 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Domain Adaptation for Grammatical Error Correction via Meta-Learning
Jan 29, 2021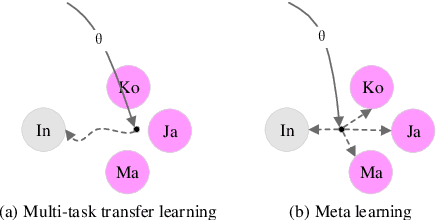
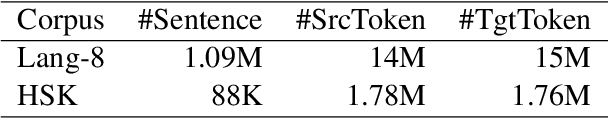
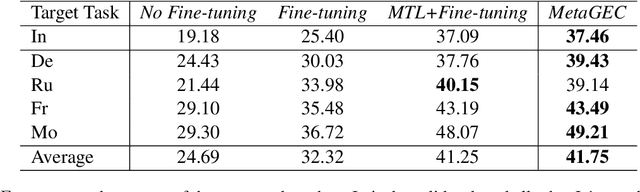
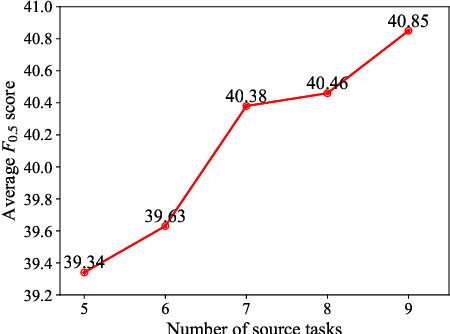
Most existing Grammatical Error Correction (GEC) methods based on sequence-to-sequence mainly focus on how to generate more pseudo data to obtain better performance. Few work addresses few-shot GEC domain adaptation. In this paper, we treat different GEC domains as different GEC tasks and propose to extend meta-learning to few-shot GEC domain adaptation without using any pseudo data. We exploit a set of data-rich source domains to learn the initialization of model parameters that facilitates fast adaptation on new resource-poor target domains. We adapt GEC model to the first language (L1) of the second language learner. To evaluate the proposed method, we use nine L1s as source domains and five L1s as target domains. Experiment results on the L1 GEC domain adaptation dataset demonstrate that the proposed approach outperforms the multi-task transfer learning baseline by 0.50 $F_{0.5}$ score on average and enables us to effectively adapt to a new L1 domain with only 200 parallel sentences.
Controllable Data Synthesis Method for Grammatical Error Correction
Oct 02, 2019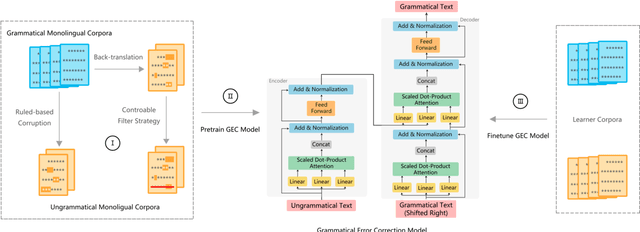


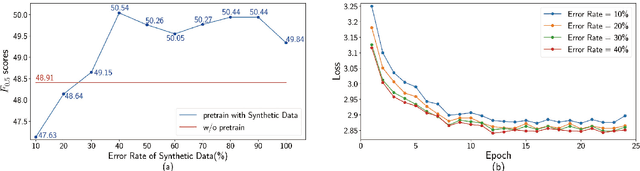
Due to the lack of parallel data in current Grammatical Error Correction (GEC) task, models based on Sequence to Sequence framework cannot be adequately trained to obtain higher performance. We propose two data synthesis methods which can control the error rate and the ratio of error types on synthetic data. The first approach is to corrupt each word in the monolingual corpus with a fixed probability, including replacement, insertion and deletion. Another approach is to train error generation models and further filtering the decoding results of the models. The experiments on different synthetic data show that the error rate is 40% and the ratio of error types is the same can improve the model performance better. Finally, we synthesize about 100 million data and achieve comparable performance as the state of the art, which uses twice as much data as we use.