 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Dual Perception for MLLMs in High-Resolution Text-Rich Image Translation
Feb 25, 2026Text Image Machine Translation (TIMT) aims to translate text embedded in images in the source-language into target-language, requiring synergistic integration of visual perception and linguistic understanding. Existing TIMT methods, whether cascaded pipelines or end-to-end multimodal large language models (MLLMs),struggle with high-resolution text-rich images due to cluttered layouts, diverse fonts, and non-textual distractions, resulting in text omission, semantic drift, and contextual inconsistency. To address these challenges, we propose GLoTran, a global-local dual visual perception framework for MLLM-based TIMT. GLoTran integrates a low-resolution global image with multi-scale region-level text image slices under an instruction-guided alignment strategy, conditioning MLLMs to maintain scene-level contextual consistency while faithfully capturing fine-grained textual details. Moreover, to realize this dual-perception paradigm, we construct GLoD, a large-scale text-rich TIMT dataset comprising 510K high-resolution global-local image-text pairs covering diverse real-world scenarios. Extensive experiments demonstrate that GLoTran substantially improves translation completeness and accuracy over state-of-the-art MLLMs, offering a new paradigm for fine-grained TIMT under high-resolution and text-rich conditions.
LEMON: How Well Do MLLMs Perform Temporal Multimodal Understanding on Instructional Videos?
Jan 27, 2026Recent multimodal large language models (MLLMs) have shown remarkable progress across vision, audio, and language tasks, yet their performance on long-form, knowledge-intensive, and temporally structured educational content remains largely unexplored. To bridge this gap, we introduce LEMON, a Lecture-based Evaluation benchmark for MultimOdal uNderstanding, focusing on STEM lecture videos that require long-horizon reasoning and cross-modal integration. LEMON comprises 2,277 video segments spanning 5 disciplines and 29 courses, with an average duration of 196.1 seconds, yielding 4,181 high-quality QA pairs, including 3,413 multiple-choice and 768 open-ended questions. Distinct from existing video benchmarks, LEMON features: (1) semantic richness and disciplinary density, (2) tightly coupled video-audio-text modalities, (3) explicit temporal and pedagogical structure, and (4) contextually linked multi-turn questioning. It further encompasses six major tasks and twelve subtasks, covering the full cognitive spectrum from perception to reasoning and then to generation. Comprehensive experiments reveal substantial performance gaps across tasks, highlighting that even state-of-the-art MLLMs like GPT-4o struggle with temporal reasoning and instructional prediction. We expect LEMON to serve as an extensible and challenging benchmark for advancing multimodal perception, reasoning, and generation in long-form instructional contents.
Revealing the Challenges of Sim-to-Real Transfer in Model-Based Reinforcement Learning via Latent Space Modeling
Jun 15, 2025



Reinforcement learning (RL) is playing an increasingly important role in fields such as robotic control and autonomous driving. However, the gap between simulation and the real environment remains a major obstacle to the practical deployment of RL. Agents trained in simulators often struggle to maintain performance when transferred to real-world physical environments. In this paper, we propose a latent space based approach to analyze the impact of simulation on real-world policy improvement in model-based settings. As a natural extension of model-based methods, our approach enables an intuitive observation of the challenges faced by model-based methods in sim-to-real transfer. Experiments conducted in the MuJoCo environment evaluate the performance of our method in both measuring and mitigating the sim-to-real gap. The experiments also highlight the various challenges that remain in overcoming the sim-to-real gap, especially for model-based methods.
