 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Interpretability of Word Embeddings by Generating Definition and Usage
Paper and Code
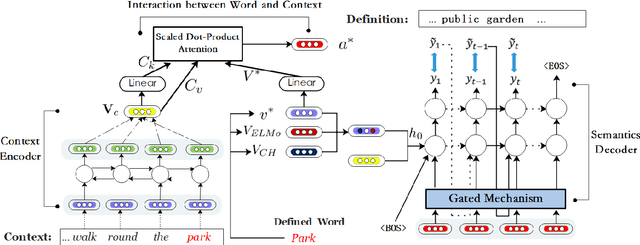
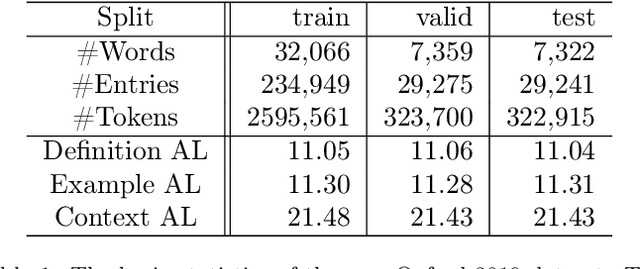
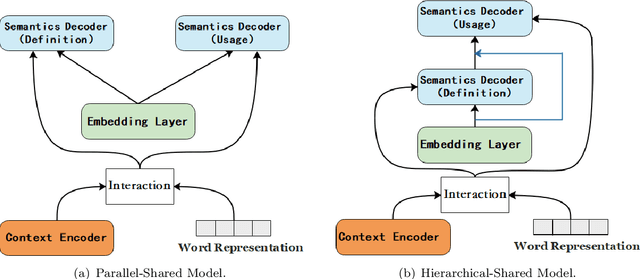
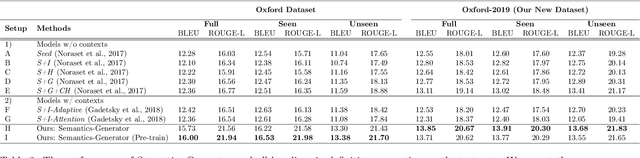
Word Embeddings, which encode semantic and syntactic features, have achieved success in many natural language processing tasks recently. However, the lexical semantics captured by these embeddings are difficult to interpret due to the dense vector representations. In order to improve the interpretability of word vectors, we explore definition modeling task and propose a novel framework (Semantics-Generator) to generate more reasonable and understandable context-dependent definitions. Moreover, we introduce usage modeling and study whether it is possible to utilize distributed representations to generate example sentences of words. These ways of semantics generation are a more direct and explicit expression of embedding's semantics. Two multi-task learning methods are used to combine usage modeling and definition modeling. To verify our approach, we construct Oxford-2019 dataset, where each entry contains word, context, example sentence and corresponding definition. Experimental results show that Semantics-Generator achieves the state-of-the-art result in definition modeling and the multi-task learning methods are helpful for two tasks to improve the performance.