 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Can Explain Visual Features via Steering
Mar 25, 2026Sparse Autoencoders uncover thousands of features in vision models, yet explaining these features without requiring human intervention remains an open challenge. While previous work has proposed generating correlation-based explanations based on top activating input examples, we present a fundamentally different alternative based on causal interventions. We leverage the structure of Vision-Language Models and steer individual SAE features in the vision encoder after providing an empty image. Then, we prompt the language model to explain what it ``sees'', effectively eliciting the visual concept represented by each feature. Results show that Steering offers an scalable alternative that complements traditional approaches based on input examples, serving as a new axis for automated interpretability in vision models. Moreover, the quality of explanations improves consistently with the scale of the language model, highlighting our method as a promising direction for future research. Finally, we propose Steering-informed Top-k, a hybrid approach that combines the strengths of causal interventions and input-based approaches to achieve state-of-the-art explanation quality without additional computational cost.
Weight space Detection of Backdoors in LoRA Adapters
Feb 16, 2026LoRA adapters let users fine-tune large language models (LLMs) efficiently. However, LoRA adapters are shared through open repositories like Hugging Face Hub \citep{huggingface_hub_docs}, making them vulnerable to backdoor attacks. Current detection methods require running the model with test input data -- making them impractical for screening thousands of adapters where the trigger for backdoor behavior is unknown. We detect poisoned adapters by analyzing their weight matrices directly, without running the model -- making our method data-agnostic. Our method extracts simple statistics -- how concentrated the singular values are, their entropy, and the distribution shape -- and flags adapters that deviate from normal patterns. We evaluate the method on 500 LoRA adapters -- 400 clean, and 100 poisoned for Llama-3.2-3B on instruction and reasoning datasets: Alpaca, Dolly, GSM8K, ARC-Challenge, SQuADv2, NaturalQuestions, HumanEval, and GLUE dataset. We achieve 97\% detection accuracy with less than 2\% false positives.
Putting a Face to Forgetting: Continual Learning meets Mechanistic Interpretability
Jan 29, 2026Catastrophic forgetting in continual learning is often measured at the performance or last-layer representation level, overlooking the underlying mechanisms. We introduce a mechanistic framework that offers a geometric interpretation of catastrophic forgetting as the result of transformations to the encoding of individual features. These transformations can lead to forgetting by reducing the allocated capacity of features (worse representation) and disrupting their readout by downstream computations. Analysis of a tractable model formalizes this view, allowing us to identify best- and worst-case scenarios. Through experiments on this model, we empirically test our formal analysis and highlight the detrimental effect of depth. Finally, we demonstrate how our framework can be used in the analysis of practical models through the use of Crosscoders. We present a case study of a Vision Transformer trained on sequential CIFAR-10. Our work provides a new, feature-centric vocabulary for continual learning.
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models
Nov 21, 2024
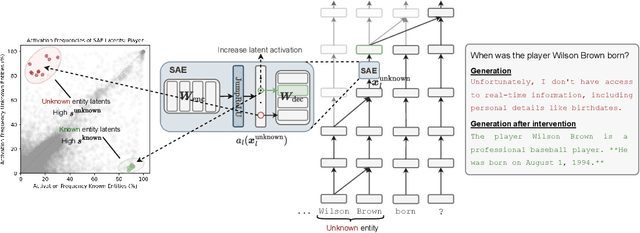
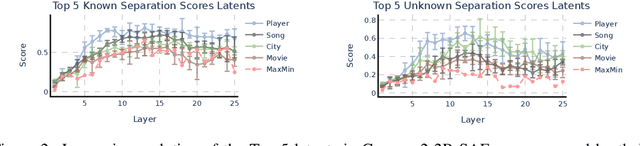

Hallucinations in large language models are a widespread problem, yet the mechanisms behind whether models will hallucinate are poorly understood, limiting our ability to solve this problem. Using sparse autoencoders as an interpretability tool, we discover that a key part of these mechanisms is entity recognition, where the model detects if an entity is one it can recall facts about. Sparse autoencoders uncover meaningful directions in the representation space, these detect whether the model recognizes an entity, e.g. detecting it doesn't know about an athlete or a movie. This suggests that models can have self-knowledge: internal representations about their own capabilities. These directions are causally relevant: capable of steering the model to refuse to answer questions about known entities, or to hallucinate attributes of unknown entities when it would otherwise refuse. We demonstrate that despite the sparse autoencoders being trained on the base model, these directions have a causal effect on the chat model's refusal behavior, suggesting that chat finetuning has repurposed this existing mechanism. Furthermore, we provide an initial exploration into the mechanistic role of these directions in the model, finding that they disrupt the attention of downstream heads that typically move entity attributes to the final token.
