 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Logit Variation for Long-tailed Semantic Segmentation
Jun 03, 2023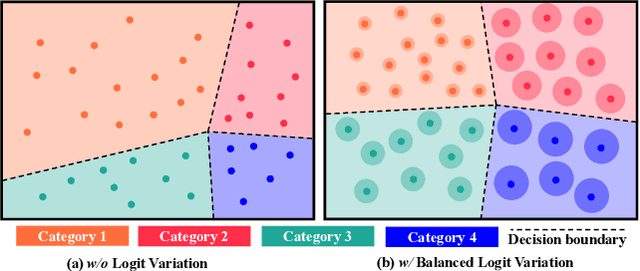

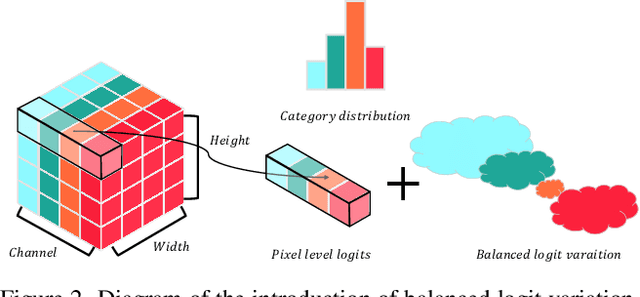
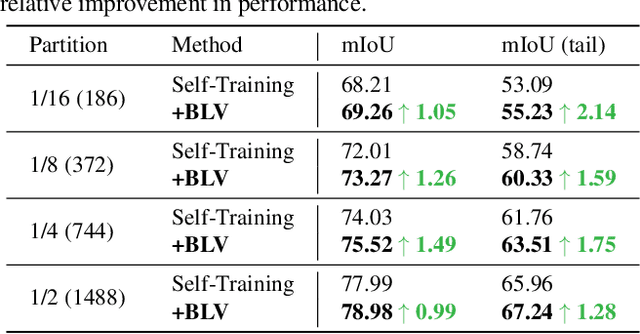
Semantic segmentation usually suffers from a long-tail data distribution. Due to the imbalanced number of samples across categories, the features of those tail classes may get squeezed into a narrow area in the feature space. Towards a balanced feature distribution, we introduce category-wise variation into the network predictions in the training phase such that an instance is no longer projected to a feature point, but a small region instead. Such a perturbation is highly dependent on the category scale, which appears as assigning smaller variation to head classes and larger variation to tail classes. In this way, we manage to close the gap between the feature areas of different categories, resulting in a more balanced representation. It is noteworthy that the introduced variation is discarded at the inference stage to facilitate a confident prediction. Although with an embarrassingly simple implementation, our method manifests itself in strong generalizability to various datasets and task settings. Extensive experiments suggest that our plug-in design lends itself well to a range of state-of-the-art approaches and boosts the performance on top of them.
Pulling Target to Source: A New Perspective on Domain Adaptive Semantic Segmentation
May 23, 2023



Domain adaptive semantic segmentation aims to transfer knowledge from a labeled source domain to an unlabeled target domain. However, existing methods primarily focus on directly learning qualified target features, making it challenging to guarantee their discrimination in the absence of target labels. This work provides a new perspective. We observe that the features learned with source data manage to keep categorically discriminative during training, thereby enabling us to implicitly learn adequate target representations by simply \textbf{pulling target features close to source features for each category}. To this end, we propose T2S-DA, which we interpret as a form of pulling Target to Source for Domain Adaptation, encouraging the model in learning similar cross-domain features. Also, considering the pixel categories are heavily imbalanced for segmentation datasets, we come up with a dynamic re-weighting strategy to help the model concentrate on those underperforming classes. Extensive experiments confirm that T2S-DA learns a more discriminative and generalizable representation, significantly surpassing the state-of-the-art. We further show that our method is quite qualified for the domain generalization task, verifying its domain-invariant property.
MIAD: A Maintenance Inspection Dataset for Unsupervised Anomaly Detection
Nov 28, 2022



Visual anomaly detection plays a crucial role in not only manufacturing inspection to find defects of products during manufacturing processes, but also maintenance inspection to keep equipment in optimum working condition particularly outdoors. Due to the scarcity of the defective samples, unsupervised anomaly detection has attracted great attention in recent years. However, existing datasets for unsupervised anomaly detection are biased towards manufacturing inspection, not considering maintenance inspection which is usually conducted under outdoor uncontrolled environment such as varying camera viewpoints, messy background and degradation of object surface after long-term working. We focus on outdoor maintenance inspection and contribute a comprehensive Maintenance Inspection Anomaly Detection (MIAD) dataset which contains more than 100K high-resolution color images in various outdoor industrial scenarios. This dataset is generated by a 3D graphics software and covers both surface and logical anomalies with pixel-precise ground truth. Extensive evaluations of representative algorithms for unsupervised anomaly detection are conducted, and we expect MIAD and corresponding experimental results can inspire research community in outdoor unsupervised anomaly detection tasks. Worthwhile and related future work can be spawned from our new dataset.
