 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Layer Importance in Layer-wise Sparsity: An Inter-Layer Perturbation-Absorption Perspective
Jun 13, 2026The considerable layer-wise redundancy in large language models (LLMs) has established non-uniform sparsity allocation across layers as the standard pruning approach for efficient compression. Existing layer-wise allocation methods that estimate allocation strategy from local signals such as activation outliers or weight spectra mainly derive from local layer importance, whereas the final post-pruning performance is also influenced by the network's subsequent compensatory capacity. In this paper, we directly characterize this property through controlled perturbation experiments. We make the following empirical findings. First, layers exhibit highly heterogeneous responses to pruning-scale perturbations. In most cases, early layers amplify perturbations, while middle and late layers actively absorb them, with relative L2 drift decreasing monotonically across depth and direction realigning toward the unperturbed hidden-state trajectory. Second, absorption is a large-perturbation phenomenon. Under small perturbations the network exhibits amplification across all layers, and the transition to absorption occurs smoothly as perturbation magnitude grows to pruning scale. This enriches the linearized accumulation theory underlying related works. Building on these findings, we define an absorption coefficient per layer and propose absorption-aware correction, an orthogonal augmentation that improves OWL and AlphaPruning by reducing perplexity by 7.13% and boosting zero-shot accuracy by 1.02% across multiple model families at 70% sparsity.
HybridThinker: Efficient Chain-of-Thought Reasoning via Compressed Memory and Transient Thought Steps
Jun 02, 2026Extended chain-of-thought (CoT) traces improve LLM reasoning but incur substantial computational and memory costs. While existing CoT compression methods mitigate this by condensing thought steps into compact representations via memory tokens and retaining only these representations at inference time, the loss of fine-grained information makes subsequent steps more error-prone. To alleviate this, we propose \textbf{HybridThinker}, where in addition to preserved these representations, thought steps are also temporarily retained to provide fine-grained details. However, we observe that naively keeping thought steps accessible to subsequent steps \emph{during training} lets the model bypass memory tokens by retrieving information directly from these steps, leaving the model's ability to compress and retrieve information through memory tokens insufficiently trained. We therefore introduce a hybrid training scheme, in which only some thought steps are directly accessible through attention to subsequent steps, while the other thought steps are masked, forcing the model to use memory tokens for compression and retrieval. Across 4 reasoning benchmarks, HybridThinker matches the uncompressed baseline, advancing the state of the art in CoT compression by 5.8 points on average accuracy with similar inference time. Ablation studies confirm that both temporary thought-step retention and the hybrid training scheme contribute to these gains.
THRD: A Training-Free Multi-Turn Defense Framework for Jailbreak Attacks on Large Language Models
Jun 01, 2026Multi-turn jailbreak attacks pose a growing threat to LLMs by exploiting conversational dynamics such as gradual escalation and cross-turn coordination. Existing defenses either rely on costly retraining -- often degrading model utility -- or apply single-turn analysis independently at each turn, failing to capture how risk accumulates along interaction trajectories. We observe that safety behavior in multi-turn interaction is trajectory-dependent: dialogue history continuously reshapes the model's conditioning context, making it insufficient to evaluate each turn in isolation. Motivated by this insight, we present THRD, the first training-free framework that explicitly models temporal risk accumulation for multi-turn jailbreak defense. THRD integrates four modules: a Turn-level Risk Assessor (TRA) for instantaneous risk estimation, a Historical Context Analyzer (HCA) for cross-turn intent escalation detection, a Response Evaluator (RE) for identifying facilitative outputs, and a Decision Module that combines these signals through a time-evolving scoring mechanism with attenuation-based modulation and trend-aware adjustment. Experiments against state-of-the-art multi-turn attacks -- including tree-search-based and multi-agent collaborative methods -- across two target models show that THRD reduces ASR to 0.2--4.0% while preserving model utility within 1.5% degradation on MMLU and GSM8K. Ablation studies confirm non-redundant module contributions and stable cross-architecture generalization. Analysis of first rejection triggers reveals that over 70% of multi-turn attacks require Turn~2 or later to detect, validating the necessity of explicit temporal aggregation.
