 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRA-PoE: Robust Alzheimer's Diagnosis with Arbitrary Missing Modalities
May 13, 2026Missing modalities are prevalent in real-world Alzheimer's disease (AD) assessment and pose a significant challenge to multimodal learning, particularly when the distribution of observed modality subsets differs between training and deployment. Such missingness pattern mismatch induces a conditional representation shift across modality subsets. Existing approaches that rely on implicit imputation or modality synthesis often fail to explicitly model modality availability and uncertainty, leading to overconfident dependence on synthesized features, reduced robustness, and miscalibrated uncertainty estimates. To address these limitations, we propose PRA-PoE, an incomplete multimodal learning framework that is equipped with Prototype-anchored Representation Alignment (PRA) and an Uncertainty-aware Product of Experts (UA-PoE) fusion mechanism. First, PRA uses learnable global prototypes and availability-conditioned tokens to encode modality availability, distinguish observed from missing modalities, re-synthesize features for missing modalities, and adaptively refine observed representations to align latent spaces across modality subsets, with the goal of reducing representation shift under varying missingness patterns. Second, UA-PoE models each modality as a Gaussian expert and performs closed-form Product of Experts fusion, where experts with higher uncertainty are automatically down-weighted via lower precision, improving uncertainty reliability. We evaluate PRA-PoE under a clinically realistic protocol by training with naturally missing data and testing on all non-empty modality combinations. PRA-PoE consistently outperforms the state-of-the-art across datasets, achieving a 5.4% relative improvement in average accuracy on ADNI and a 10.9% relative gain in average F1 on OASIS-3 over the strongest baseline across all non-empty modality subsets.
BrainAnytime: Anatomy-Aware Cross-Modal Pretraining for Brain Image Analysis with Arbitrary Modality Availability
May 13, 2026Clinical diagnostic workups typically follow a modality escalation pathway: after initial clinical evaluation, clinicians begin with routine structural imaging (e.g., MRI), selectively add sequences such as FLAIR or T2 to refine the differential, and reserve molecular imaging (e.g., amyloid-PET) for cases that remain uncertain after standard evaluation. Consequently, patients are observed with heterogeneous and often incomplete modality subsets. However, most current AI models assume fixed data modalities as the model inputs. In this paper, we present BrainAnytime, a unified pretraining framework pretrained on 34,899 3D brain scans from five datasets that support brain image analysis under arbitrary modality availability spanning multi-sequence MRI and amyloid-PET. A single model accepts whatever imaging is available, from a lone T1 scan to a full multimodal workup. Pretraining learns structural-molecular correspondences between MRI and PET via cross-modal distillation (RCMD) and prioritizes disease-vulnerable anatomy via atlas-guided curriculum masking (PACM), all within a shared 3D masked autoencoder (Multi-MAE3D). Across four downstream tasks and five clinically motivated modality settings, BrainAnytime largely outperforms modality-specific models, missing-modality baselines, and large-scale brain MRI pretrained foundation models on most modality settings. Notably, it surpasses the strongest missing-modality baselines with relative improvements of 6.2% and 7.0% in average accuracy on CN vs. AD and CN vs. MCI classification, respectively. Code is available at https://github.com/SDH-Lab/BrainAnytime.
