 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Domain Adaptation for Grammatical Error Correction via Meta-Learning
Paper and Code
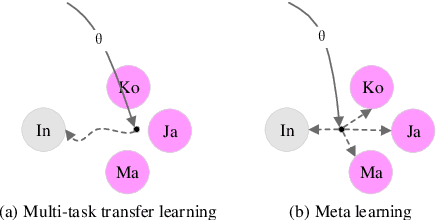
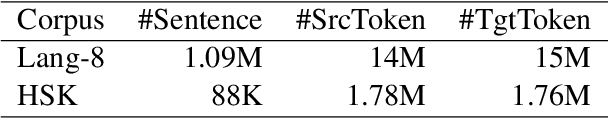
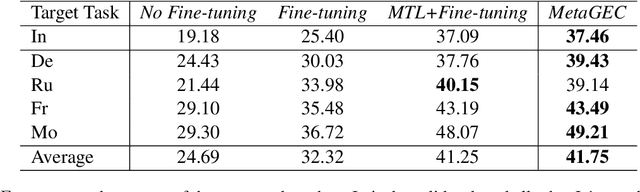
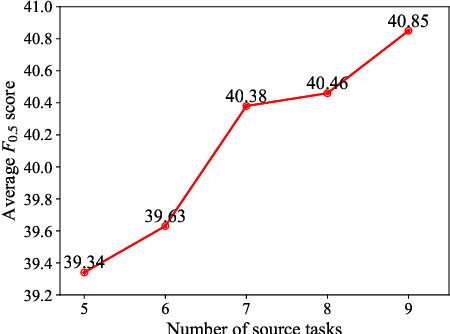
Most existing Grammatical Error Correction (GEC) methods based on sequence-to-sequence mainly focus on how to generate more pseudo data to obtain better performance. Few work addresses few-shot GEC domain adaptation. In this paper, we treat different GEC domains as different GEC tasks and propose to extend meta-learning to few-shot GEC domain adaptation without using any pseudo data. We exploit a set of data-rich source domains to learn the initialization of model parameters that facilitates fast adaptation on new resource-poor target domains. We adapt GEC model to the first language (L1) of the second language learner. To evaluate the proposed method, we use nine L1s as source domains and five L1s as target domains. Experiment results on the L1 GEC domain adaptation dataset demonstrate that the proposed approach outperforms the multi-task transfer learning baseline by 0.50 $F_{0.5}$ score on average and enables us to effectively adapt to a new L1 domain with only 200 parallel sentences.