 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025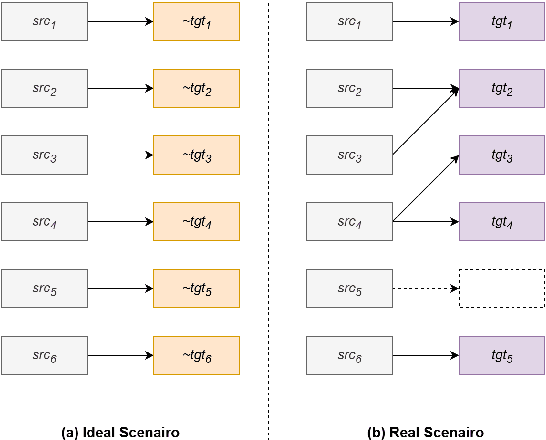
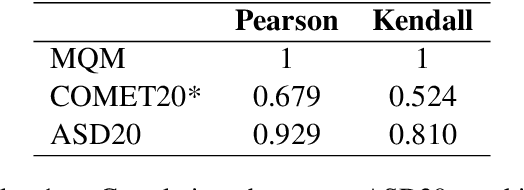
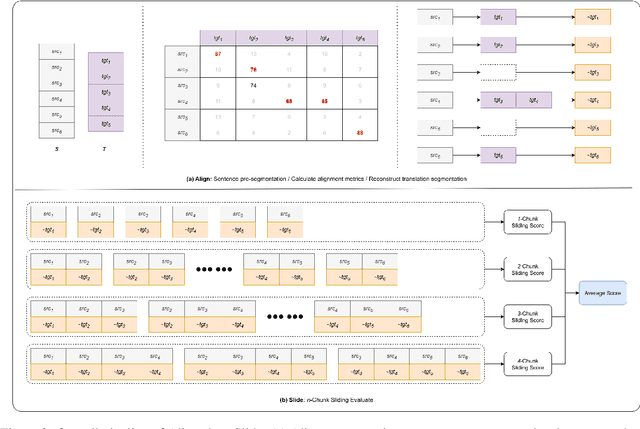
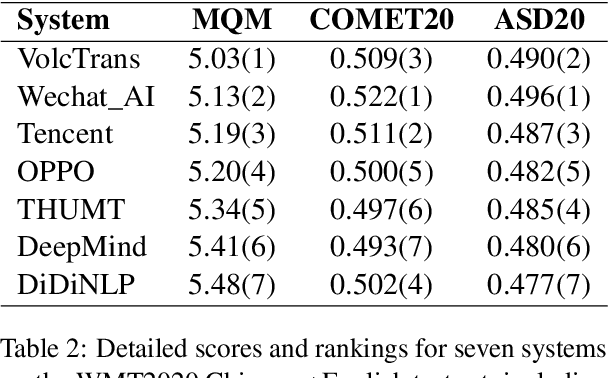
Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

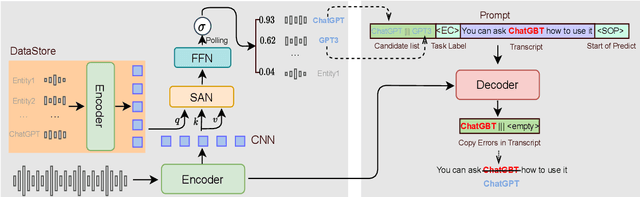

End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.
PromptEVC: Controllable Emotional Voice Conversion with Natural Language Prompts
May 27, 2025Controllable emotional voice conversion (EVC) aims to manipulate emotional expressions to increase the diversity of synthesized speech. Existing methods typically rely on predefined labels, reference audios, or prespecified factor values, often overlooking individual differences in emotion perception and expression. In this paper, we introduce PromptEVC that utilizes natural language prompts for precise and flexible emotion control. To bridge text descriptions with emotional speech, we propose emotion descriptor and prompt mapper to generate fine-grained emotion embeddings, trained jointly with reference embeddings. To enhance naturalness, we present a prosody modeling and control pipeline that adjusts the rhythm based on linguistic content and emotional cues. Additionally, a speaker encoder is incorporated to preserve identity. Experimental results demonstrate that PromptEVC outperforms state-of-the-art controllable EVC methods in emotion conversion, intensity control, mixed emotion synthesis, and prosody manipulation. Speech samples are available at https://jeremychee4.github.io/PromptEVC/.
DIMT25@ICDAR2025: HW-TSC's End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Apr 24, 2025This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the "End-to-End Document Image Machine Translation for Complex Layouts" competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system's translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
Evaluating Menu OCR and Translation: A Benchmark for Aligning Human and Automated Evaluations in Large Vision-Language Models
Apr 22, 2025The rapid advancement of large vision-language models (LVLMs) has significantly propelled applications in document understanding, particularly in optical character recognition (OCR) and multilingual translation. However, current evaluations of LVLMs, like the widely used OCRBench, mainly focus on verifying the correctness of their short-text responses and long-text responses with simple layout, while the evaluation of their ability to understand long texts with complex layout design is highly significant but largely overlooked. In this paper, we propose Menu OCR and Translation Benchmark (MOTBench), a specialized evaluation framework emphasizing the pivotal role of menu translation in cross-cultural communication. MOTBench requires LVLMs to accurately recognize and translate each dish, along with its price and unit items on a menu, providing a comprehensive assessment of their visual understanding and language processing capabilities. Our benchmark is comprised of a collection of Chinese and English menus, characterized by intricate layouts, a variety of fonts, and culturally specific elements across different languages, along with precise human annotations. Experiments show that our automatic evaluation results are highly consistent with professional human evaluation. We evaluate a range of publicly available state-of-the-art LVLMs, and through analyzing their output to identify the strengths and weaknesses in their performance, offering valuable insights to guide future advancements in LVLM development. MOTBench is available at https://github.com/gitwzl/MOTBench.
Doc-Guided Sent2Sent++: A Sent2Sent++ Agent with Doc-Guided memory for Document-level Machine Translation
Jan 15, 2025