AD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Medical Knowledge Intervention Prompt Tuning for Medical Image Classification
Nov 16, 2025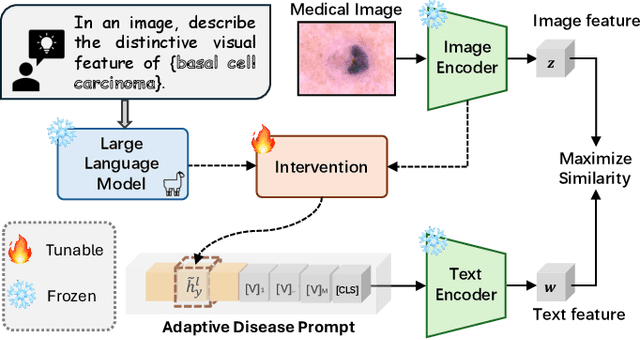
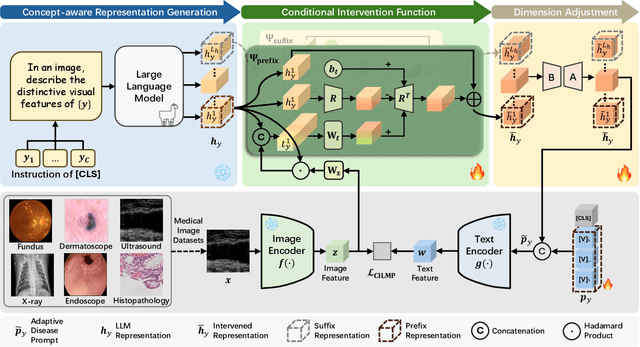
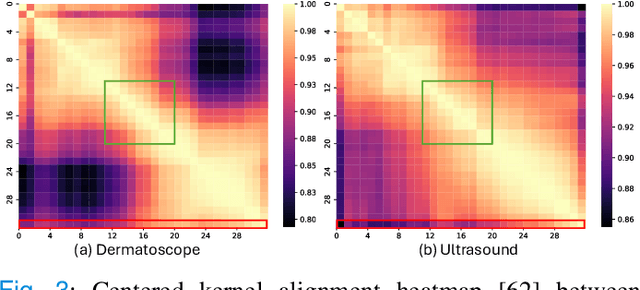
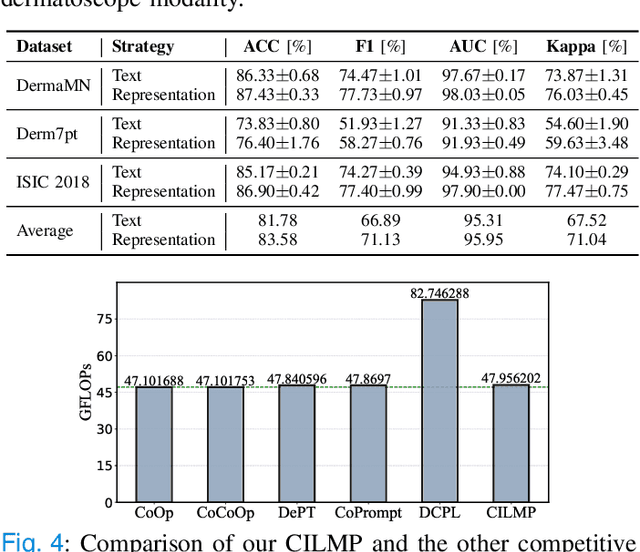
Vision-language foundation models (VLMs) have shown great potential in feature transfer and generalization across a wide spectrum of medical-related downstream tasks. However, fine-tuning these models is resource-intensive due to their large number of parameters. Prompt tuning has emerged as a viable solution to mitigate memory usage and reduce training time while maintaining competitive performance. Nevertheless, the challenge is that existing prompt tuning methods cannot precisely distinguish different kinds of medical concepts, which miss essentially specific disease-related features across various medical imaging modalities in medical image classification tasks. We find that Large Language Models (LLMs), trained on extensive text corpora, are particularly adept at providing this specialized medical knowledge. Motivated by this, we propose incorporating LLMs into the prompt tuning process. Specifically, we introduce the CILMP, Conditional Intervention of Large Language Models for Prompt Tuning, a method that bridges LLMs and VLMs to facilitate the transfer of medical knowledge into VLM prompts. CILMP extracts disease-specific representations from LLMs, intervenes within a low-rank linear subspace, and utilizes them to create disease-specific prompts. Additionally, a conditional mechanism is incorporated to condition the intervention process on each individual medical image, generating instance-adaptive prompts and thus enhancing adaptability. Extensive experiments across diverse medical image datasets demonstrate that CILMP consistently outperforms state-of-the-art prompt tuning methods, demonstrating its effectiveness. Code is available at https://github.com/usr922/cilmp.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
ADAgent: LLM Agent for Alzheimer's Disease Analysis with Collaborative Coordinator
Jun 16, 2025Alzheimer's disease (AD) is a progressive and irreversible neurodegenerative disease. Early and precise diagnosis of AD is crucial for timely intervention and treatment planning to alleviate the progressive neurodegeneration. However, most existing methods rely on single-modality data, which contrasts with the multifaceted approach used by medical experts. While some deep learning approaches process multi-modal data, they are limited to specific tasks with a small set of input modalities and cannot handle arbitrary combinations. This highlights the need for a system that can address diverse AD-related tasks, process multi-modal or missing input, and integrate multiple advanced methods for improved performance. In this paper, we propose ADAgent, the first specialized AI agent for AD analysis, built on a large language model (LLM) to address user queries and support decision-making. ADAgent integrates a reasoning engine, specialized medical tools, and a collaborative outcome coordinator to facilitate multi-modal diagnosis and prognosis tasks in AD. Extensive experiments demonstrate that ADAgent outperforms SOTA methods, achieving significant improvements in accuracy, including a 2.7% increase in multi-modal diagnosis, a 0.7% improvement in multi-modal prognosis, and enhancements in MRI and PET diagnosis tasks.