Learning from Future: A Novel Self-Training Framework for Semantic Segmentation
Sep 18, 2022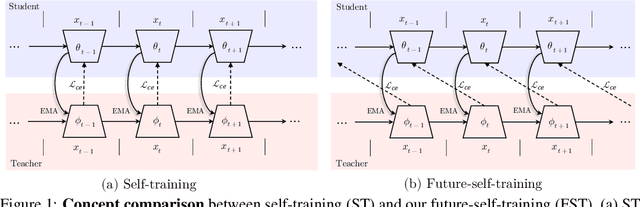
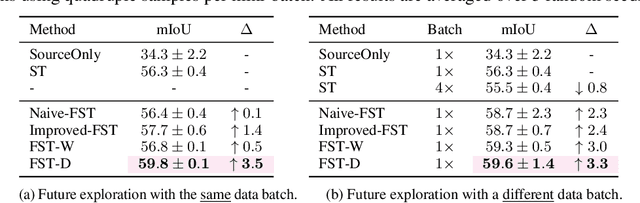
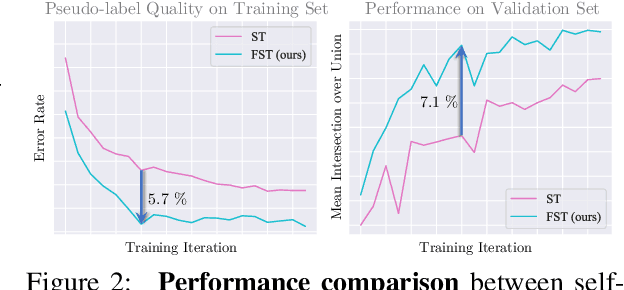
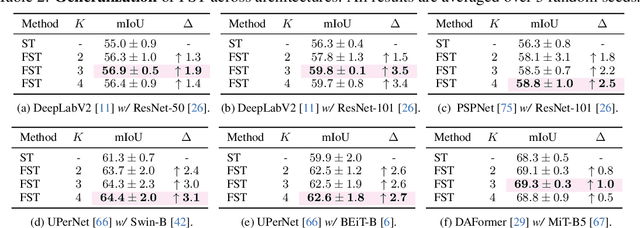
Self-training has shown great potential in semi-supervised learning. Its core idea is to use the model learned on labeled data to generate pseudo-labels for unlabeled samples, and in turn teach itself. To obtain valid supervision, active attempts typically employ a momentum teacher for pseudo-label prediction yet observe the confirmation bias issue, where the incorrect predictions may provide wrong supervision signals and get accumulated in the training process. The primary cause of such a drawback is that the prevailing self-training framework acts as guiding the current state with previous knowledge, because the teacher is updated with the past student only. To alleviate this problem, we propose a novel self-training strategy, which allows the model to learn from the future. Concretely, at each training step, we first virtually optimize the student (i.e., caching the gradients without applying them to the model weights), then update the teacher with the virtual future student, and finally ask the teacher to produce pseudo-labels for the current student as the guidance. In this way, we manage to improve the quality of pseudo-labels and thus boost the performance. We also develop two variants of our future-self-training (FST) framework through peeping at the future both deeply (FST-D) and widely (FST-W). Taking the tasks of unsupervised domain adaptive semantic segmentation and semi-supervised semantic segmentation as the instances, we experimentally demonstrate the effectiveness and superiority of our approach under a wide range of settings. Code will be made publicly available.