Multimodal Machine Translation with Visual Scene Graph Pruning
May 26, 2025Multimodal machine translation (MMT) seeks to address the challenges posed by linguistic polysemy and ambiguity in translation tasks by incorporating visual information. A key bottleneck in current MMT research is the effective utilization of visual data. Previous approaches have focused on extracting global or region-level image features and using attention or gating mechanisms for multimodal information fusion. However, these methods have not adequately tackled the issue of visual information redundancy in MMT, nor have they proposed effective solutions. In this paper, we introduce a novel approach--multimodal machine translation with visual Scene Graph Pruning (PSG), which leverages language scene graph information to guide the pruning of redundant nodes in visual scene graphs, thereby reducing noise in downstream translation tasks. Through extensive comparative experiments with state-of-the-art methods and ablation studies, we demonstrate the effectiveness of the PSG model. Our results also highlight the promising potential of visual information pruning in advancing the field of MMT.
Memory Reviving, Continuing Learning and Beyond: Evaluation of Pre-trained Encoders and Decoders for Multimodal Machine Translation
Apr 25, 2025Multimodal Machine Translation (MMT) aims to improve translation quality by leveraging auxiliary modalities such as images alongside textual input. While recent advances in large-scale pre-trained language and vision models have significantly benefited unimodal natural language processing tasks, their effectiveness and role in MMT remain underexplored. In this work, we conduct a systematic study on the impact of pre-trained encoders and decoders in multimodal translation models. Specifically, we analyze how different training strategies, from training from scratch to using pre-trained and partially frozen components, affect translation performance under a unified MMT framework. Experiments are carried out on the Multi30K and CoMMuTE dataset across English-German and English-French translation tasks. Our results reveal that pre-training plays a crucial yet asymmetrical role in multimodal settings: pre-trained decoders consistently yield more fluent and accurate outputs, while pre-trained encoders show varied effects depending on the quality of visual-text alignment. Furthermore, we provide insights into the interplay between modality fusion and pre-trained components, offering guidance for future architecture design in multimodal translation systems.
Evaluating Menu OCR and Translation: A Benchmark for Aligning Human and Automated Evaluations in Large Vision-Language Models
Apr 22, 2025The rapid advancement of large vision-language models (LVLMs) has significantly propelled applications in document understanding, particularly in optical character recognition (OCR) and multilingual translation. However, current evaluations of LVLMs, like the widely used OCRBench, mainly focus on verifying the correctness of their short-text responses and long-text responses with simple layout, while the evaluation of their ability to understand long texts with complex layout design is highly significant but largely overlooked. In this paper, we propose Menu OCR and Translation Benchmark (MOTBench), a specialized evaluation framework emphasizing the pivotal role of menu translation in cross-cultural communication. MOTBench requires LVLMs to accurately recognize and translate each dish, along with its price and unit items on a menu, providing a comprehensive assessment of their visual understanding and language processing capabilities. Our benchmark is comprised of a collection of Chinese and English menus, characterized by intricate layouts, a variety of fonts, and culturally specific elements across different languages, along with precise human annotations. Experiments show that our automatic evaluation results are highly consistent with professional human evaluation. We evaluate a range of publicly available state-of-the-art LVLMs, and through analyzing their output to identify the strengths and weaknesses in their performance, offering valuable insights to guide future advancements in LVLM development. MOTBench is available at https://github.com/gitwzl/MOTBench.
MST-GAT: A Multimodal Spatial-Temporal Graph Attention Network for Time Series Anomaly Detection
Oct 17, 2023Multimodal time series (MTS) anomaly detection is crucial for maintaining the safety and stability of working devices (e.g., water treatment system and spacecraft), whose data are characterized by multivariate time series with diverse modalities. Although recent deep learning methods show great potential in anomaly detection, they do not explicitly capture spatial-temporal relationships between univariate time series of different modalities, resulting in more false negatives and false positives. In this paper, we propose a multimodal spatial-temporal graph attention network (MST-GAT) to tackle this problem. MST-GAT first employs a multimodal graph attention network (M-GAT) and a temporal convolution network to capture the spatial-temporal correlation in multimodal time series. Specifically, M-GAT uses a multi-head attention module and two relational attention modules (i.e., intra- and inter-modal attention) to model modal correlations explicitly. Furthermore, MST-GAT optimizes the reconstruction and prediction modules simultaneously. Experimental results on four multimodal benchmarks demonstrate that MST-GAT outperforms the state-of-the-art baselines. Further analysis indicates that MST-GAT strengthens the interpretability of detected anomalies by locating the most anomalous univariate time series.