The field of artificial intelligence has witnessed significant advancements in natural language processing, largely attributed to the capabilities of Large Language Models (LLMs). These models form the backbone of Agents designed to address long-context dependencies, particularly in Document-level Machine Translation (DocMT). DocMT presents unique challenges, with quality, consistency, and fluency being the key metrics for evaluation. Existing approaches, such as Doc2Doc and Doc2Sent, either omit sentences or compromise fluency. This paper introduces Doc-Guided Sent2Sent++, an Agent that employs an incremental sentence-level forced decoding strategy \textbf{to ensure every sentence is translated while enhancing the fluency of adjacent sentences.} Our Agent leverages a Doc-Guided Memory, focusing solely on the summary and its translation, which we find to be an efficient approach to maintaining consistency. Through extensive testing across multiple languages and domains, we demonstrate that Sent2Sent++ outperforms other methods in terms of quality, consistency, and fluency. The results indicate that, our approach has achieved significant improvements in metrics such as s-COMET, d-COMET, LTCR-$1_f$, and document-level perplexity (d-ppl). The contributions of this paper include a detailed analysis of current DocMT research, the introduction of the Sent2Sent++ decoding method, the Doc-Guided Memory mechanism, and validation of its effectiveness across languages and domains.
M-Ped: Multi-Prompt Ensemble Decoding for Large Language Models
Dec 24, 2024



With the widespread application of Large Language Models (LLMs) in the field of Natural Language Processing (NLP), enhancing their performance has become a research hotspot. This paper presents a novel multi-prompt ensemble decoding approach designed to bolster the generation quality of LLMs by leveraging the aggregation of outcomes from multiple prompts. Given a unique input $X$, we submit $n$ variations of prompts with $X$ to LLMs in batch mode to decode and derive probability distributions. For each token prediction, we calculate the ensemble probability by averaging the $n$ probability distributions within the batch, utilizing this aggregated probability to generate the token. This technique is dubbed Inner-Batch Ensemble. To facilitate efficient batch inference, we implement a Left-Padding strategy to maintain uniform input lengths across the n prompts. Through extensive experimentation on diverse NLP tasks, including machine translation, code generation, and text simplification, we demonstrate the efficacy of our method in enhancing LLM performance. The results show substantial improvements in BLEU scores, pass@$k$ rates, and LENS metrics over conventional methods.
Context-aware and Style-related Incremental Decoding framework for Discourse-Level Literary Translation
Sep 25, 2024



This report outlines our approach for the WMT24 Discourse-Level Literary Translation Task, focusing on the Chinese-English language pair in the Constrained Track. Translating literary texts poses significant challenges due to the nuanced meanings, idiomatic expressions, and intricate narrative structures inherent in such works. To address these challenges, we leveraged the Chinese-Llama2 model, specifically enhanced for this task through a combination of Continual Pre-training (CPT) and Supervised Fine-Tuning (SFT). Our methodology includes a novel Incremental Decoding framework, which ensures that each sentence is translated with consideration of its broader context, maintaining coherence and consistency throughout the text. This approach allows the model to capture long-range dependencies and stylistic elements, producing translations that faithfully preserve the original literary quality. Our experiments demonstrate significant improvements in both sentence-level and document-level BLEU scores, underscoring the effectiveness of our proposed framework in addressing the complexities of document-level literary translation.
Multilingual Transfer and Domain Adaptation for Low-Resource Languages of Spain
Sep 24, 2024This article introduces the submission status of the Translation into Low-Resource Languages of Spain task at (WMT 2024) by Huawei Translation Service Center (HW-TSC). We participated in three translation tasks: spanish to aragonese (es-arg), spanish to aranese (es-arn), and spanish to asturian (es-ast). For these three translation tasks, we use training strategies such as multilingual transfer, regularized dropout, forward translation and back translation, labse denoising, transduction ensemble learning and other strategies to neural machine translation (NMT) model based on training deep transformer-big architecture. By using these enhancement strategies, our submission achieved a competitive result in the final evaluation.
Exploring the traditional NMT model and Large Language Model for chat translation
Sep 24, 2024



This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$\leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.