RankNAS: Efficient Neural Architecture Search by Pairwise Ranking
Sep 17, 2021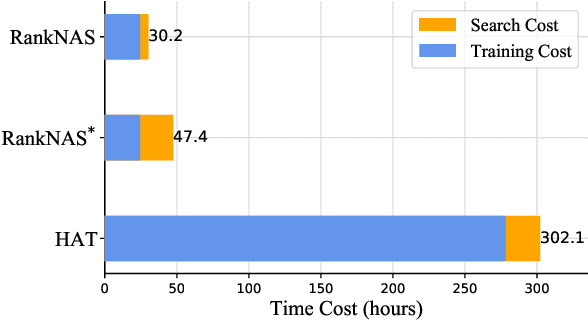

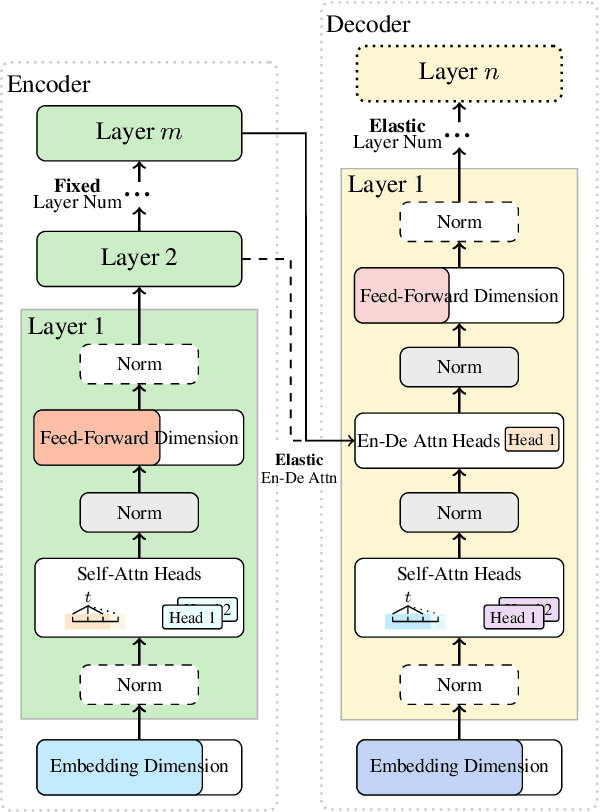
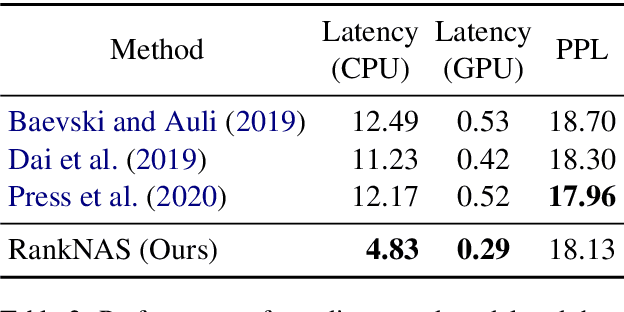
This paper addresses the efficiency challenge of Neural Architecture Search (NAS) by formulating the task as a ranking problem. Previous methods require numerous training examples to estimate the accurate performance of architectures, although the actual goal is to find the distinction between "good" and "bad" candidates. Here we do not resort to performance predictors. Instead, we propose a performance ranking method (RankNAS) via pairwise ranking. It enables efficient architecture search using much fewer training examples. Moreover, we develop an architecture selection method to prune the search space and concentrate on more promising candidates. Extensive experiments on machine translation and language modeling tasks show that RankNAS can design high-performance architectures while being orders of magnitude faster than state-of-the-art NAS systems.