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Mar 14, 2022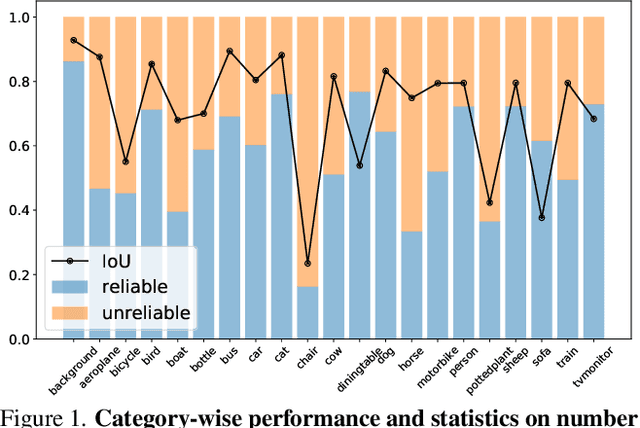
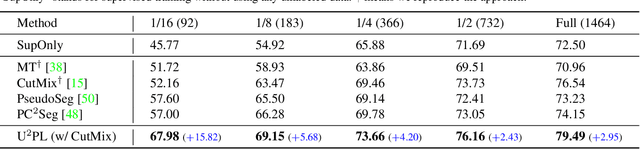
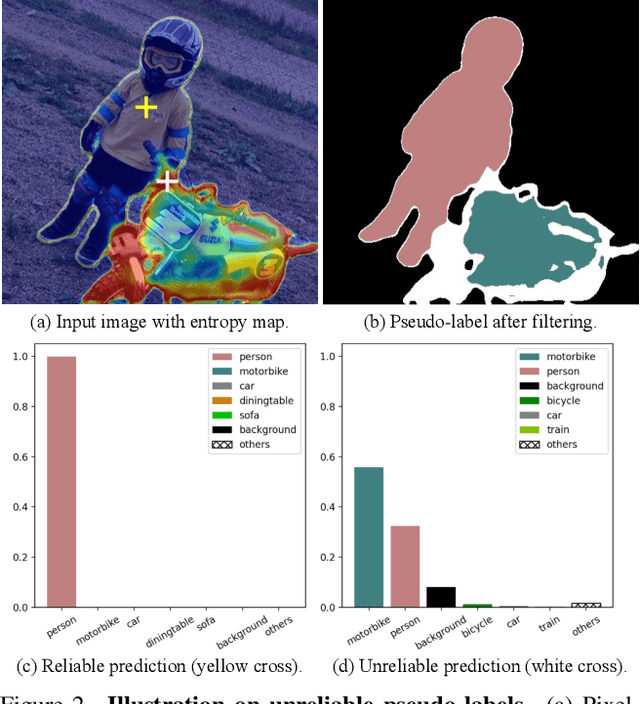
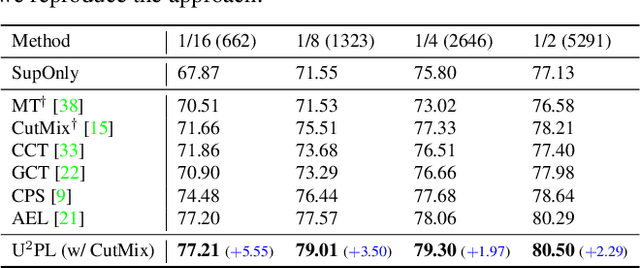
The crux of semi-supervised semantic segmentation is to assign adequate pseudo-labels to the pixels of unlabeled images. A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability. We argue that every pixel matters to the model training, even its prediction is ambiguous. Intuitively, an unreliable prediction may get confused among the top classes (i.e., those with the highest probabilities), however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative sample to those most unlikely categories. Based on this insight, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative samples, and manage to train the model with all candidate pixels. Considering the training evolution, where the prediction becomes more and more accurate, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.
A Variant of Gaussian Process Dynamical Systems
Jun 09, 2019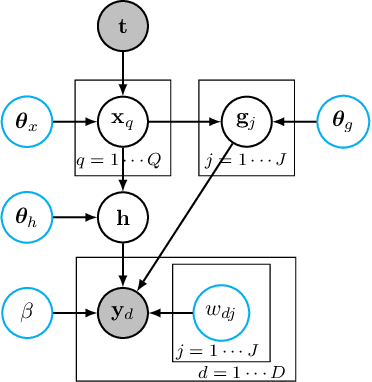
In order to better model high-dimensional sequential data, we propose a collaborative multi-output Gaussian process dynamical system (CGPDS), which is a novel variant of GPDSs. The proposed model assumes that the output on each dimension is controlled by a shared global latent process and a private local latent process. Thus, the dependence among different dimensions of the sequences can be captured, and the unique characteristics of each dimension of the sequences can be maintained. For training models and making prediction, we introduce inducing points and adopt stochastic variational inference methods.
