 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Loss: A Confidence-Based Reweighting Strategy for Coarse Semantic Segmentation
Sep 11, 2020



Coarsely-labeled semantic segmentation annotations are easy to obtain, but therefore bear the risk of losing edge details and introducing background noise. Though they are usually used as a supplement to the finely-labeled ones, in this paper, we attempt to train a model only using these coarse annotations, and improve the model performance with a noise-robust reweighting strategy. Specifically, the proposed confidence indicator makes it possible to design a reweighting strategy that simultaneously mines hard samples and alleviates noisy labels for the coarse annotation. Besides, the optimal reweighting strategy can be automatically derived by our Adversarial Weight Assigning Module (AWAM) with only 53 learnable parameters. Moreover, a rigorous proof of the convergence of AWAM is given. Experiments on standard datasets show that our proposed reweighting strategy can bring consistent performance improvements for both coarse annotations and fine annotations. In particular, built on top of DeeplabV3+, we improve the mIoU on Cityscapes Coarse dataset (coarsely-labeled) and ADE20K (finely-labeled) by 2.21 and 0.91, respectively.
Pyramid Mask Text Detector
Mar 28, 2019

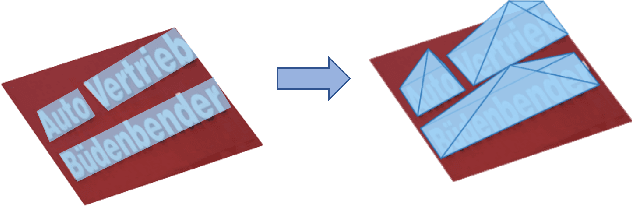
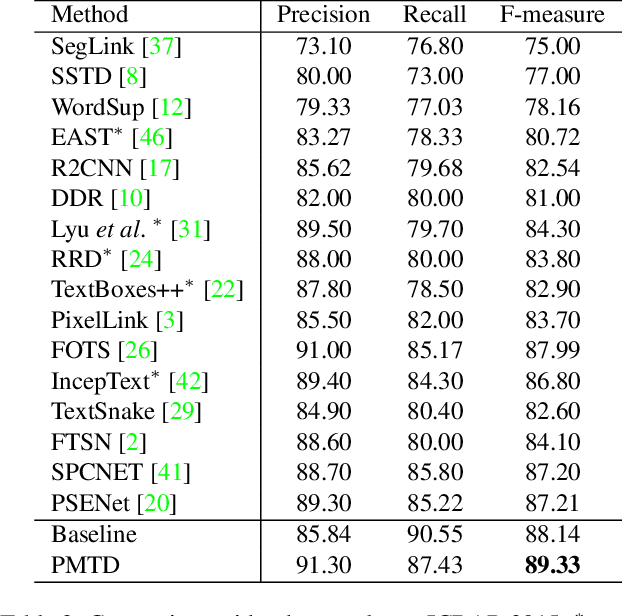
Scene text detection, an essential step of scene text recognition system, is to locate text instances in natural scene images automatically. Some recent attempts benefiting from Mask R-CNN formulate scene text detection task as an instance segmentation problem and achieve remarkable performance. In this paper, we present a new Mask R-CNN based framework named Pyramid Mask Text Detector (PMTD) to handle the scene text detection. Instead of binary text mask generated by the existing Mask R-CNN based methods, our PMTD performs pixel-level regression under the guidance of location-aware supervision, yielding a more informative soft text mask for each text instance. As for the generation of text boxes, PMTD reinterprets the obtained 2D soft mask into 3D space and introduces a novel plane clustering algorithm to derive the optimal text box on the basis of 3D shape. Experiments on standard datasets demonstrate that the proposed PMTD brings consistent and noticeable gain and clearly outperforms state-of-the-art methods. Specifically, it achieves an F-measure of 80.13% on ICDAR 2017 MLT dataset.