 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting IPA-based Cross-lingual Text-to-speech
Paper and Code
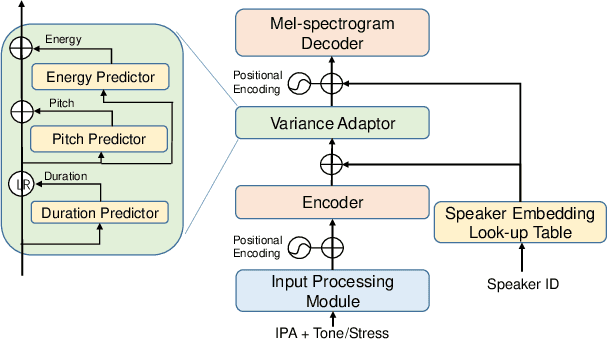
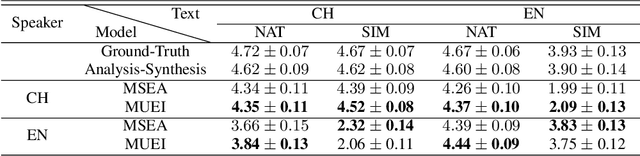
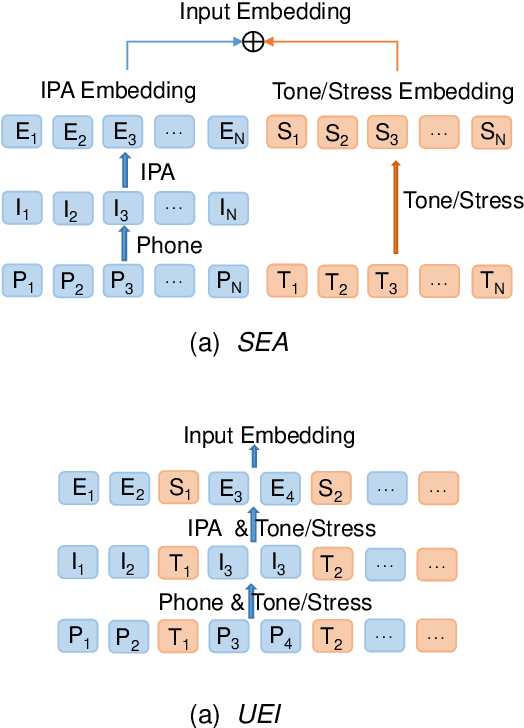
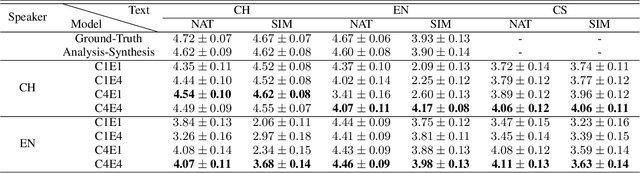
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.