Layer-Wise Multi-View Learning for Neural Machine Translation
Nov 03, 2020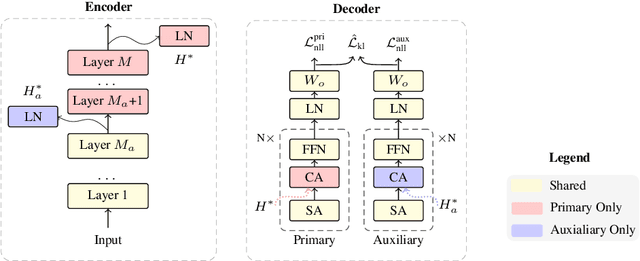
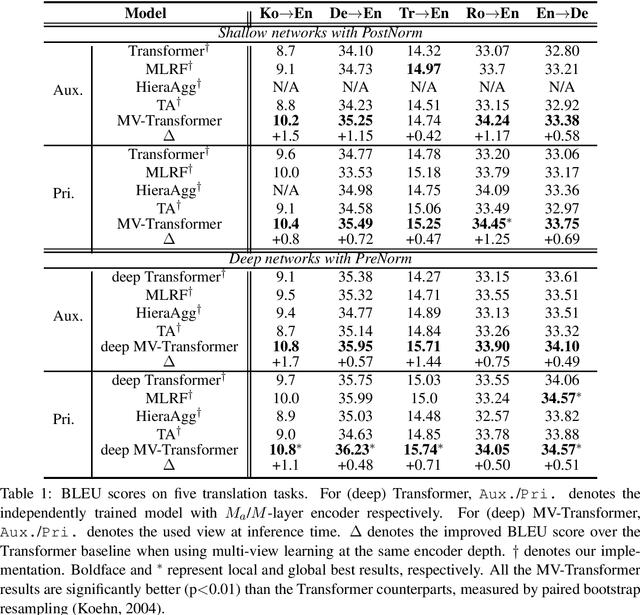

Traditional neural machine translation is limited to the topmost encoder layer's context representation and cannot directly perceive the lower encoder layers. Existing solutions usually rely on the adjustment of network architecture, making the calculation more complicated or introducing additional structural restrictions. In this work, we propose layer-wise multi-view learning to solve this problem, circumventing the necessity to change the model structure. We regard each encoder layer's off-the-shelf output, a by-product in layer-by-layer encoding, as the redundant view for the input sentence. In this way, in addition to the topmost encoder layer (referred to as the primary view), we also incorporate an intermediate encoder layer as the auxiliary view. We feed the two views to a partially shared decoder to maintain independent prediction. Consistency regularization based on KL divergence is used to encourage the two views to learn from each other. Extensive experimental results on five translation tasks show that our approach yields stable improvements over multiple strong baselines. As another bonus, our method is agnostic to network architectures and can maintain the same inference speed as the original model.