GNN-XML: Graph Neural Networks for Extreme Multi-label Text Classification
Dec 10, 2020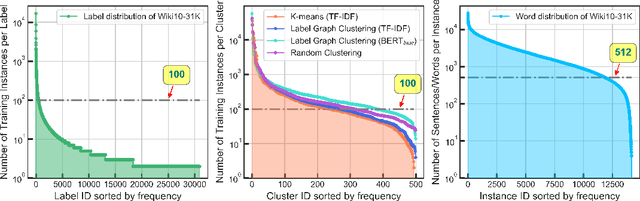
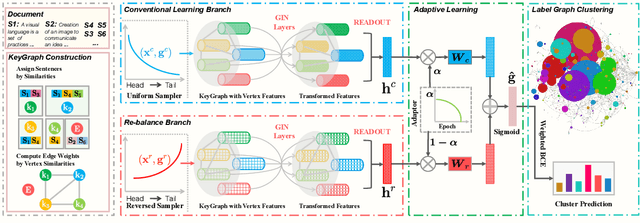
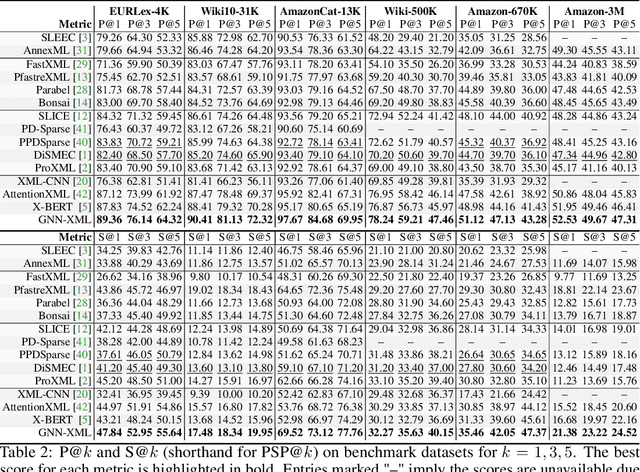
Extreme multi-label text classification (XMTC) aims to tag a text instance with the most relevant subset of labels from an extremely large label set. XMTC has attracted much recent attention due to massive label sets yielded by modern applications, such as news annotation and product recommendation. The main challenges of XMTC are the data scalability and sparsity, thereby leading to two issues: i) the intractability to scale to the extreme label setting, ii) the presence of long-tailed label distribution, implying that a large fraction of labels have few positive training instances. To overcome these problems, we propose GNN-XML, a scalable graph neural network framework tailored for XMTC problems. Specifically, we exploit label correlations via mining their co-occurrence patterns and build a label graph based on the correlation matrix. We then conduct the attributed graph clustering by performing graph convolution with a low-pass graph filter to jointly model label dependencies and label features, which induces semantic label clusters. We further propose a bilateral-branch graph isomorphism network to decouple representation learning and classifier learning for better modeling tail labels. Experimental results on multiple benchmark datasets show that GNN-XML significantly outperforms state-of-the-art methods while maintaining comparable prediction efficiency and model size.
