 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA serial dual-channel library occupancy detection system based on Faster RCNN
Jun 28, 2023



The phenomenon of seat occupancy in university libraries is a prevalent issue. However, existing solutions, such as software-based seat reservations and sensors-based occupancy detection, have proven to be inadequate in effectively addressing this problem. In this study, we propose a novel approach: a serial dual-channel object detection model based on Faster RCNN. Furthermore, we develop a user-friendly Web interface and mobile APP to create a computer vision-based platform for library seat occupancy detection. To construct our dataset, we combine real-world data collec-tion with UE5 virtual reality. The results of our tests also demonstrate that the utilization of per-sonalized virtual dataset significantly enhances the performance of the convolutional neural net-work (CNN) in dedicated scenarios. The serial dual-channel detection model comprises three es-sential steps. Firstly, we employ Faster RCNN algorithm to determine whether a seat is occupied by an individual. Subsequently, we utilize an object classification algorithm based on transfer learning, to classify and identify images of unoccupied seats. This eliminates the need for manual judgment regarding whether a person is suspected of occupying a seat. Lastly, the Web interface and APP provide seat information to librarians and students respectively, enabling comprehensive services. By leveraging deep learning methodologies, this research effectively addresses the issue of seat occupancy in library systems. It significantly enhances the accuracy of seat occupancy recognition, reduces the computational resources required for training CNNs, and greatly improves the effi-ciency of library seat management.
DeepBlindness: Fast Blindness Map Estimation and Blindness Type Classification for Outdoor Scene from Single Color Image
Nov 02, 2019
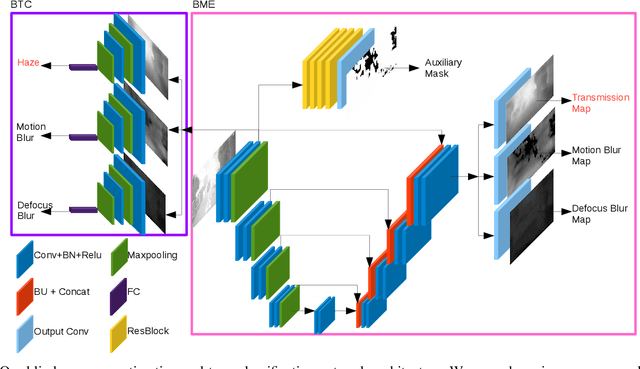

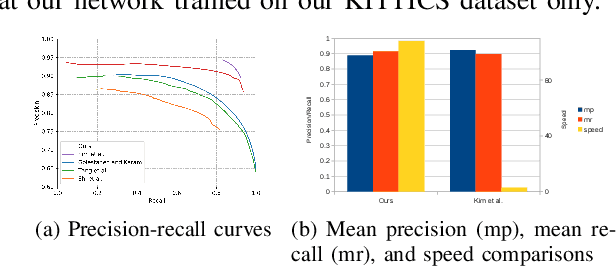
Outdoor vision robotic systems and autonomous cars suffer from many image-quality issues, particularly haze, defocus blur, and motion blur, which we will define generically as "blindness issues". These blindness issues may seriously affect the performance of robotic systems and could lead to unsafe decisions being made. However, existing solutions either focus on one type of blindness only or lack the ability to estimate the degree of blindness accurately. Besides, heavy computation is needed so that these solutions cannot run in real-time on practical systems. In this paper, we provide a method which could simultaneously detect the type of blindness and provide a blindness map indicating to what degree the vision is limited on a pixel-by-pixel basis. Both the blindness type and the estimate of per-pixel blindness are essential for tasks like deblur, dehaze, or the fail-safe functioning of robotic systems. We demonstrate the effectiveness of our approach on the KITTI and CUHK datasets where experiments show that our method outperforms other state-of-the-art approaches, achieving speeds of about 130 frames per second (fps).
Downhole Track Detection via Multiscale Conditional Generative Adversarial Nets
Apr 17, 2019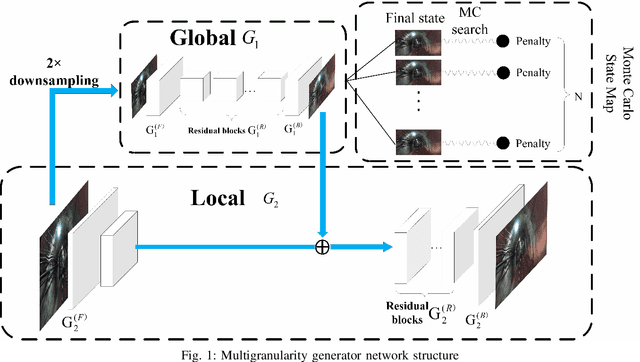
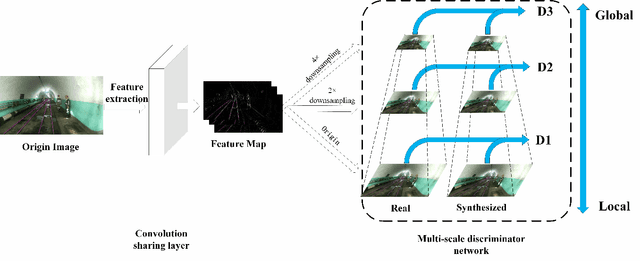

Frequent mine disasters cause a large number of casualties and property losses. Autonomous driving is a fundamental measure for solving this problem, and track detection is one of the key technologies for computer vision to achieve downhole automatic driving. The track detection result based on the traditional convolutional neural network (CNN) algorithm lacks the detailed and unique description of the object and relies too much on visual postprocessing technology. Therefore, this paper proposes a track detection algorithm based on a multiscale conditional generative adversarial network (CGAN). The generator is decomposed into global and local parts using a multigranularity structure in the generator network. A multiscale shared convolution structure is adopted in the discriminator network to further supervise training the generator. Finally, the Monte Carlo search technique is introduced to search the intermediate state of the generator, and the result is sent to the discriminator for comparison. Compared with the existing work, our model achieved 82.43\% pixel accuracy and an average intersection-over-union (IOU) of 0.6218, and the detection of the track reached 95.01\% accuracy in the downhole roadway scene test set.