Learning Architectures from an Extended Search Space for Language Modeling
Jun 05, 2020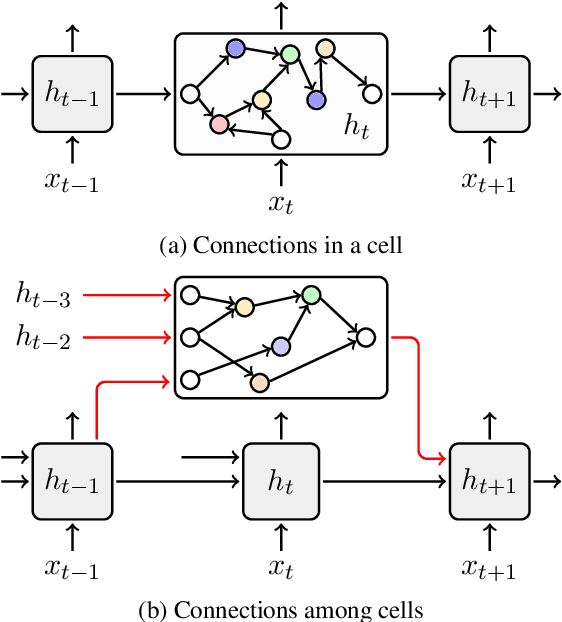


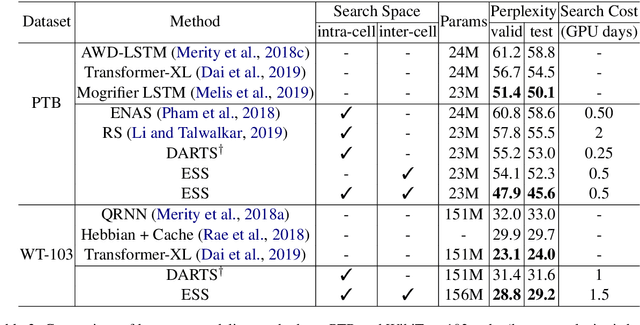
Neural architecture search (NAS) has advanced significantly in recent years but most NAS systems restrict search to learning architectures of a recurrent or convolutional cell. In this paper, we extend the search space of NAS. In particular, we present a general approach to learn both intra-cell and inter-cell architectures (call it ESS). For a better search result, we design a joint learning method to perform intra-cell and inter-cell NAS simultaneously. We implement our model in a differentiable architecture search system. For recurrent neural language modeling, it outperforms a strong baseline significantly on the PTB and WikiText data, with a new state-of-the-art on PTB. Moreover, the learned architectures show good transferability to other systems. E.g., they improve state-of-the-art systems on the CoNLL and WNUT named entity recognition (NER) tasks and CoNLL chunking task, indicating a promising line of research on large-scale pre-learned architectures.
Does Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation
May 17, 2020
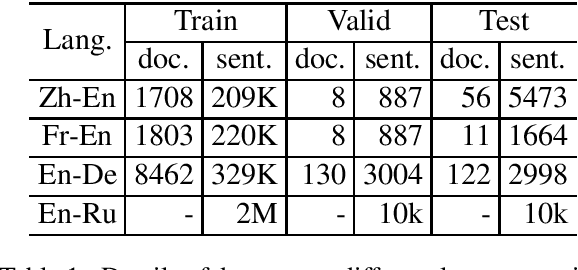

In encoder-decoder neural models, multiple encoders are in general used to represent the contextual information in addition to the individual sentence. In this paper, we investigate multi-encoder approaches in documentlevel neural machine translation (NMT). Surprisingly, we find that the context encoder does not only encode the surrounding sentences but also behaves as a noise generator. This makes us rethink the real benefits of multi-encoder in context-aware translation - some of the improvements come from robust training. We compare several methods that introduce noise and/or well-tuned dropout setup into the training of these encoders. Experimental results show that noisy training plays an important role in multi-encoder-based NMT, especially when the training data is small. Also, we establish a new state-of-the-art on IWSLT Fr-En task by careful use of noise generation and dropout methods.