Manifold Partition Discriminant Analysis
Nov 23, 2020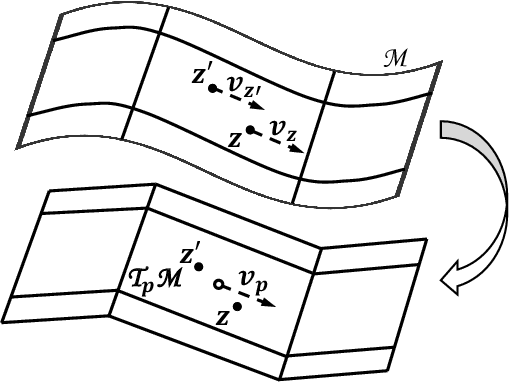
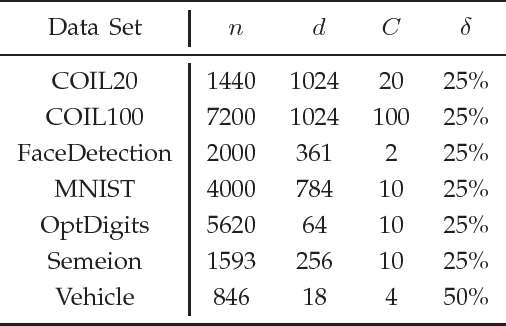
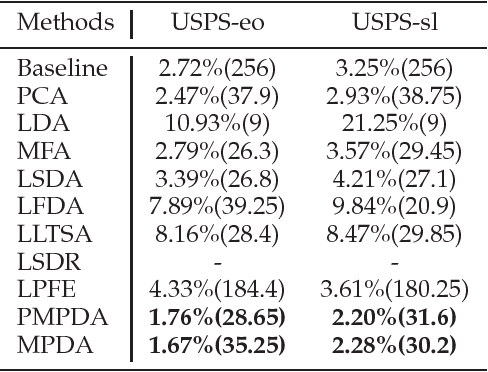
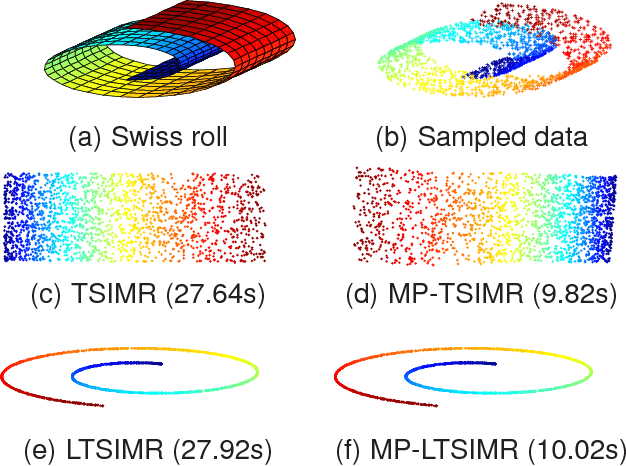
We propose a novel algorithm for supervised dimensionality reduction named Manifold Partition Discriminant Analysis (MPDA). It aims to find a linear embedding space where the within-class similarity is achieved along the direction that is consistent with the local variation of the data manifold, while nearby data belonging to different classes are well separated. By partitioning the data manifold into a number of linear subspaces and utilizing the first-order Taylor expansion, MPDA explicitly parameterizes the connections of tangent spaces and represents the data manifold in a piecewise manner. While graph Laplacian methods capture only the pairwise interaction between data points, our method capture both pairwise and higher order interactions (using regional consistency) between data points. This manifold representation can help to improve the measure of within-class similarity, which further leads to improved performance of dimensionality reduction. Experimental results on multiple real-world data sets demonstrate the effectiveness of the proposed method.