On the Similarity of Circuits across Languages: a Case Study on the Subject-verb Agreement Task
Oct 09, 2024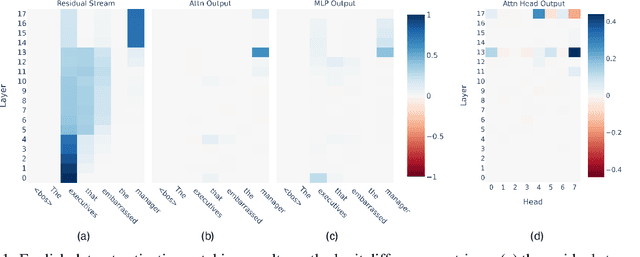

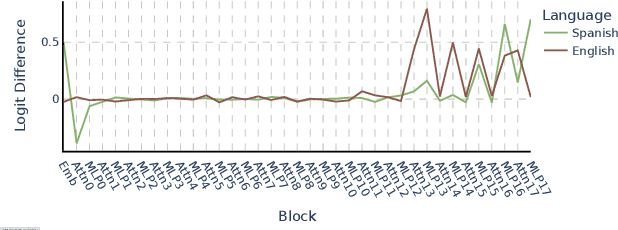

Several algorithms implemented by language models have recently been successfully reversed-engineered. However, these findings have been concentrated on specific tasks and models, leaving it unclear how universal circuits are across different settings. In this paper, we study the circuits implemented by Gemma 2B for solving the subject-verb agreement task across two different languages, English and Spanish. We discover that both circuits are highly consistent, being mainly driven by a particular attention head writing a `subject number' signal to the last residual stream, which is read by a small set of neurons in the final MLPs. Notably, this subject number signal is represented as a direction in the residual stream space, and is language-independent. We demonstrate that this direction has a causal effect on the model predictions, effectively flipping the Spanish predicted verb number by intervening with the direction found in English. Finally, we present evidence of similar behavior in other models within the Gemma 1 and Gemma 2 families.
A Primer on the Inner Workings of Transformer-based Language Models
May 02, 2024The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
LM Transparency Tool: Interactive Tool for Analyzing Transformer Language Models
Apr 10, 2024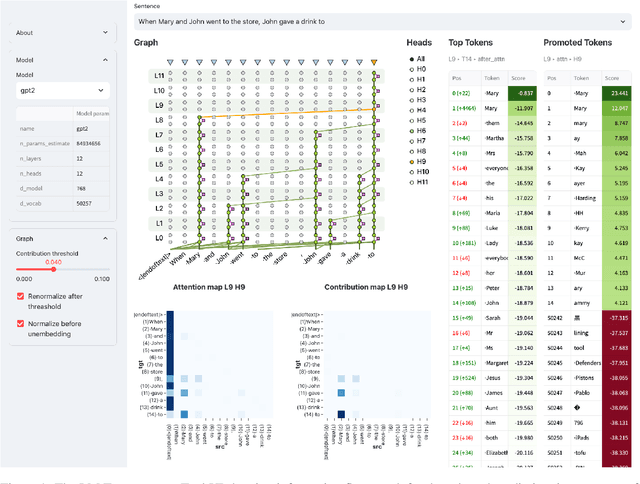
We present the LM Transparency Tool (LM-TT), an open-source interactive toolkit for analyzing the internal workings of Transformer-based language models. Differently from previously existing tools that focus on isolated parts of the decision-making process, our framework is designed to make the entire prediction process transparent, and allows tracing back model behavior from the top-layer representation to very fine-grained parts of the model. Specifically, it (1) shows the important part of the whole input-to-output information flow, (2) allows attributing any changes done by a model block to individual attention heads and feed-forward neurons, (3) allows interpreting the functions of those heads or neurons. A crucial part of this pipeline is showing the importance of specific model components at each step. As a result, we are able to look at the roles of model components only in cases where they are important for a prediction. Since knowing which components should be inspected is key for analyzing large models where the number of these components is extremely high, we believe our tool will greatly support the interpretability community both in research settings and in practical applications.