Single Channel Speech Enhancement Using Temporal Convolutional Recurrent Neural Networks
Feb 02, 2020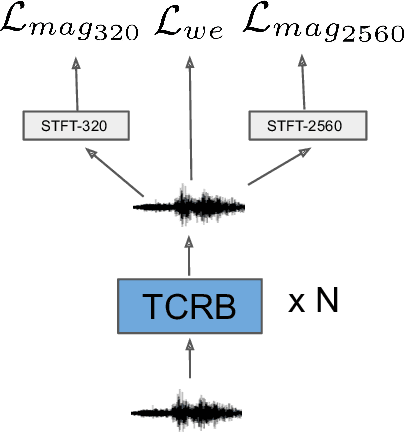
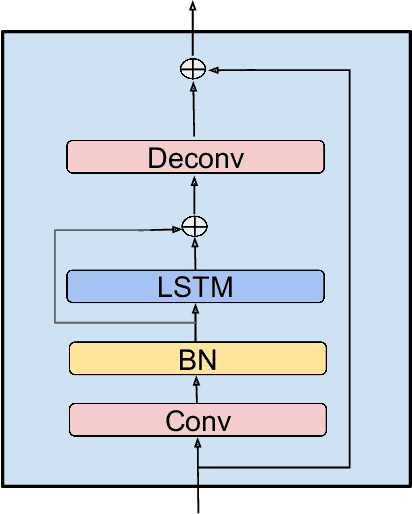

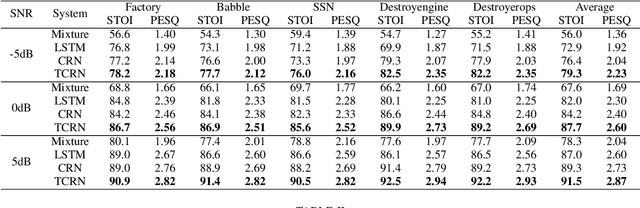
In recent decades, neural network based methods have significantly improved the performace of speech enhancement. Most of them estimate time-frequency (T-F) representation of target speech directly or indirectly, then resynthesize waveform using the estimated T-F representation. In this work, we proposed the temporal convolutional recurrent network (TCRN), an end-to-end model that directly map noisy waveform to clean waveform. The TCRN, which is combined convolution and recurrent neural network, is able to efficiently and effectively leverage short-term ang long-term information. Futuremore, we present the architecture that repeatedly downsample and upsample speech during forward propagation. We show that our model is able to improve the performance of model, compared with existing convolutional recurrent networks. Futuremore, We present several key techniques to stabilize the training process. The experimental results show that our model consistently outperforms existing speech enhancement approaches, in terms of speech intelligibility and quality.
Learning Deep Transformer Models for Machine Translation
Jun 05, 2019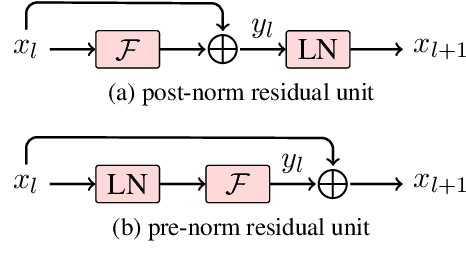
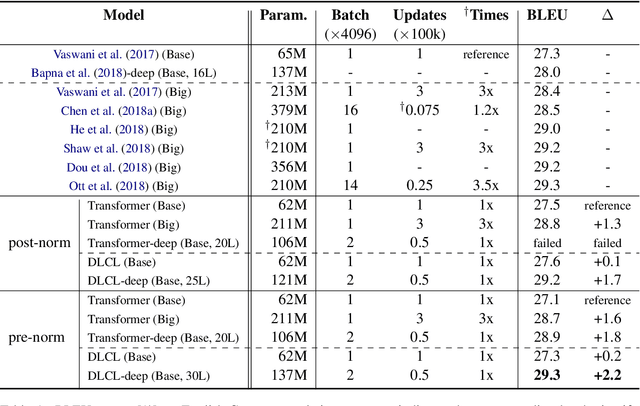

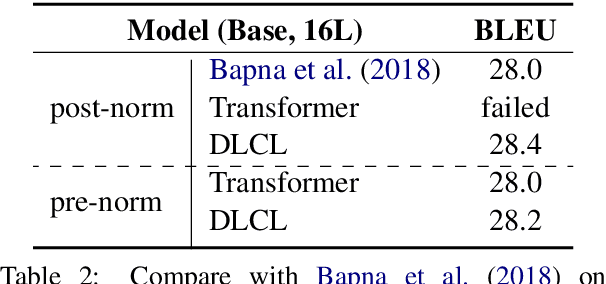
Transformer is the state-of-the-art model in recent machine translation evaluations. Two strands of research are promising to improve models of this kind: the first uses wide networks (a.k.a. Transformer-Big) and has been the de facto standard for the development of the Transformer system, and the other uses deeper language representation but faces the difficulty arising from learning deep networks. Here, we continue the line of research on the latter. We claim that a truly deep Transformer model can surpass the Transformer-Big counterpart by 1) proper use of layer normalization and 2) a novel way of passing the combination of previous layers to the next. On WMT'16 English- German, NIST OpenMT'12 Chinese-English and larger WMT'18 Chinese-English tasks, our deep system (30/25-layer encoder) outperforms the shallow Transformer-Big/Base baseline (6-layer encoder) by 0.4-2.4 BLEU points. As another bonus, the deep model is 1.6X smaller in size and 3X faster in training than Transformer-Big.