Adversarial Attacks for Multi-view Deep Models
Jun 19, 2020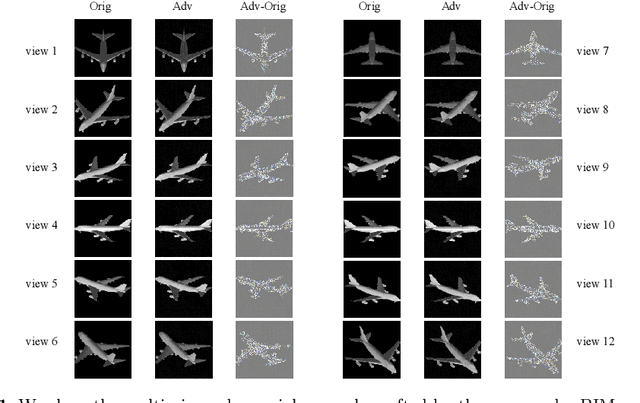
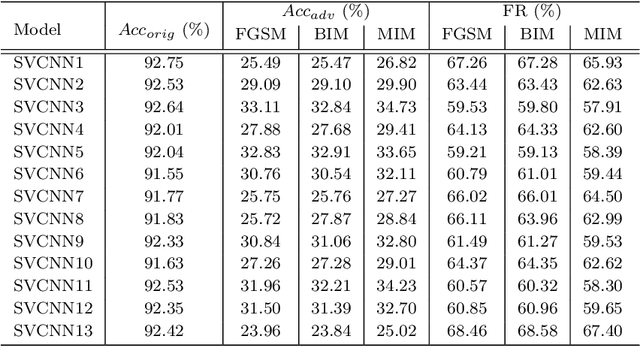
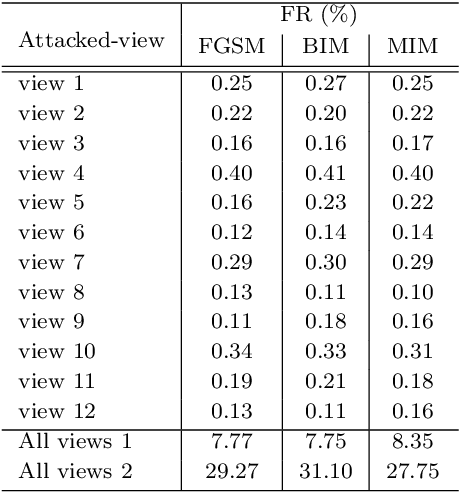
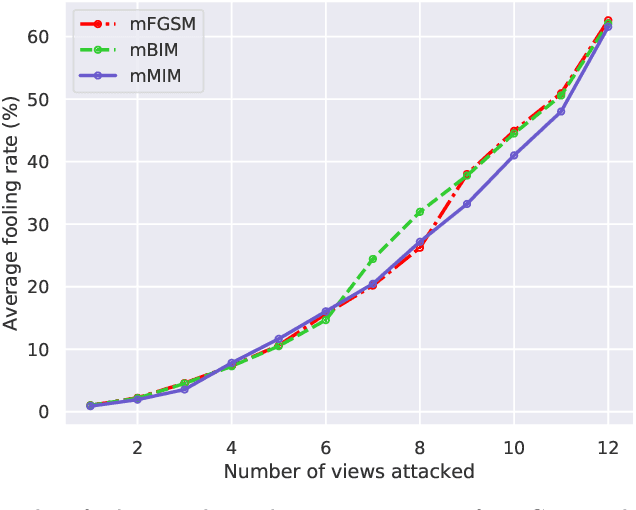
Recent work has highlighted the vulnerability of many deep machine learning models to adversarial examples. It attracts increasing attention to adversarial attacks, which can be used to evaluate the security and robustness of models before they are deployed. However, to our best knowledge, there is no specific research on the adversarial attacks for multi-view deep models. This paper proposes two multi-view attack strategies, two-stage attack (TSA) and end-to-end attack (ETEA). With the mild assumption that the single-view model on which the target multi-view model is based is known, we first propose the TSA strategy. The main idea of TSA is to attack the multi-view model with adversarial examples generated by attacking the associated single-view model, by which state-of-the-art single-view attack methods are directly extended to the multi-view scenario. Then we further propose the ETEA strategy when the multi-view model is provided publicly. The ETEA is applied to accomplish direct attacks on the target multi-view model, where we develop three effective multi-view attack methods. Finally, based on the fact that adversarial examples generalize well among different models, this paper takes the adversarial attack on the multi-view convolutional neural network as an example to validate that the effectiveness of the proposed multi-view attacks. Extensive experimental results demonstrate that our multi-view attack strategies are capable of attacking the multi-view deep models, and we additionally find that multi-view models are more robust than single-view models.