 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation
Paper and Code
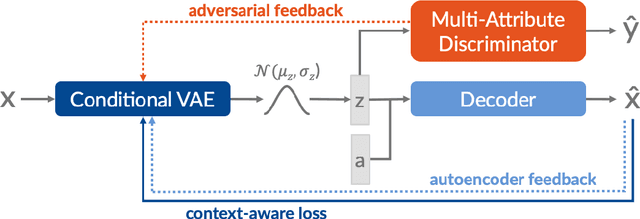



In this work, we present a text generation approach with multi-attribute control for data augmentation. We introduce CGA, a Variational Autoencoder architecture, to control, generate, and augment text. CGA is able to generate natural sentences with multiple controlled attributes by combining adversarial learning with a context-aware loss. The scalability of our approach is established through a single discriminator, independently of the number of attributes. As the main application of our work, we test the potential of this new model in a data augmentation use case. In a downstream NLP task, the sentences generated by our CGA model not only show significant improvements over a strong baseline, but also a classification performance very similar to real data. Furthermore, we are able to show high quality, diversity and attribute control in the generated sentences through a series of automatic and human assessments.