 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascading Refinement Video Denoising with Uncertainty Adaptivity
Aug 05, 2024



Accurate alignment is crucial for video denoising. However, estimating alignment in noisy environments is challenging. This paper introduces a cascading refinement video denoising method that can refine alignment and restore images simultaneously. Better alignment enables restoration of more detailed information in each frame. Furthermore, better image quality leads to better alignment. This method has achieved SOTA performance by a large margin on the CRVD dataset. Simultaneously, aiming to deal with multi-level noise, an uncertainty map was created after each iteration. Because of this, redundant computation on the easily restored videos was avoided. By applying this method, the entire computation was reduced by 25% on average.
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
Aug 19, 2023
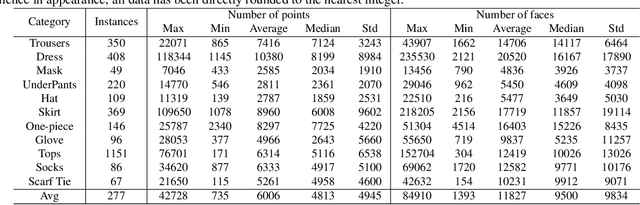


We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations. Our dataset consists of around 4400 models covering 11 categories annotated with clothes features, boundary lines, and keypoints. ClothesNet can be used to facilitate a variety of computer vision and robot interaction tasks. Using our dataset, we establish benchmark tasks for clothes perception, including classification, boundary line segmentation, and keypoint detection, and develop simulated clothes environments for robotic interaction tasks, including rearranging, folding, hanging, and dressing. We also demonstrate the efficacy of our ClothesNet in real-world experiments. Supplemental materials and dataset are available on our project webpage.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021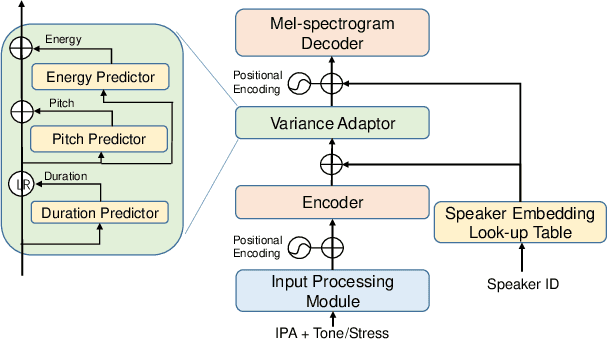
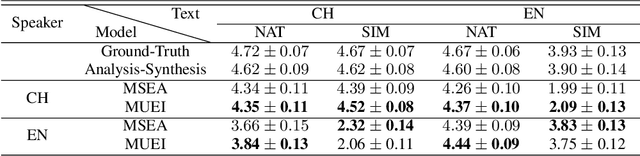
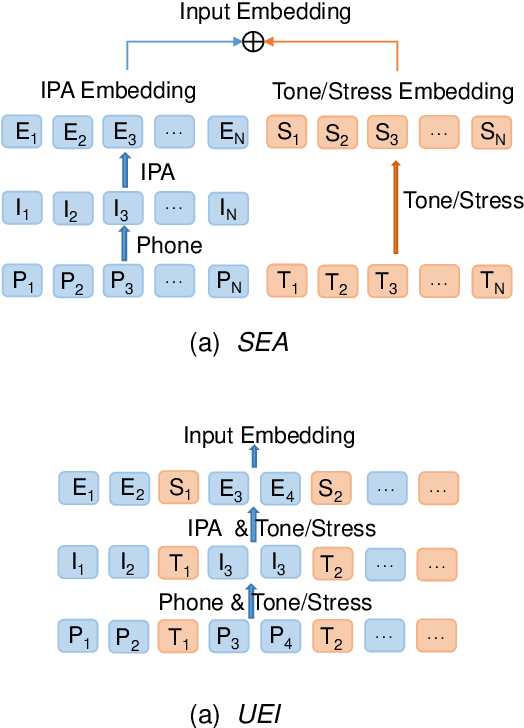
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Exploring Timbre Disentanglement in Non-Autoregressive Cross-Lingual Text-to-Speech
Oct 14, 2021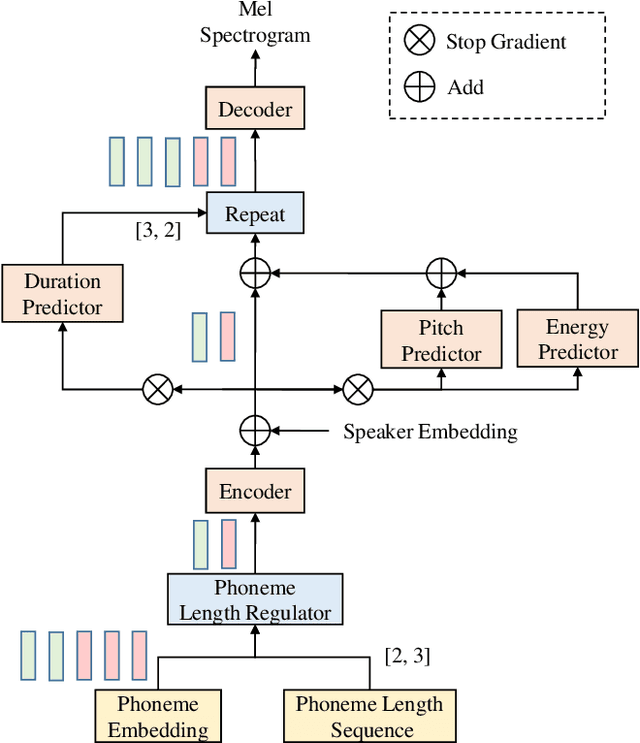
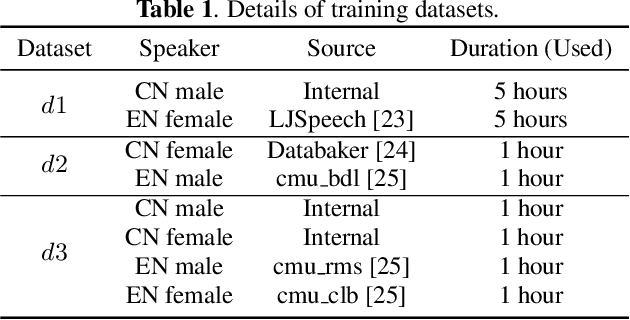

