 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Linguistic Embeddings for the Identification of Affect
Apr 21, 2023The wealth of text data generated by social media has enabled new kinds of analysis of emotions with language models. These models are often trained on small and costly datasets of text annotations produced by readers who guess the emotions expressed by others in social media posts. This affects the quality of emotion identification methods due to training data size limitations and noise in the production of labels used in model development. We present LEIA, a model for emotion identification in text that has been trained on a dataset of more than 6 million posts with self-annotated emotion labels for happiness, affection, sadness, anger, and fear. LEIA is based on a word masking method that enhances the learning of emotion words during model pre-training. LEIA achieves macro-F1 values of approximately 73 on three in-domain test datasets, outperforming other supervised and unsupervised methods in a strong benchmark that shows that LEIA generalizes across posts, users, and time periods. We further perform an out-of-domain evaluation on five different datasets of social media and other sources, showing LEIA's robust performance across media, data collection methods, and annotation schemes. Our results show that LEIA generalizes its classification of anger, happiness, and sadness beyond the domain it was trained on. LEIA can be applied in future research to provide better identification of emotions in text from the perspective of the writer. The models produced for this article are publicly available at https://huggingface.co/LEIA
LEXpander: applying colexification networks to automated lexicon expansion
May 31, 2022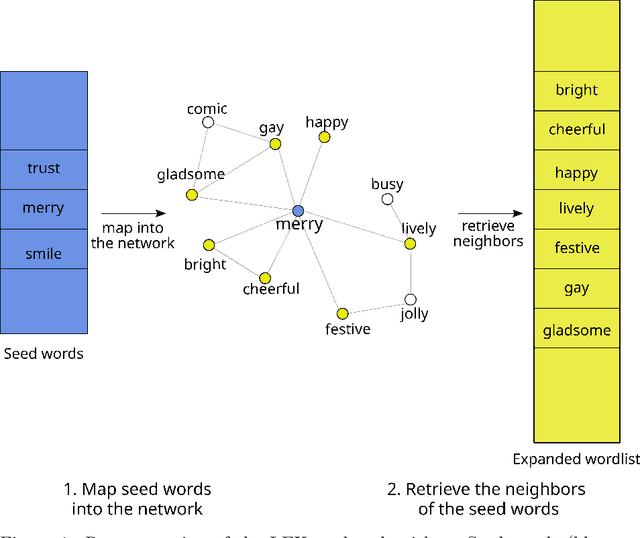
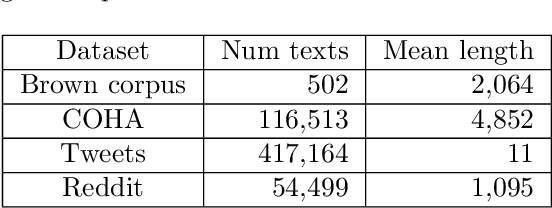
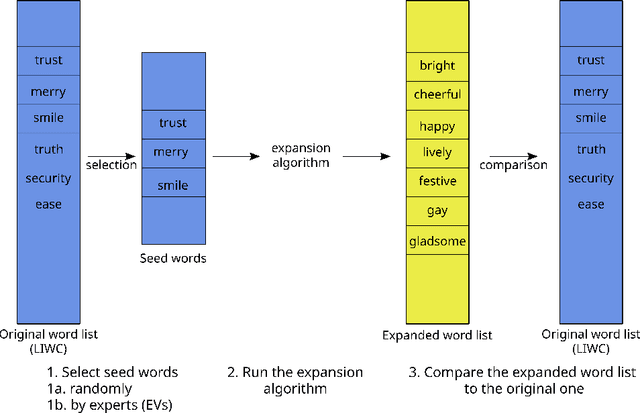
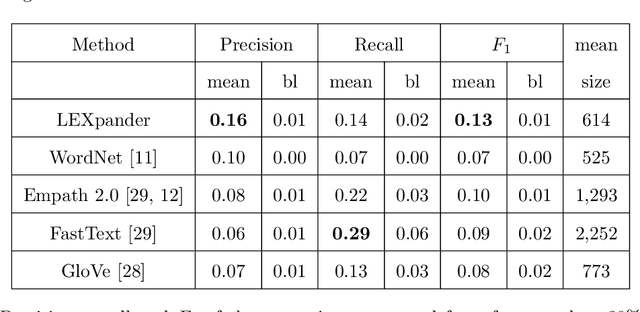
Recent approaches to text analysis from social media and other corpora rely on word lists to detect topics, measure meaning, or to select relevant documents. These lists are often generated by applying computational lexicon expansion methods to small, manually-curated sets of root words. Despite the wide use of this approach, we still lack an exhaustive comparative analysis of the performance of lexicon expansion methods and how they can be improved with additional linguistic data. In this work, we present LEXpander, a method for lexicon expansion that leverages novel data on colexification, i.e. semantic networks connecting words based on shared concepts and translations to other languages. We evaluate LEXpander in a benchmark including widely used methods for lexicon expansion based on various word embedding models and synonym networks. We find that LEXpander outperforms existing approaches in terms of both precision and the trade-off between precision and recall of generated word lists in a variety of tests. Our benchmark includes several linguistic categories and sentiment variables in English and German. We also show that the expanded word lists constitute a high-performing text analysis method in application cases to various corpora. This way, LEXpander poses a systematic automated solution to expand short lists of words into exhaustive and accurate word lists that can closely approximate word lists generated by experts in psychology and linguistics.