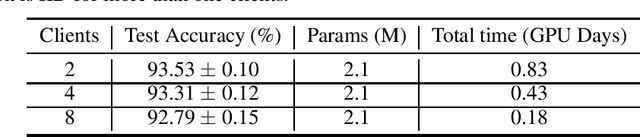
Neural Architecture Search (NAS) is a collection of methods to craft the way neural networks are built. We apply this idea to Federated Learning (FL), wherein predefined neural network models are trained on the client/device data. This approach is not optimal as the model developers can't observe the local data, and hence, are unable to build highly accurate and efficient models. NAS is promising for FL which can search for global and personalized models automatically for the non-IID data. Most NAS methods are computationally expensive and require fine-tuning after the search, making it a two-stage complex process with possible human intervention. Thus there is a need for end-to-end NAS which can run on the heterogeneous data and resource distribution typically seen in the FL scenario. In this paper, we present an effective approach for direct federated NAS which is hardware agnostic, computationally lightweight, and a one-stage method to search for ready-to-deploy neural network models. Our results show an order of magnitude reduction in resource consumption while edging out prior art in accuracy. This opens up a window of opportunity to create optimized and computationally efficient federated learning systems.
Revisiting Neural Architecture Search
Oct 18, 2020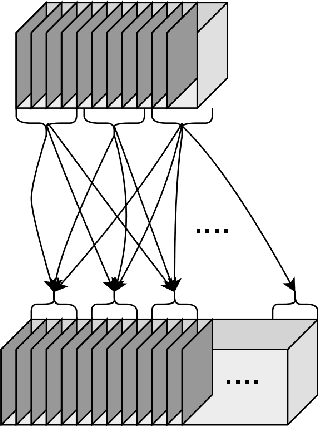
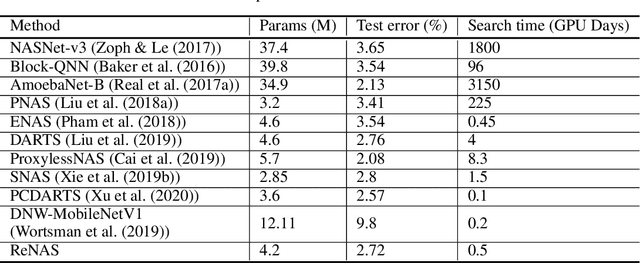
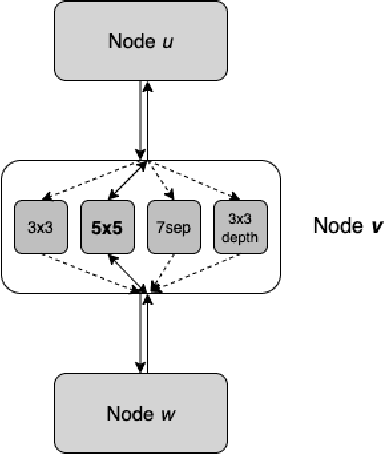
Neural Architecture Search (NAS) is a collection of methods to craft the way neural networks are built. Current NAS methods are far from ab initio and automatic, as they use manual backbone architectures or micro building blocks (cells), which have had minor breakthroughs in performance compared to random baselines. They also involve a significant manual expert effort in various components of the NAS pipeline. This raises a natural question - Are the current NAS methods still heavily dependent on manual effort in the search space design and wiring like it was done when building models before the advent of NAS? In this paper, instead of merely chasing slight improvements over state-of-the-art (SOTA) performance, we revisit the fundamental approach to NAS and propose a novel approach called ReNAS that can search for the complete neural network without much human effort and is a step closer towards AutoML-nirvana. Our method starts from a complete graph mapped to a neural network and searches for the connections and operations by balancing the exploration and exploitation of the search space. The results are on-par with the SOTA performance with methods that leverage handcrafted blocks. We believe that this approach may lead to newer NAS strategies for a variety of network types.
A Scalable and Cloud-Native Hyperparameter Tuning System
Jun 08, 2020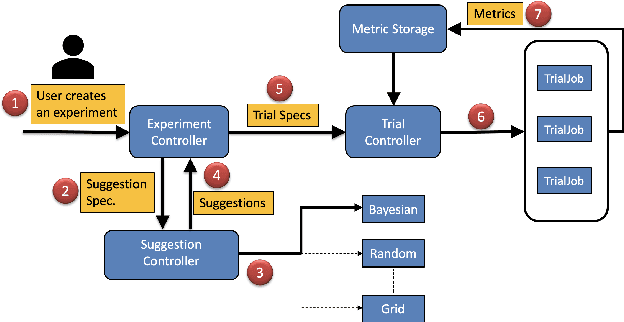
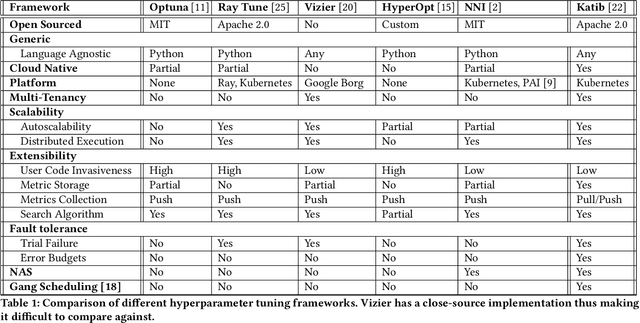
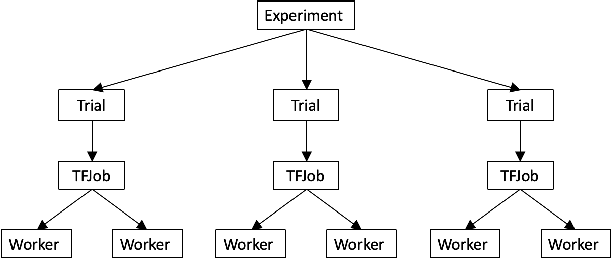
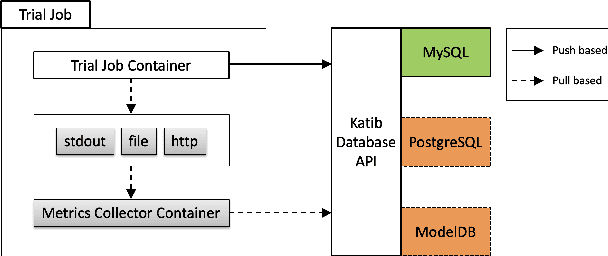
In this paper, we introduce Katib: a scalable, cloud-native, and production-ready hyperparameter tuning system that is agnostic of the underlying machine learning framework. Though there are multiple hyperparameter tuning systems available, this is the first one that caters to the needs of both users and administrators of the system. We present the motivation and design of the system and contrast it with existing hyperparameter tuning systems, especially in terms of multi-tenancy, scalability, fault-tolerance, and extensibility. It can be deployed on local machines, or hosted as a service in on-premise data centers, or in private/public clouds. We demonstrate the advantage of our system using experimental results as well as real-world, production use cases. Katib has active contributors from multiple companies and is open-sourced at \emph{https://github.com/kubeflow/katib} under the Apache 2.0 license.