Pixel-Level Domain Adaptation: A New Perspective for Enhancing Weakly Supervised Semantic Segmentation
Aug 04, 2024



Recent attention has been devoted to the pursuit of learning semantic segmentation models exclusively from image tags, a paradigm known as image-level Weakly Supervised Semantic Segmentation (WSSS). Existing attempts adopt the Class Activation Maps (CAMs) as priors to mine object regions yet observe the imbalanced activation issue, where only the most discriminative object parts are located. In this paper, we argue that the distribution discrepancy between the discriminative and the non-discriminative parts of objects prevents the model from producing complete and precise pseudo masks as ground truths. For this purpose, we propose a Pixel-Level Domain Adaptation (PLDA) method to encourage the model in learning pixel-wise domain-invariant features. Specifically, a multi-head domain classifier trained adversarially with the feature extraction is introduced to promote the emergence of pixel features that are invariant with respect to the shift between the source (i.e., the discriminative object parts) and the target (\textit{i.e.}, the non-discriminative object parts) domains. In addition, we come up with a Confident Pseudo-Supervision strategy to guarantee the discriminative ability of each pixel for the segmentation task, which serves as a complement to the intra-image domain adversarial training. Our method is conceptually simple, intuitive and can be easily integrated into existing WSSS methods. Taking several strong baseline models as instances, we experimentally demonstrate the effectiveness of our approach under a wide range of settings.
CMViM: Contrastive Masked Vim Autoencoder for 3D Multi-modal Representation Learning for AD classification
Mar 25, 2024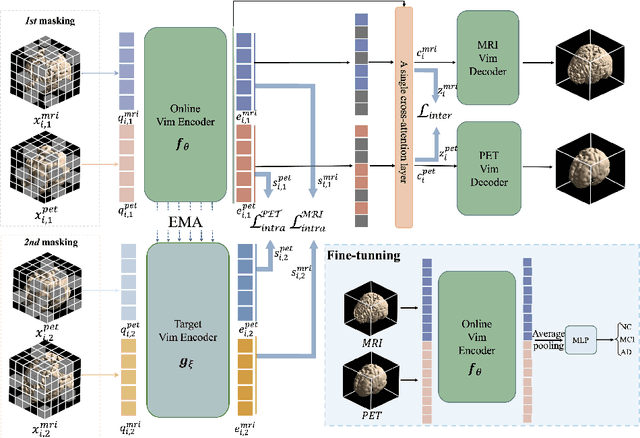
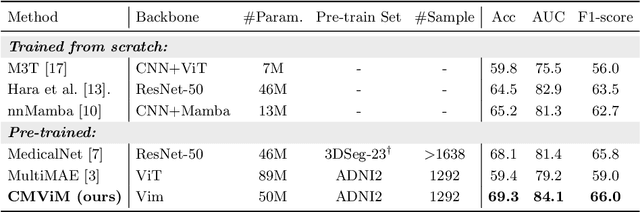
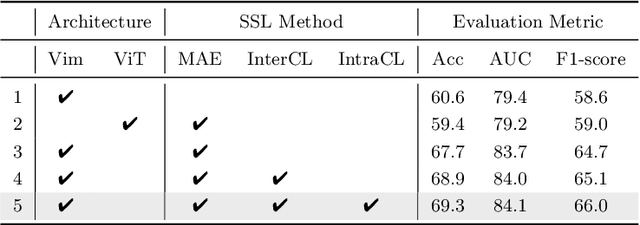
Alzheimer's disease (AD) is an incurable neurodegenerative condition leading to cognitive and functional deterioration. Given the lack of a cure, prompt and precise AD diagnosis is vital, a complex process dependent on multiple factors and multi-modal data. While successful efforts have been made to integrate multi-modal representation learning into medical datasets, scant attention has been given to 3D medical images. In this paper, we propose Contrastive Masked Vim Autoencoder (CMViM), the first efficient representation learning method tailored for 3D multi-modal data. Our proposed framework is built on a masked Vim autoencoder to learn a unified multi-modal representation and long-dependencies contained in 3D medical images. We also introduce an intra-modal contrastive learning module to enhance the capability of the multi-modal Vim encoder for modeling the discriminative features in the same modality, and an inter-modal contrastive learning module to alleviate misaligned representation among modalities. Our framework consists of two main steps: 1) incorporate the Vision Mamba (Vim) into the mask autoencoder to reconstruct 3D masked multi-modal data efficiently. 2) align the multi-modal representations with contrastive learning mechanisms from both intra-modal and inter-modal aspects. Our framework is pre-trained and validated ADNI2 dataset and validated on the downstream task for AD classification. The proposed CMViM yields 2.7\% AUC performance improvement compared with other state-of-the-art methods.
BiSVP: Building Footprint Extraction via Bidirectional Serialized Vertex Prediction
Mar 01, 2023Extracting building footprints from remote sensing images has been attracting extensive attention recently. Dominant approaches address this challenging problem by generating vectorized building masks with cumbersome refinement stages, which limits the application of such methods. In this paper, we introduce a new refinement-free and end-to-end building footprint extraction method, which is conceptually intuitive, simple, and effective. Our method, termed as BiSVP, represents a building instance with ordered vertices and formulates the building footprint extraction as predicting the serialized vertices directly in a bidirectional fashion. Moreover, we propose a cross-scale feature fusion (CSFF) module to facilitate high resolution and rich semantic feature learning, which is essential for the dense building vertex prediction task. Without bells and whistles, our BiSVP outperforms state-of-the-art methods by considerable margins on three building instance segmentation benchmarks, clearly demonstrating its superiority. The code and datasets will be made public available.