Online Anomaly Detection with Sparse Gaussian Processes
May 14, 2019
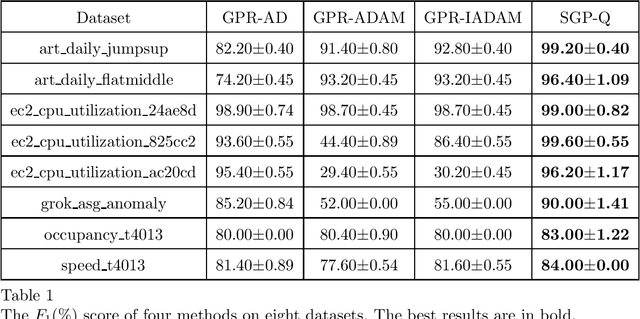
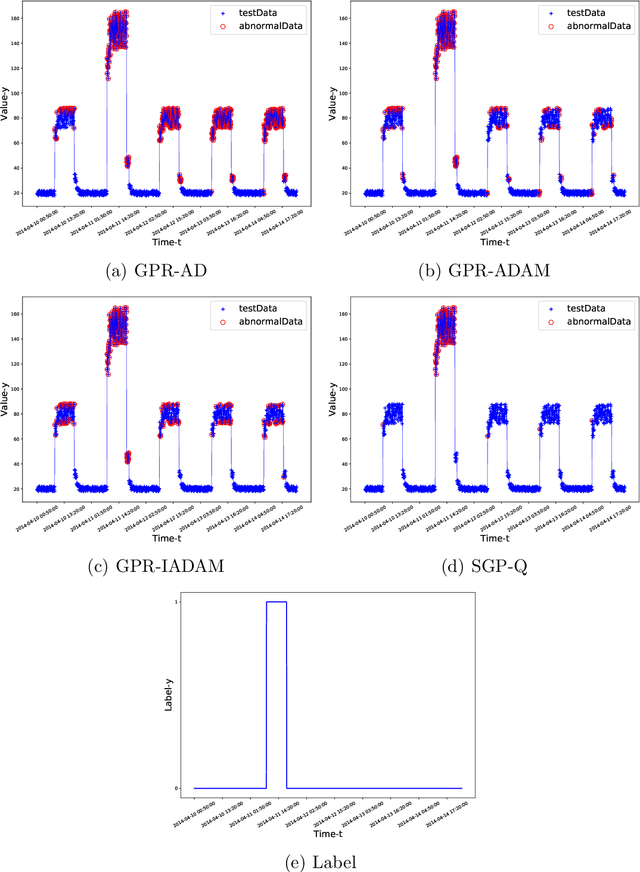
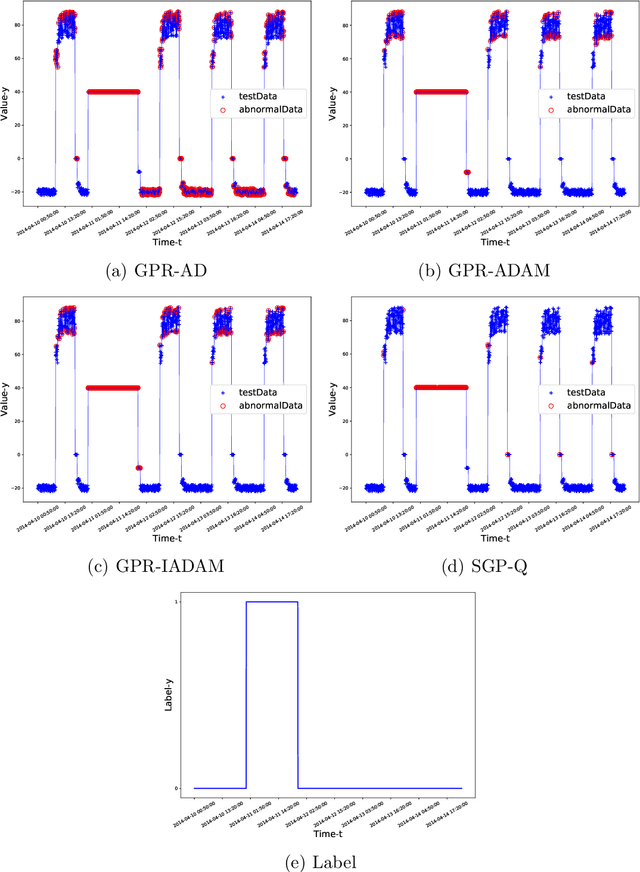
Online anomaly detection of time-series data is an important and challenging task in machine learning. Gaussian processes (GPs) are powerful and flexible models for modeling time-series data. However, the high time complexity of GPs limits their applications in online anomaly detection. Attributed to some internal or external changes, concept drift usually occurs in time-series data, where the characteristics of data and meanings of abnormal behaviors alter over time. Online anomaly detection methods should have the ability to adapt to concept drift. Motivated by the above facts, this paper proposes the method of sparse Gaussian processes with Q-function (SGP-Q). The SGP-Q employs sparse Gaussian processes (SGPs) whose time complexity is lower than that of GPs, thus significantly speeding up online anomaly detection. By using Q-function properly, the SGP-Q can adapt to concept drift well. Moreover, the SGP-Q makes use of few abnormal data in the training data by its strategy of updating training data, resulting in more accurate sparse Gaussian process regression models and better anomaly detection results. We evaluate the SGP-Q on various artificial and real-world datasets. Experimental results validate the effectiveness of the SGP-Q.