 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Timbre Disentanglement in Non-Autoregressive Cross-Lingual Text-to-Speech
Paper and Code
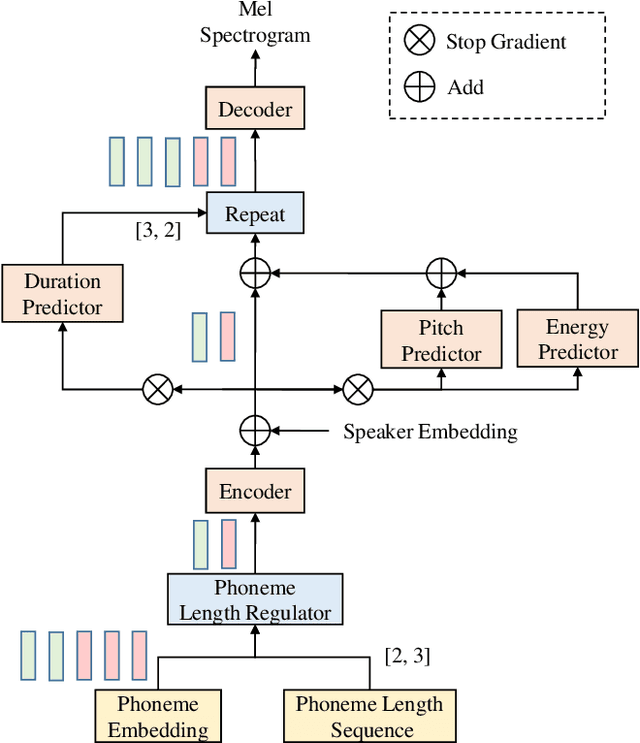
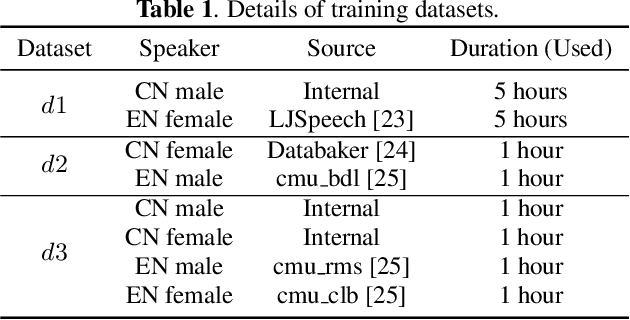

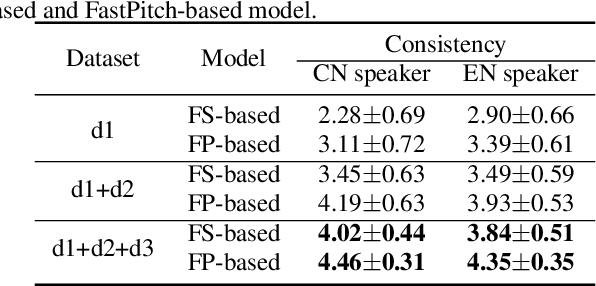
In this paper, we present a FastPitch-based non-autoregressive cross-lingual Text-to-Speech (TTS) model built with language independent input representation and monolingual force aligners. We propose a phoneme length regulator that solves the length mismatch problem between language-independent phonemes and monolingual alignment results. Our experiments show that (1) an increasing number of training speakers encourages non-autoregressive cross-lingual TTS model to disentangle speaker and language representations, and (2) variance adaptors of FastPitch model can help disentangle speaker identity from learned representations in cross-lingual TTS. The subjective evaluation shows that our proposed model is able to achieve decent speaker consistency and similarity. We further improve the naturalness of Mandarin-dominated mixed-lingual utterances by utilizing the controllability of our proposed model.