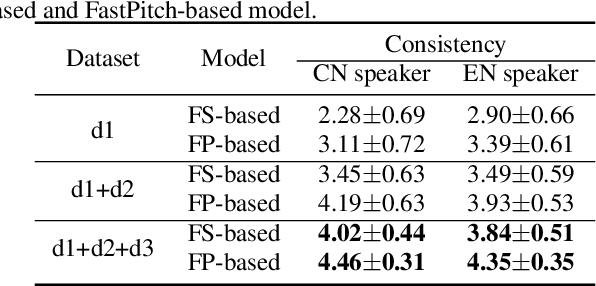
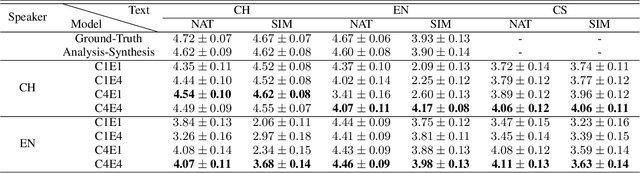
In this paper, we present a FastPitch-based non-autoregressive cross-lingual Text-to-Speech (TTS) model built with language independent input representation and monolingual force aligners. We propose a phoneme length regulator that solves the length mismatch problem between language-independent phonemes and monolingual alignment results. Our experiments show that (1) an increasing number of training speakers encourages non-autoregressive cross-lingual TTS model to disentangle speaker and language representations, and (2) variance adaptors of FastPitch model can help disentangle speaker identity from learned representations in cross-lingual TTS. The subjective evaluation shows that our proposed model is able to achieve decent speaker consistency and similarity. We further improve the naturalness of Mandarin-dominated mixed-lingual utterances by utilizing the controllability of our proposed model.
DeepBlindness: Fast Blindness Map Estimation and Blindness Type Classification for Outdoor Scene from Single Color Image
Nov 02, 2019
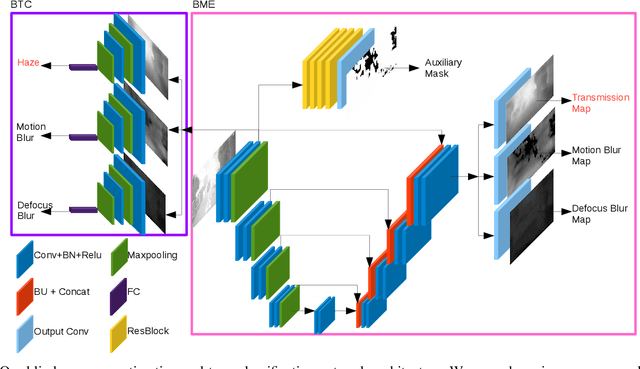

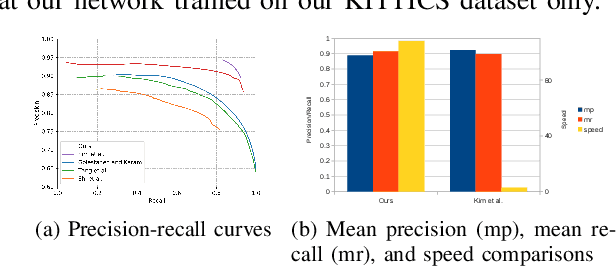
Outdoor vision robotic systems and autonomous cars suffer from many image-quality issues, particularly haze, defocus blur, and motion blur, which we will define generically as "blindness issues". These blindness issues may seriously affect the performance of robotic systems and could lead to unsafe decisions being made. However, existing solutions either focus on one type of blindness only or lack the ability to estimate the degree of blindness accurately. Besides, heavy computation is needed so that these solutions cannot run in real-time on practical systems. In this paper, we provide a method which could simultaneously detect the type of blindness and provide a blindness map indicating to what degree the vision is limited on a pixel-by-pixel basis. Both the blindness type and the estimate of per-pixel blindness are essential for tasks like deblur, dehaze, or the fail-safe functioning of robotic systems. We demonstrate the effectiveness of our approach on the KITTI and CUHK datasets where experiments show that our method outperforms other state-of-the-art approaches, achieving speeds of about 130 frames per second (fps).