 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributing Deep Learning Hyperparameter Tuning for 3D Medical Image Segmentation
Oct 29, 2021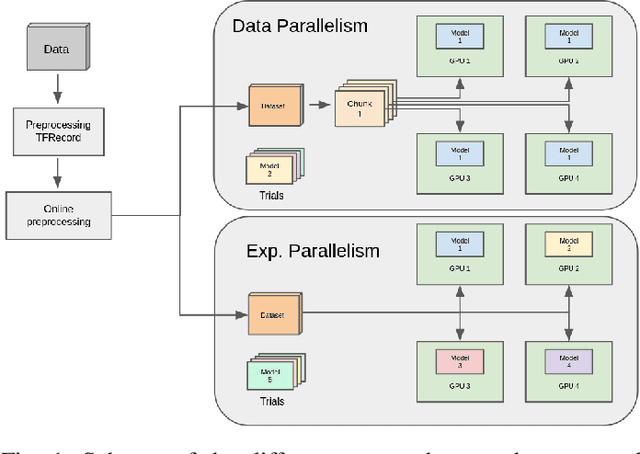
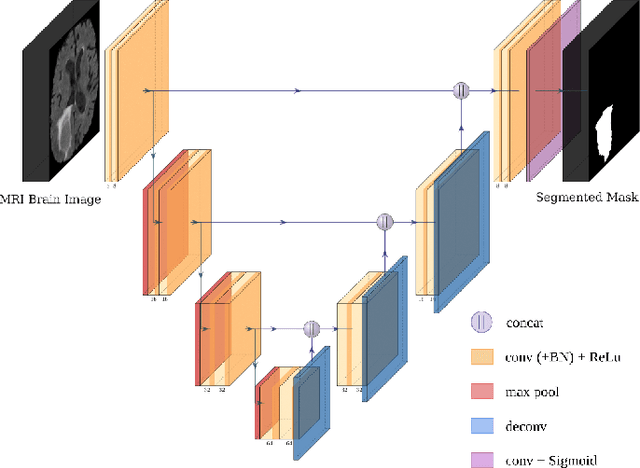
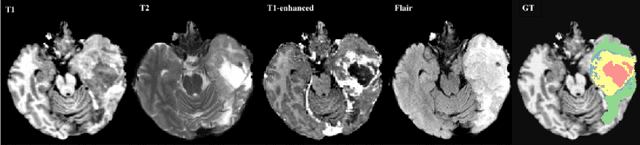
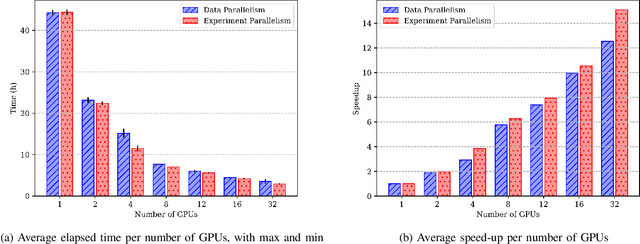
Most research on novel techniques for 3D Medical Image Segmentation (MIS) is currently done using Deep Learning with GPU accelerators. The principal challenge of such technique is that a single input can easily cope computing resources, and require prohibitive amounts of time to be processed. Distribution of deep learning and scalability over computing devices is an actual need for progressing on such research field. Conventional distribution of neural networks consist in data parallelism, where data is scattered over resources (e.g., GPUs) to parallelize the training of the model. However, experiment parallelism is also an option, where different training processes are parallelized across resources. While the first option is much more common on 3D image segmentation, the second provides a pipeline design with less dependence among parallelized processes, allowing overhead reduction and more potential scalability. In this work we present a design for distributed deep learning training pipelines, focusing on multi-node and multi-GPU environments, where the two different distribution approaches are deployed and benchmarked. We take as proof of concept the 3D U-Net architecture, using the MSD Brain Tumor Segmentation dataset, a state-of-art problem in medical image segmentation with high computing and space requirements. Using the BSC MareNostrum supercomputer as benchmarking environment, we use TensorFlow and Ray as neural network training and experiment distribution platforms. We evaluate the experiment speed-up, showing the potential for scaling out on GPUs and nodes. Also comparing the different parallelism techniques, showing how experiment distribution leverages better such resources through scaling. Finally, we provide the implementation of the design open to the community, and the non-trivial steps and methodology for adapting and deploying a MIS case as the here presented.
Improving accuracy and speeding up Document Image Classification through parallel systems
Jun 16, 2020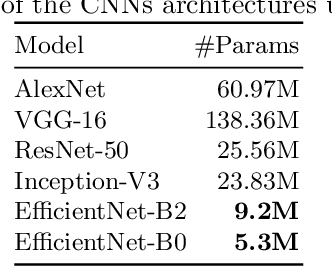
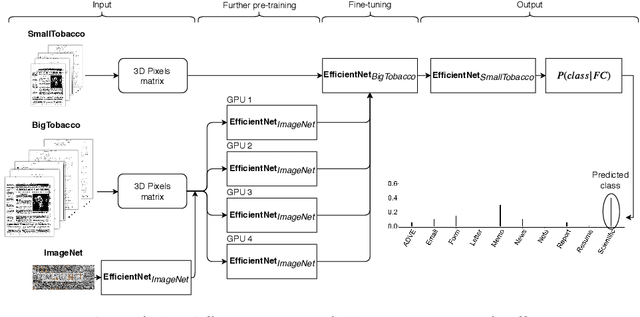
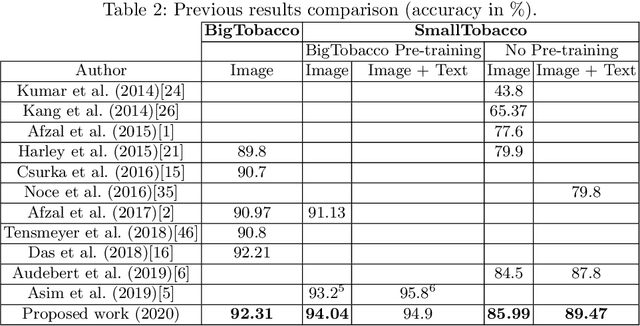
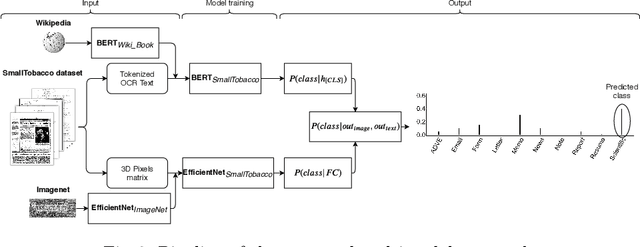
This paper presents a study showing the benefits of the EfficientNet models compared with heavier Convolutional Neural Networks (CNNs) in the Document Classification task, essential problem in the digitalization process of institutions. We show in the RVL-CDIP dataset that we can improve previous results with a much lighter model and present its transfer learning capabilities on a smaller in-domain dataset such as Tobacco3482. Moreover, we present an ensemble pipeline which is able to boost solely image input by combining image model predictions with the ones generated by BERT model on extracted text by OCR. We also show that the batch size can be effectively increased without hindering its accuracy so that the training process can be sped up by parallelizing throughout multiple GPUs, decreasing the computational time needed. Lastly, we expose the training performance differences between PyTorch and Tensorflow Deep Learning frameworks.