 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
ADAgent: LLM Agent for Alzheimer's Disease Analysis with Collaborative Coordinator
Jun 16, 2025Alzheimer's disease (AD) is a progressive and irreversible neurodegenerative disease. Early and precise diagnosis of AD is crucial for timely intervention and treatment planning to alleviate the progressive neurodegeneration. However, most existing methods rely on single-modality data, which contrasts with the multifaceted approach used by medical experts. While some deep learning approaches process multi-modal data, they are limited to specific tasks with a small set of input modalities and cannot handle arbitrary combinations. This highlights the need for a system that can address diverse AD-related tasks, process multi-modal or missing input, and integrate multiple advanced methods for improved performance. In this paper, we propose ADAgent, the first specialized AI agent for AD analysis, built on a large language model (LLM) to address user queries and support decision-making. ADAgent integrates a reasoning engine, specialized medical tools, and a collaborative outcome coordinator to facilitate multi-modal diagnosis and prognosis tasks in AD. Extensive experiments demonstrate that ADAgent outperforms SOTA methods, achieving significant improvements in accuracy, including a 2.7% increase in multi-modal diagnosis, a 0.7% improvement in multi-modal prognosis, and enhancements in MRI and PET diagnosis tasks.
CMViM: Contrastive Masked Vim Autoencoder for 3D Multi-modal Representation Learning for AD classification
Mar 25, 2024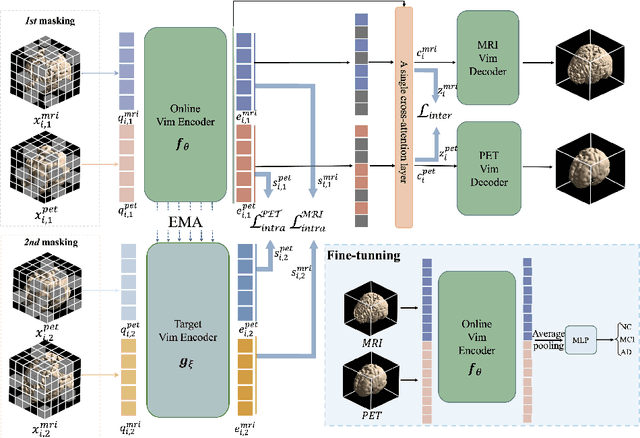
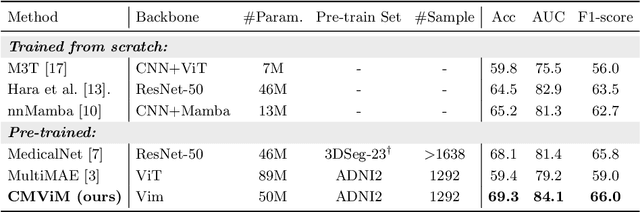
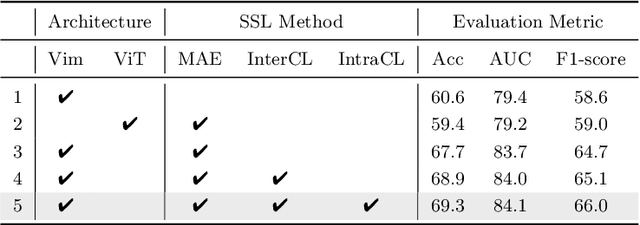
Alzheimer's disease (AD) is an incurable neurodegenerative condition leading to cognitive and functional deterioration. Given the lack of a cure, prompt and precise AD diagnosis is vital, a complex process dependent on multiple factors and multi-modal data. While successful efforts have been made to integrate multi-modal representation learning into medical datasets, scant attention has been given to 3D medical images. In this paper, we propose Contrastive Masked Vim Autoencoder (CMViM), the first efficient representation learning method tailored for 3D multi-modal data. Our proposed framework is built on a masked Vim autoencoder to learn a unified multi-modal representation and long-dependencies contained in 3D medical images. We also introduce an intra-modal contrastive learning module to enhance the capability of the multi-modal Vim encoder for modeling the discriminative features in the same modality, and an inter-modal contrastive learning module to alleviate misaligned representation among modalities. Our framework consists of two main steps: 1) incorporate the Vision Mamba (Vim) into the mask autoencoder to reconstruct 3D masked multi-modal data efficiently. 2) align the multi-modal representations with contrastive learning mechanisms from both intra-modal and inter-modal aspects. Our framework is pre-trained and validated ADNI2 dataset and validated on the downstream task for AD classification. The proposed CMViM yields 2.7\% AUC performance improvement compared with other state-of-the-art methods.
