 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Improving Interpretability of Word Embeddings by Generating Definition and Usage
Dec 12, 2019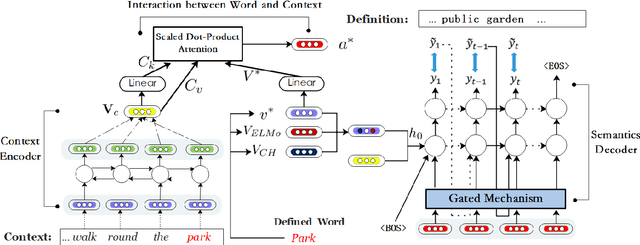
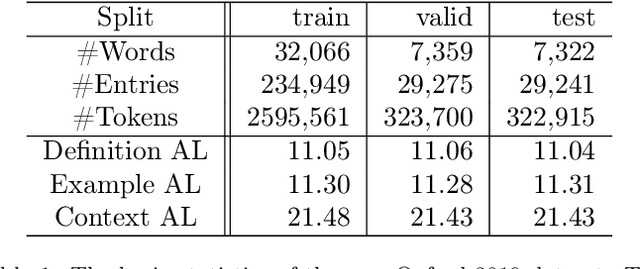
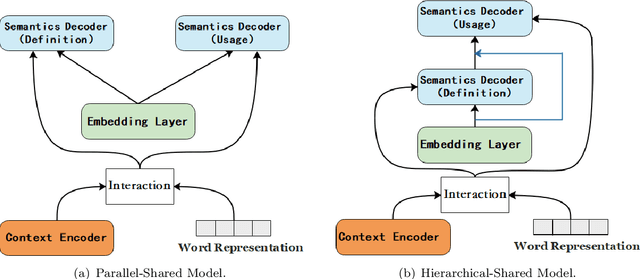
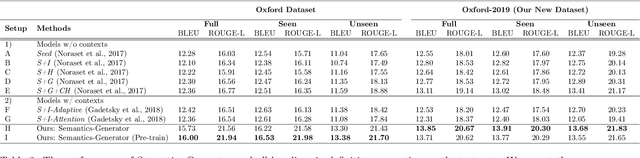
Word Embeddings, which encode semantic and syntactic features, have achieved success in many natural language processing tasks recently. However, the lexical semantics captured by these embeddings are difficult to interpret due to the dense vector representations. In order to improve the interpretability of word vectors, we explore definition modeling task and propose a novel framework (Semantics-Generator) to generate more reasonable and understandable context-dependent definitions. Moreover, we introduce usage modeling and study whether it is possible to utilize distributed representations to generate example sentences of words. These ways of semantics generation are a more direct and explicit expression of embedding's semantics. Two multi-task learning methods are used to combine usage modeling and definition modeling. To verify our approach, we construct Oxford-2019 dataset, where each entry contains word, context, example sentence and corresponding definition. Experimental results show that Semantics-Generator achieves the state-of-the-art result in definition modeling and the multi-task learning methods are helpful for two tasks to improve the performance.