Downhole Track Detection via Multiscale Conditional Generative Adversarial Nets
Apr 17, 2019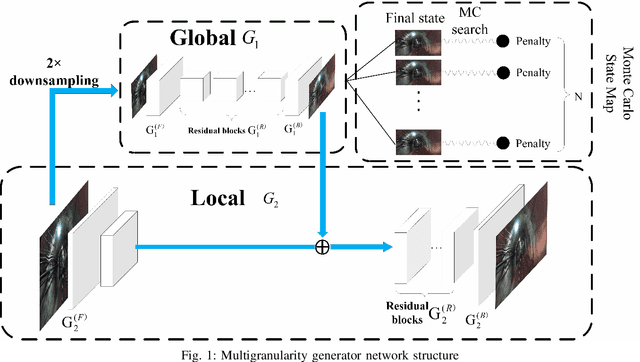
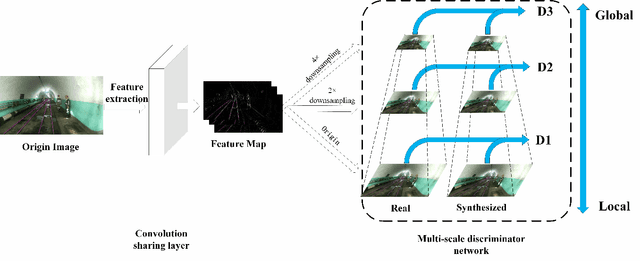
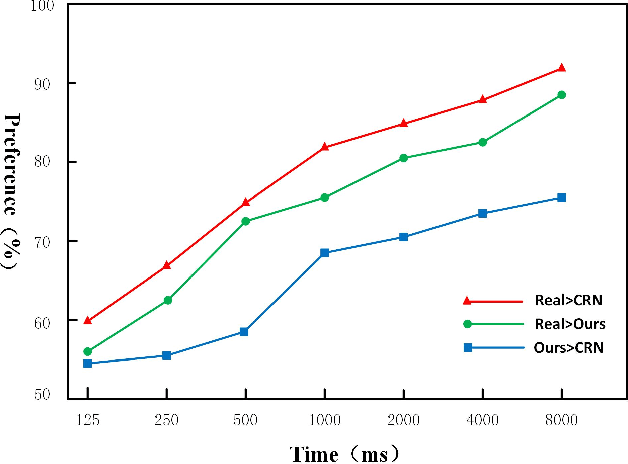

Frequent mine disasters cause a large number of casualties and property losses. Autonomous driving is a fundamental measure for solving this problem, and track detection is one of the key technologies for computer vision to achieve downhole automatic driving. The track detection result based on the traditional convolutional neural network (CNN) algorithm lacks the detailed and unique description of the object and relies too much on visual postprocessing technology. Therefore, this paper proposes a track detection algorithm based on a multiscale conditional generative adversarial network (CGAN). The generator is decomposed into global and local parts using a multigranularity structure in the generator network. A multiscale shared convolution structure is adopted in the discriminator network to further supervise training the generator. Finally, the Monte Carlo search technique is introduced to search the intermediate state of the generator, and the result is sent to the discriminator for comparison. Compared with the existing work, our model achieved 82.43\% pixel accuracy and an average intersection-over-union (IOU) of 0.6218, and the detection of the track reached 95.01\% accuracy in the downhole roadway scene test set.