Exploring High-Order Structure for Robust Graph Structure Learning
Mar 22, 2022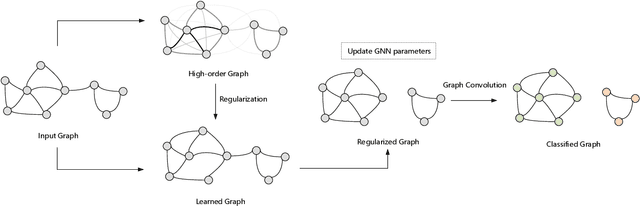
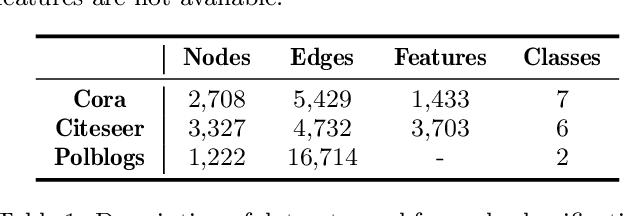
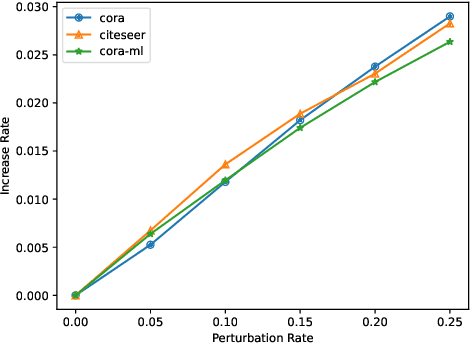
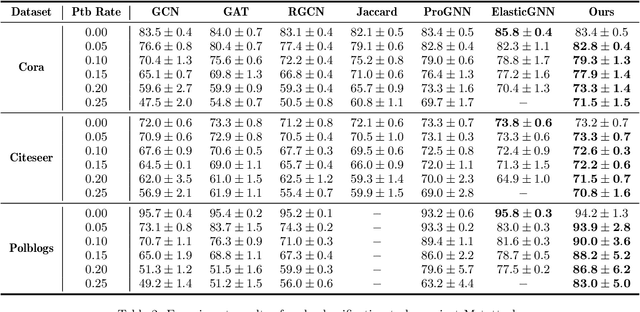
Recent studies show that Graph Neural Networks (GNNs) are vulnerable to adversarial attack, i.e., an imperceptible structure perturbation can fool GNNs to make wrong predictions. Some researches explore specific properties of clean graphs such as the feature smoothness to defense the attack, but the analysis of it has not been well-studied. In this paper, we analyze the adversarial attack on graphs from the perspective of feature smoothness which further contributes to an efficient new adversarial defensive algorithm for GNNs. We discover that the effect of the high-order graph structure is a smoother filter for processing graph structures. Intuitively, the high-order graph structure denotes the path number between nodes, where larger number indicates closer connection, so it naturally contributes to defense the adversarial perturbation. Further, we propose a novel algorithm that incorporates the high-order structural information into the graph structure learning. We perform experiments on three popular benchmark datasets, Cora, Citeseer and Polblogs. Extensive experiments demonstrate the effectiveness of our method for defending against graph adversarial attacks.