Information Flow Routes: Automatically Interpreting Language Models at Scale
Feb 27, 2024Information flows by routes inside the network via mechanisms implemented in the model. These routes can be represented as graphs where nodes correspond to token representations and edges to operations inside the network. We automatically build these graphs in a top-down manner, for each prediction leaving only the most important nodes and edges. In contrast to the existing workflows relying on activation patching, we do this through attribution: this allows us to efficiently uncover existing circuits with just a single forward pass. Additionally, the applicability of our method is far beyond patching: we do not need a human to carefully design prediction templates, and we can extract information flow routes for any prediction (not just the ones among the allowed templates). As a result, we can talk about model behavior in general, for specific types of predictions, or different domains. We experiment with Llama 2 and show that the role of some attention heads is overall important, e.g. previous token heads and subword merging heads. Next, we find similarities in Llama 2 behavior when handling tokens of the same part of speech. Finally, we show that some model components can be specialized on domains such as coding or multilingual texts.
Neurons in Large Language Models: Dead, N-gram, Positional
Sep 09, 2023We analyze a family of large language models in such a lightweight manner that can be done on a single GPU. Specifically, we focus on the OPT family of models ranging from 125m to 66b parameters and rely only on whether an FFN neuron is activated or not. First, we find that the early part of the network is sparse and represents many discrete features. Here, many neurons (more than 70% in some layers of the 66b model) are "dead", i.e. they never activate on a large collection of diverse data. At the same time, many of the alive neurons are reserved for discrete features and act as token and n-gram detectors. Interestingly, their corresponding FFN updates not only promote next token candidates as could be expected, but also explicitly focus on removing the information about triggering them tokens, i.e., current input. To the best of our knowledge, this is the first example of mechanisms specialized at removing (rather than adding) information from the residual stream. With scale, models become more sparse in a sense that they have more dead neurons and token detectors. Finally, some neurons are positional: them being activated or not depends largely (or solely) on position and less so (or not at all) on textual data. We find that smaller models have sets of neurons acting as position range indicators while larger models operate in a less explicit manner.
Automating Behavioral Testing in Machine Translation
Sep 07, 2023
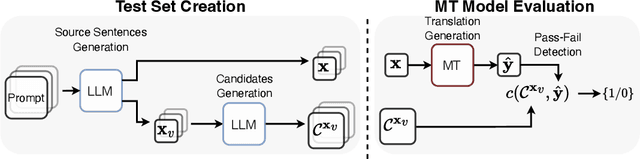

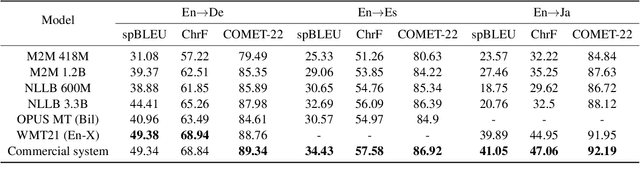
Behavioral testing in NLP allows fine-grained evaluation of systems by examining their linguistic capabilities through the analysis of input-output behavior. Unfortunately, existing work on behavioral testing in Machine Translation (MT) is currently restricted to largely handcrafted tests covering a limited range of capabilities and languages. To address this limitation, we propose to use Large Language Models (LLMs) to generate a diverse set of source sentences tailored to test the behavior of MT models in a range of situations. We can then verify whether the MT model exhibits the expected behavior through matching candidate sets that are also generated using LLMs. Our approach aims to make behavioral testing of MT systems practical while requiring only minimal human effort. In our experiments, we apply our proposed evaluation framework to assess multiple available MT systems, revealing that while in general pass-rates follow the trends observable from traditional accuracy-based metrics, our method was able to uncover several important differences and potential bugs that go unnoticed when relying only on accuracy.